 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCalibRefine: Deep Learning-Based Online Automatic Targetless LiDAR-Camera Calibration with Iterative and Attention-Driven Post-Refinement
Feb 26, 2025Accurate multi-sensor calibration is essential for deploying robust perception systems in applications such as autonomous driving, robotics, and intelligent transportation. Existing LiDAR-camera calibration methods often rely on manually placed targets, preliminary parameter estimates, or intensive data preprocessing, limiting their scalability and adaptability in real-world settings. In this work, we propose a fully automatic, targetless, and online calibration framework, CalibRefine, which directly processes raw LiDAR point clouds and camera images. Our approach is divided into four stages: (1) a Common Feature Discriminator that trains on automatically detected objects--using relative positions, appearance embeddings, and semantic classes--to generate reliable LiDAR-camera correspondences, (2) a coarse homography-based calibration, (3) an iterative refinement to incrementally improve alignment as additional data frames become available, and (4) an attention-based refinement that addresses non-planar distortions by leveraging a Vision Transformer and cross-attention mechanisms. Through extensive experiments on two urban traffic datasets, we show that CalibRefine delivers high-precision calibration results with minimal human involvement, outperforming state-of-the-art targetless methods and remaining competitive with, or surpassing, manually tuned baselines. Our findings highlight how robust object-level feature matching, together with iterative and self-supervised attention-based adjustments, enables consistent sensor fusion in complex, real-world conditions without requiring ground-truth calibration matrices or elaborate data preprocessing.
Smart Camera Parking System With Auto Parking Spot Detection
Jul 07, 2024Given the rising urban population and the consequential rise in traffic congestion, the implementation of smart parking systems has emerged as a critical matter of concern. Smart parking solutions use cameras, sensors, and algorithms like computer vision to find available parking spaces. This method improves parking place recognition, reduces traffic and pollution, and optimizes travel time. In recent years, computer vision-based approaches have been widely used. However, most existing studies rely on manually labeled parking spots, which has implications for the cost and practicality of implementation. To solve this problem, we propose a novel approach PakLoc, which automatically localize parking spots. Furthermore, we present the PakSke module, which automatically adjust the rotation and the size of detected bounding box. The efficacy of our proposed methodology on the PKLot dataset results in a significant reduction in human labor of 94.25\%. Another fundamental aspect of a smart parking system is its capacity to accurately determine and indicate the state of parking spots within a parking lot. The conventional approach involves employing classification techniques to forecast the condition of parking spots based on the bounding boxes derived from manually labeled grids. In this study, we provide a novel approach called PakSta for identifying the state of parking spots automatically. Our method utilizes object detector from PakLoc to simultaneously determine the occupancy status of all parking lots within a video frame. Our proposed method PakSta exhibits a competitive performance on the PKLot dataset when compared to other classification methods.
Semantic Segmentation for Real-World and Synthetic Vehicle's Forward-Facing Camera Images
Jul 07, 2024In this paper, we present the submission to the 5th Annual Smoky Mountains Computational Sciences Data Challenge, Challenge 3. This is the solution for semantic segmentation problem in both real-world and synthetic images from a vehicle s forward-facing camera. We concentrate in building a robust model which performs well across various domains of different outdoor situations such as sunny, snowy, rainy, etc. In particular, our method is developed with two main directions: model development and domain adaptation. In model development, we use the High Resolution Network (HRNet) as the baseline. Then, this baseline s result is processed by two coarse-to-fine models: Object-Contextual Representations (OCR) and Hierarchical Multi-scale Attention (HMA) to get the better robust feature. For domain adaption, we implement the Domain-Based Batch Normalization (DNB) to reduce the distribution shift from diverse domains. Our proposed method yield 81.259 mean intersection-over-union (mIoU) in validation set. This paper studies the effectiveness of employing real-world and synthetic data to handle the domain adaptation in semantic segmentation problem.
CompeteSMoE -- Effective Training of Sparse Mixture of Experts via Competition
Feb 04, 2024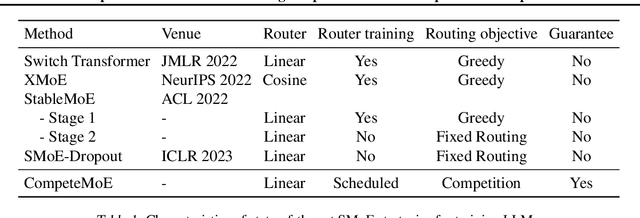
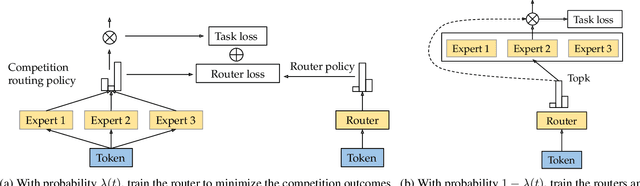
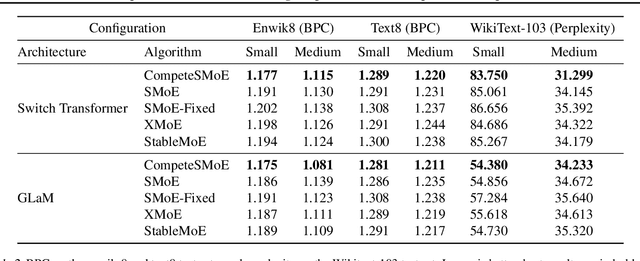
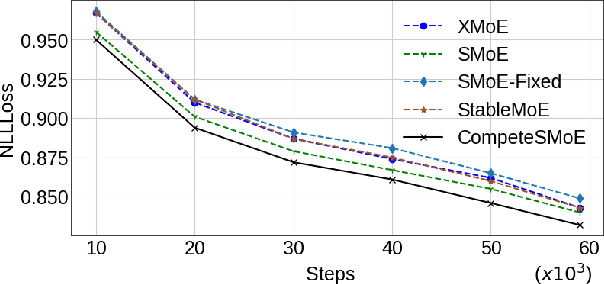
Sparse mixture of experts (SMoE) offers an appealing solution to scale up the model complexity beyond the mean of increasing the network's depth or width. However, effective training of SMoE has proven to be challenging due to the representation collapse issue, which causes parameter redundancy and limited representation potentials. In this work, we propose a competition mechanism to address this fundamental challenge of representation collapse. By routing inputs only to experts with the highest neural response, we show that, under mild assumptions, competition enjoys the same convergence rate as the optimal estimator. We further propose CompeteSMoE, an effective and efficient algorithm to train large language models by deploying a simple router that predicts the competition outcomes. Consequently, CompeteSMoE enjoys strong performance gains from the competition routing policy while having low computation overheads. Our extensive empirical evaluations on two transformer architectures and a wide range of tasks demonstrate the efficacy, robustness, and scalability of CompeteSMoE compared to state-of-the-art SMoE strategies.
Improving RF-DNA Fingerprinting Performance in an Indoor Multipath Environment Using Semi-Supervised Learning
Apr 02, 2023The number of Internet of Things (IoT) deployments is expected to reach 75.4 billion by 2025. Roughly 70% of all IoT devices employ weak or no encryption; thus, putting them and their connected infrastructure at risk of attack by devices that are wrongly authenticated or not authenticated at all. A physical layer security approach -- known as Specific Emitter Identification (SEI) -- has been proposed and is being pursued as a viable IoT security mechanism. SEI is advantageous because it is a passive technique that exploits inherent and distinct features that are unintentionally added to the signal by the IoT Radio Frequency (RF) front-end. SEI's passive exploitation of unintentional signal features removes any need to modify the IoT device, which makes it ideal for existing and future IoT deployments. Despite the amount of SEI research conducted, some challenges must be addressed to make SEI a viable IoT security approach. One challenge is the extraction of SEI features from signals collected under multipath fading conditions. Multipath corrupts the inherent SEI features that are used to discriminate one IoT device from another; thus, degrading authentication performance and increasing the chance of attack. This work presents two semi-supervised Deep Learning (DL) equalization approaches and compares their performance with the current state of the art. The two approaches are the Conditional Generative Adversarial Network (CGAN) and Joint Convolutional Auto-Encoder and Convolutional Neural Network (JCAECNN). Both approaches learn the channel distribution to enable multipath correction while simultaneously preserving the SEI exploited features. CGAN and JCAECNN performance is assessed using a Rayleigh fading channel under degrading SNR, up to thirty-two IoT devices, and two publicly available signal sets. The JCAECNN improves SEI performance by 10% beyond that of the current state of the art.