 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEigenvectors of Experts are Training-free Non-collapsing Routers
May 29, 2026Sparse Mixture of Experts (SMoE) architectures improve the training efficiency of Large Language Models (LLMs) by routing input tokens to a selected subset of specialized experts. Despite their remarkable success, both training and inference in SMoE models suffer from the expert collapse issue (Chi et al., 2022), which degrades model performance. Prior studies primarily focus on improving the router; however, such methods rely on training from scratch or fine-tuning, which requires high computational and data-processing costs. Furthermore, we demonstrate that, despite these efforts, the issue persists when advancing well-pretrained SMoE models, as evidenced by both theoretical and empirical results. To fill that gap, we analyze the advanced SMoE models and observe that the eigenvectors of expert weight matrices encode rich semantic information, pointing to an effective alternative to conventional routing strategies. Building on this insight, we propose Singular Value Decomposition SMoE (SSMoE), a novel and training-free framework that leverages spectral properties of the expert weights to address the collapse issue and enhance model performance. Extensive experiments across diverse language and vision tasks, under both clean and corrupt data settings, demonstrate the strong generalization and robustness of SSMoE. Our findings highlight how a deeper understanding of model internals can guide the development of more effective SMoE architectures. Our implementation is publicly available at https://github.com/giangdip2410/SSMoE.
* 24 pages
Do Domain-specific Experts exist in MoE-based LLMs?
Apr 07, 2026In the era of Large Language Models (LLMs), the Mixture of Experts (MoE) architecture has emerged as an effective approach for training extremely large models with improved computational efficiency. This success builds upon extensive prior research aimed at enhancing expert specialization in MoE-based LLMs. However, the nature of such specializations and how they can be systematically interpreted remain open research challenges. In this work, we investigate this gap by posing a fundamental question: \textit{Do domain-specific experts exist in MoE-based LLMs?} To answer the question, we evaluate ten advanced MoE-based LLMs ranging from 3.8B to 120B parameters and provide empirical evidence for the existence of domain-specific experts. Building on this finding, we propose \textbf{Domain Steering Mixture of Experts (DSMoE)}, a training-free framework that introduces zero additional inference cost and outperforms both well-trained MoE-based LLMs and strong baselines, including Supervised Fine-Tuning (SFT). Experiments on four advanced open-source MoE-based LLMs across both target and non-target domains demonstrate that our method achieves strong performance and robust generalization without increasing inference cost or requiring additional retraining. Our implementation is publicly available at https://github.com/giangdip2410/Domain-specific-Experts.
S2MoE: Robust Sparse Mixture of Experts via Stochastic Learning
Mar 29, 2025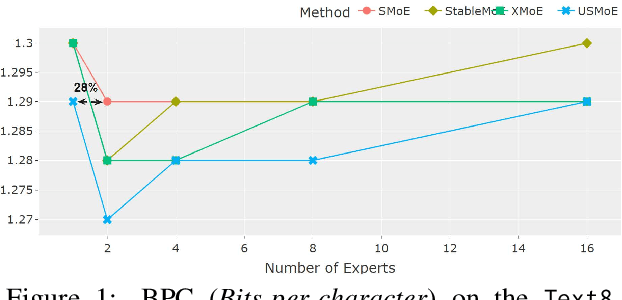
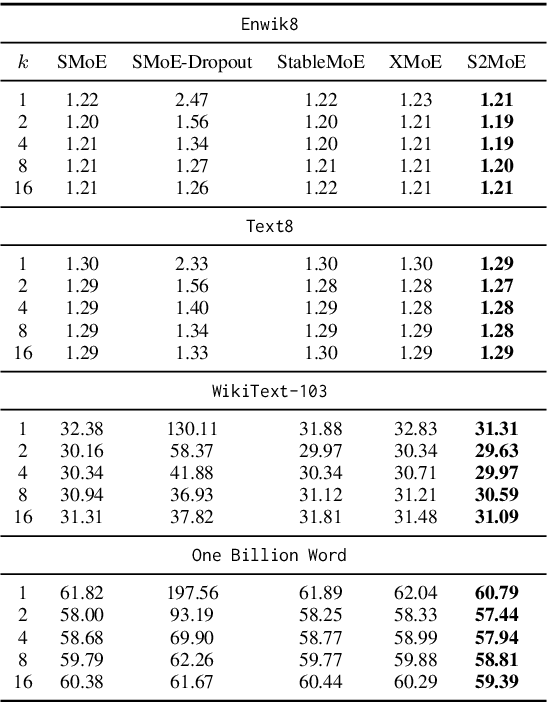
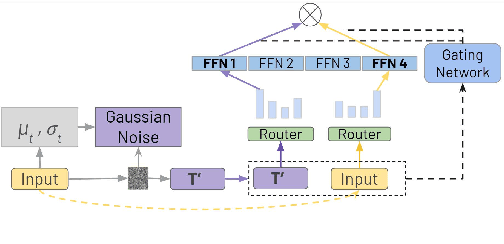
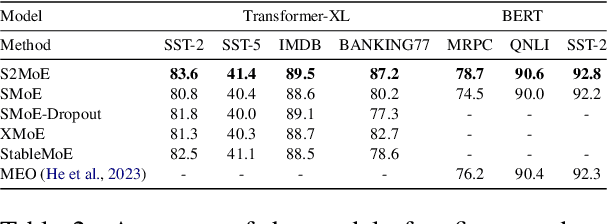
Sparse Mixture of Experts (SMoE) enables efficient training of large language models by routing input tokens to a select number of experts. However, training SMoE remains challenging due to the issue of representation collapse. Recent studies have focused on improving the router to mitigate this problem, but existing approaches face two key limitations: (1) expert embeddings are significantly smaller than the model's dimension, contributing to representation collapse, and (2) routing each input to the Top-K experts can cause them to learn overly similar features. In this work, we propose a novel approach called Robust Sparse Mixture of Experts via Stochastic Learning (S2MoE), which is a mixture of experts designed to learn from both deterministic and non-deterministic inputs via Learning under Uncertainty. Extensive experiments across various tasks demonstrate that S2MoE achieves performance comparable to other routing methods while reducing computational inference costs by 28%.
Sparse Mixture of Experts as Unified Competitive Learning
Mar 29, 2025Sparse Mixture of Experts (SMoE) improves the efficiency of large language model training by directing input tokens to a subset of experts. Despite its success in generation tasks, its generalization ability remains an open question. In this paper, we demonstrate that current SMoEs, which fall into two categories: (1) Token Choice ;and (2) Expert Choice, struggle with tasks such as the Massive Text Embedding Benchmark (MTEB). By analyzing their mechanism through the lens of competitive learning, our study finds that the Token Choice approach may overly focus on irrelevant experts, while the Expert Choice approach risks discarding important tokens, potentially affecting performance. Motivated by this analysis, we propose Unified Competitive Learning SMoE (USMoE), a novel and efficient framework designed to improve the performance of existing SMoEs in both scenarios: with and without training. Extensive experiments across various tasks show that USMoE achieves up to a 10% improvement over traditional approaches or reduces computational inference costs by 14% while maintaining strong performance.
On the effectiveness of discrete representations in sparse mixture of experts
Nov 28, 2024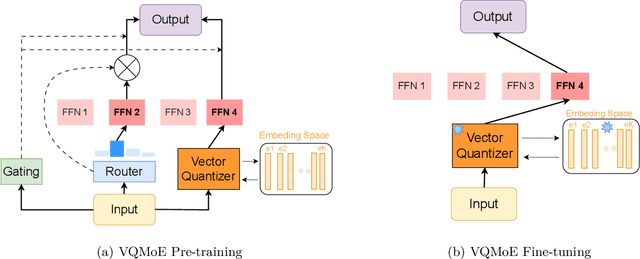
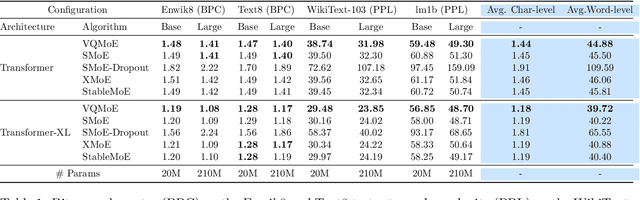
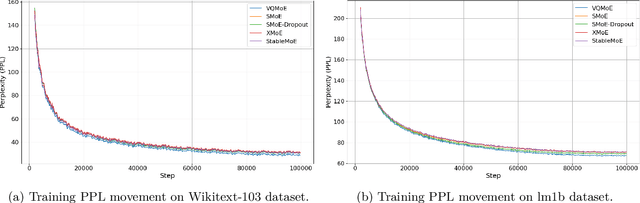
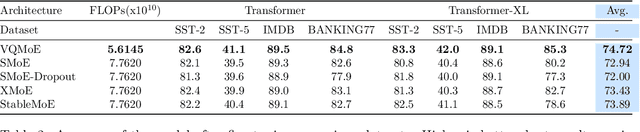
Sparse mixture of experts (SMoE) is an effective solution for scaling up model capacity without increasing the computational costs. A crucial component of SMoE is the router, responsible for directing the input to relevant experts; however, it also presents a major weakness, leading to routing inconsistencies and representation collapse issues. Instead of fixing the router like previous works, we propose an alternative that assigns experts to input via indirection, which employs the discrete representation of input that points to the expert. The discrete representations are learnt via vector quantization, resulting in a new architecture dubbed Vector-Quantized Mixture of Experts (VQMoE). We provide theoretical support and empirical evidence demonstrating the VQMoE's ability to overcome the challenges present in traditional routers. Through extensive evaluations on both large language models and vision tasks for pre-training and fine-tuning, we show that VQMoE achieves a 28% improvement in robustness compared to other SMoE routing methods, while maintaining strong performance in fine-tuning tasks.
SimSMoE: Solving Representational Collapse via Similarity Measure
Jun 22, 2024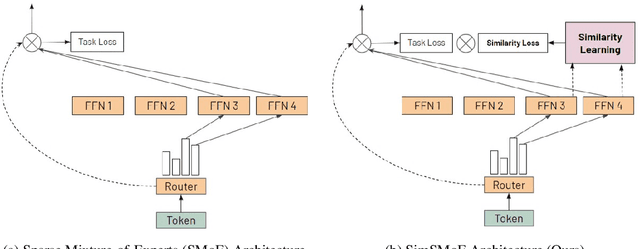
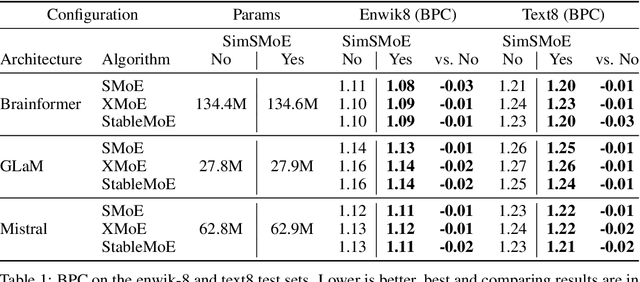
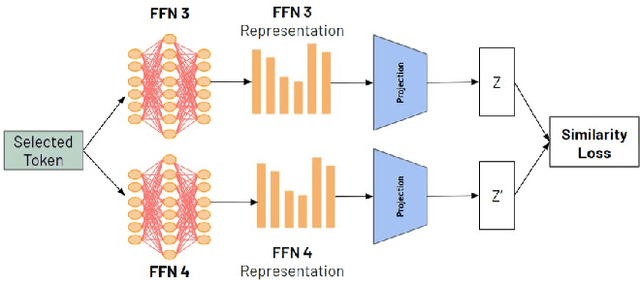
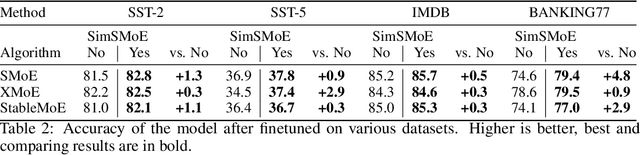
Sparse mixture of experts (SMoE) have emerged as an effective approach for scaling large language models while keeping a constant computational cost. Regardless of several notable successes of SMoE, effective training such architecture remains elusive due to the representation collapse problem, which in turn harms model performance and causes parameter redundancy. In this work, we present Similarity-based Sparse Mixture of Experts (SimSMoE), a novel similarity of neural network algorithm, that guarantees a solution to address the representation collapse issue between experts given a fixed FLOPs budget. We conduct extensive empirical evaluations on three large language models for both Pre-training and Fine-tuning tasks to illustrate the efficacy, robustness, and scalability of our method. The results demonstrate that SimSMoE significantly enhances existing routing policy and outperforms other SMoE training methods in performance for the tasks.
CompeteSMoE -- Effective Training of Sparse Mixture of Experts via Competition
Feb 04, 2024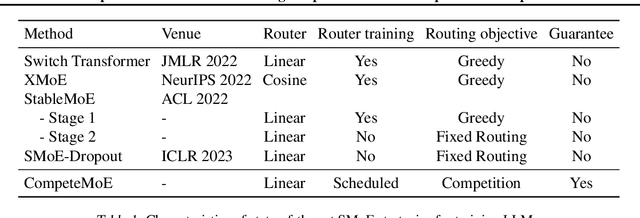
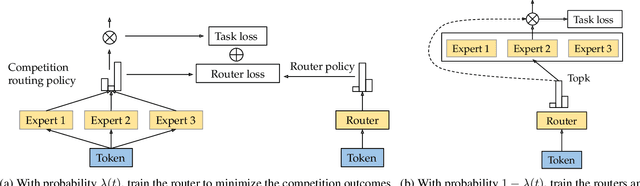
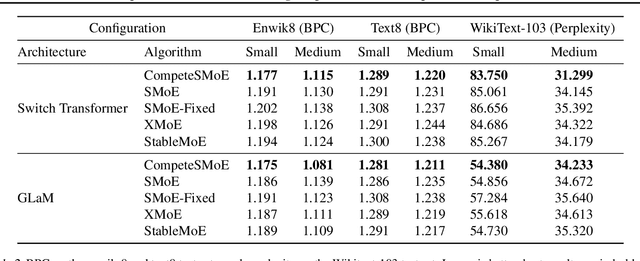
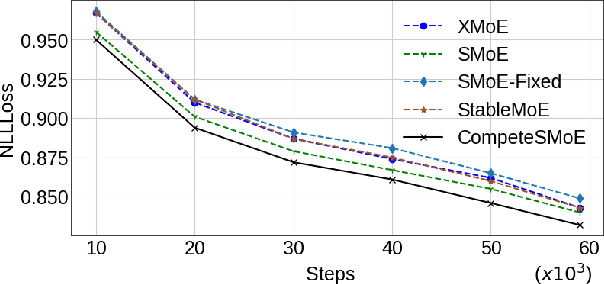
Sparse mixture of experts (SMoE) offers an appealing solution to scale up the model complexity beyond the mean of increasing the network's depth or width. However, effective training of SMoE has proven to be challenging due to the representation collapse issue, which causes parameter redundancy and limited representation potentials. In this work, we propose a competition mechanism to address this fundamental challenge of representation collapse. By routing inputs only to experts with the highest neural response, we show that, under mild assumptions, competition enjoys the same convergence rate as the optimal estimator. We further propose CompeteSMoE, an effective and efficient algorithm to train large language models by deploying a simple router that predicts the competition outcomes. Consequently, CompeteSMoE enjoys strong performance gains from the competition routing policy while having low computation overheads. Our extensive empirical evaluations on two transformer architectures and a wide range of tasks demonstrate the efficacy, robustness, and scalability of CompeteSMoE compared to state-of-the-art SMoE strategies.
HyperRouter: Towards Efficient Training and Inference of Sparse Mixture of Experts
Dec 12, 2023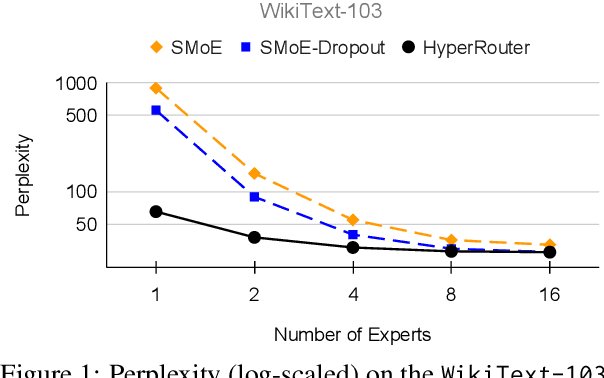
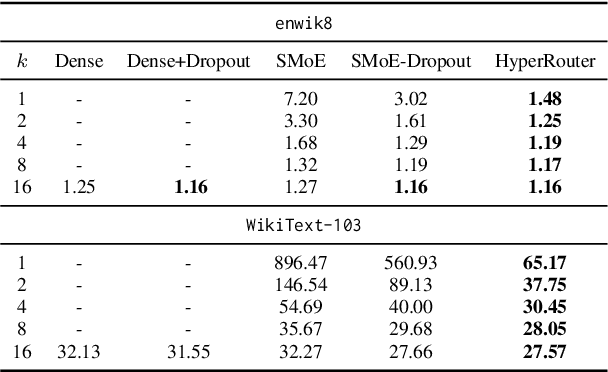
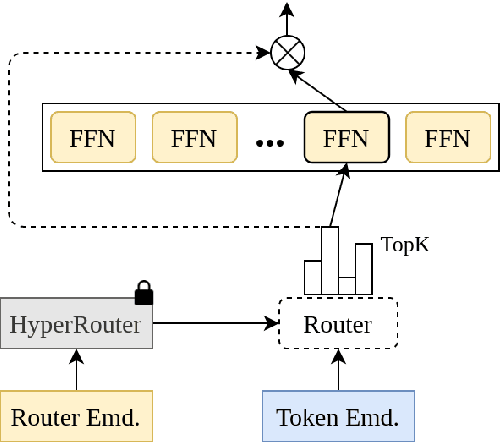

By routing input tokens to only a few split experts, Sparse Mixture-of-Experts has enabled efficient training of large language models. Recent findings suggest that fixing the routers can achieve competitive performance by alleviating the collapsing problem, where all experts eventually learn similar representations. However, this strategy has two key limitations: (i) the policy derived from random routers might be sub-optimal, and (ii) it requires extensive resources during training and evaluation, leading to limited efficiency gains. This work introduces \HyperRout, which dynamically generates the router's parameters through a fixed hypernetwork and trainable embeddings to achieve a balance between training the routers and freezing them to learn an improved routing policy. Extensive experiments across a wide range of tasks demonstrate the superior performance and efficiency gains of \HyperRouter compared to existing routing methods. Our implementation is publicly available at {\url{{https://github.com/giangdip2410/HyperRouter}}}.