 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralist Large Language Models for Molecular Property Prediction: Distilling Knowledge from Specialist Models
Mar 12, 2026Molecular Property Prediction (MPP) is a central task in drug discovery. While Large Language Models (LLMs) show promise as generalist models for MPP, their current performance remains below the threshold for practical adoption. We propose TreeKD, a novel knowledge distillation method that transfers complementary knowledge from tree-based specialist models into LLMs. Our approach trains specialist decision trees on functional group features, then verbalizes their learned predictive rules as natural language to enable rule-augmented context learning. This enables LLMs to leverage structural insights that are difficult to extract from SMILES strings alone. We further introduce rule-consistency, a test-time scaling technique inspired by bagging that ensembles predictions across diverse rules from a Random Forest. Experiments on 22 ADMET properties from the TDC benchmark demonstrate that TreeKD substantially improves LLM performance, narrowing the gap with SOTA specialist models and advancing toward practical generalist models for molecular property prediction.
Transform-Augmented GRPO Improves Pass@k
Jan 30, 2026Large language models trained via next-token prediction are fundamentally pattern-matchers: sensitive to superficial phrasing variations even when the underlying problem is identical. Group Relative Policy Optimization (GRPO) was designed to improve reasoning, but in fact it worsens this situation through two failure modes: diversity collapse, where training amplifies a single solution strategy while ignoring alternatives of gradient signal, and gradient diminishing, where a large portion of questions yield zero gradients because all rollouts receive identical rewards. We propose TA-GRPO (Transform-Augmented GRPO), which generates semantically equivalent transformed variants of each question (via paraphrasing, variable renaming, and format changes) and computes advantages by pooling rewards across the entire group. This pooled computation ensures mixed rewards even when the original question is too easy or too hard, while training on diverse phrasings promotes multiple solution strategies. We provide theoretical justification showing that TA-GRPO reduces zero-gradient probability and improves generalization via reduced train-test distribution shift. Experiments on mathematical reasoning benchmarks show consistent Pass@k improvements, with gains up to 9.84 points on competition math (AMC12, AIME24) and 5.05 points on out-of-distribution scientific reasoning (GPQA-Diamond).
Utilizing Large Language Models in An Iterative Paradigm with Domain Feedback for Molecule Optimization
Oct 17, 2024



Molecule optimization is a critical task in drug discovery to optimize desired properties of a given molecule through chemical modification. Despite Large Language Models (LLMs) holding the potential to efficiently simulate this task by using natural language to direct the optimization, straightforwardly utilizing shows limited performance. In this work, we facilitate utilizing LLMs in an iterative paradigm by proposing a simple yet highly effective domain feedback provider, namely $\text{Re}^2$DF. In detail, $\text{Re}^2$DF harnesses an external toolkit, RDKit, to handle the molecule hallucination, if the modified molecule is chemically invalid. Otherwise, its desired properties are computed and compared to the original one, establishing reliable domain feedback with correct direction and distance towards the objective, followed by a retrieved example, to explicitly guide the LLM to refine the modified molecule. We conduct experiments across both single- and multi-property objectives with 2 thresholds, where $\text{Re}^2$DF shows significant improvements. Particularly, for 20 single-property objectives, $\text{Re}^2$DF enhances the Hit ratio by 16.95\% and 20.76\% under loose and strict thresholds, respectively. For 32 multi-property objectives, $\text{Re}^2$DF enhances the Hit ratio by 6.04\% and 5.25\%.
MolX: Enhancing Large Language Models for Molecular Learning with A Multi-Modal Extension
Jun 10, 2024

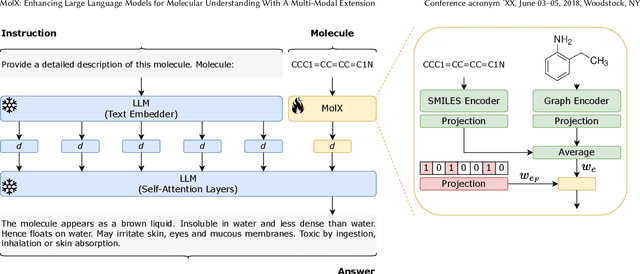
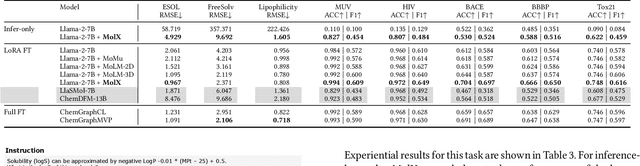
Recently, Large Language Models (LLMs) with their strong task-handling capabilities have shown remarkable advancements across a spectrum of fields, moving beyond natural language understanding. However, their proficiency within the chemistry domain remains restricted, especially in solving professional molecule-related tasks. This challenge is attributed to their inherent limitations in comprehending molecules using only common textual representations, i.e., SMILES strings. In this study, we seek to enhance the ability of LLMs to comprehend molecules by designing and equipping them with a multi-modal external module, namely MolX. In particular, instead of directly using a SMILES string to represent a molecule, we utilize specific encoders to extract fine-grained features from both SMILES string and 2D molecular graph representations for feeding into an LLM. Moreover, a human-defined molecular fingerprint is incorporated to leverage its embedded domain knowledge. Then, to establish an alignment between MolX and the LLM's textual input space, the whole model in which the LLM is frozen, is pre-trained with a versatile strategy including a diverse set of tasks. Extensive experimental evaluations demonstrate that our proposed method only introduces a small number of trainable parameters while outperforming baselines on various downstream molecule-related tasks ranging from molecule-to-text translation to retrosynthesis, with and without fine-tuning the LLM.
Exploring the Practicality of Federated Learning: A Survey Towards the Communication Perspective
May 30, 2024Federated Learning (FL) is a promising paradigm that offers significant advancements in privacy-preserving, decentralized machine learning by enabling collaborative training of models across distributed devices without centralizing data. However, the practical deployment of FL systems faces a significant bottleneck: the communication overhead caused by frequently exchanging large model updates between numerous devices and a central server. This communication inefficiency can hinder training speed, model performance, and the overall feasibility of real-world FL applications. In this survey, we investigate various strategies and advancements made in communication-efficient FL, highlighting their impact and potential to overcome the communication challenges inherent in FL systems. Specifically, we define measures for communication efficiency, analyze sources of communication inefficiency in FL systems, and provide a taxonomy and comprehensive review of state-of-the-art communication-efficient FL methods. Additionally, we discuss promising future research directions for enhancing the communication efficiency of FL systems. By addressing the communication bottleneck, FL can be effectively applied and enable scalable and practical deployment across diverse applications that require privacy-preserving, decentralized machine learning, such as IoT, healthcare, or finance.
Efficiently Assemble Normalization Layers and Regularization for Federated Domain Generalization
Mar 22, 2024Domain shift is a formidable issue in Machine Learning that causes a model to suffer from performance degradation when tested on unseen domains. Federated Domain Generalization (FedDG) attempts to train a global model using collaborative clients in a privacy-preserving manner that can generalize well to unseen clients possibly with domain shift. However, most existing FedDG methods either cause additional privacy risks of data leakage or induce significant costs in client communication and computation, which are major concerns in the Federated Learning paradigm. To circumvent these challenges, here we introduce a novel architectural method for FedDG, namely gPerXAN, which relies on a normalization scheme working with a guiding regularizer. In particular, we carefully design Personalized eXplicitly Assembled Normalization to enforce client models selectively filtering domain-specific features that are biased towards local data while retaining discrimination of those features. Then, we incorporate a simple yet effective regularizer to guide these models in directly capturing domain-invariant representations that the global model's classifier can leverage. Extensive experimental results on two benchmark datasets, i.e., PACS and Office-Home, and a real-world medical dataset, Camelyon17, indicate that our proposed method outperforms other existing methods in addressing this particular problem.
HyperRouter: Towards Efficient Training and Inference of Sparse Mixture of Experts
Dec 12, 2023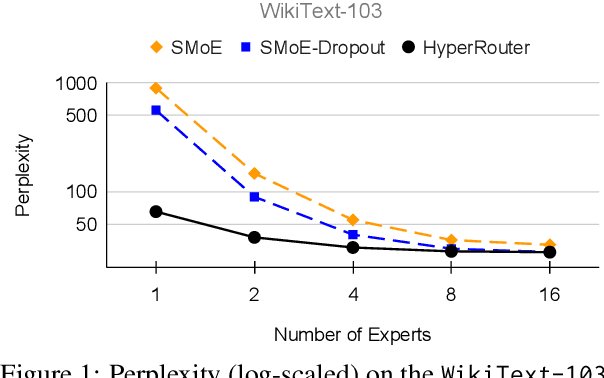
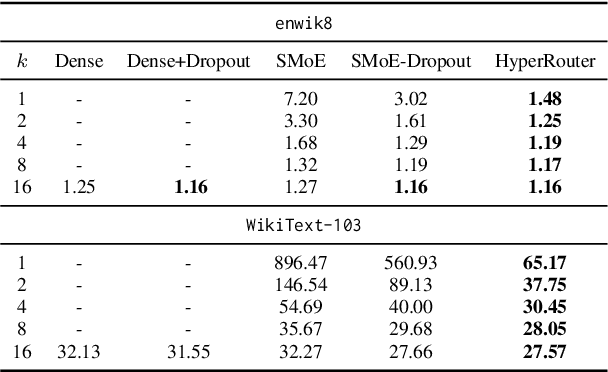
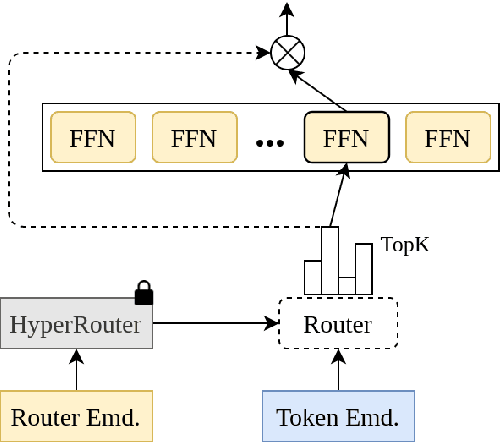

By routing input tokens to only a few split experts, Sparse Mixture-of-Experts has enabled efficient training of large language models. Recent findings suggest that fixing the routers can achieve competitive performance by alleviating the collapsing problem, where all experts eventually learn similar representations. However, this strategy has two key limitations: (i) the policy derived from random routers might be sub-optimal, and (ii) it requires extensive resources during training and evaluation, leading to limited efficiency gains. This work introduces \HyperRout, which dynamically generates the router's parameters through a fixed hypernetwork and trainable embeddings to achieve a balance between training the routers and freezing them to learn an improved routing policy. Extensive experiments across a wide range of tasks demonstrate the superior performance and efficiency gains of \HyperRouter compared to existing routing methods. Our implementation is publicly available at {\url{{https://github.com/giangdip2410/HyperRouter}}}.