 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Generator Replay Degrades: Projected Rehearsal Orchestration for Heterogeneous Federated Class-Incremental Learning
Jun 14, 2026Federated class-incremental learning (FCIL) becomes substantially harder when clients observe different label subsets, progress through tasks at different stages, and provide uneven supervision for the same semantic concepts. Existing FCIL methods often preserve old knowledge through input-space synthesis, but they can be fragile under heterogeneous task streams and difficult to transfer across modalities. To alleviate such issues, we propose PRO, a framework that replaces synthetic input replay with projected rehearsal orchestration. To remove external pretraining, we evaluate all methods under the same warmup. After this, PRO maintains compact class-level projected memories on the server and allows clients perform balanced pseudo multi-task training over current examples and old projected memories. To handle stronger representation drift, we further introduce PRO-MAX, which augments PRO with neighborhood-weighted memory alignment while preserving the same server-light principle that the server only aggregates model updates and memory statistics. Across image, text, and graph benchmarks, PRO and PRO-MAX improve retention and final utility under heterogeneous streams while remaining competitive in homogeneous FCIL. Even when baselines are given expanded replay budgets, they degrade under supervision imbalance and stage misalignment, indicating that replay quantity alone does not resolve replay-quality failures. Additional weak-task diagnostics further show that larger replay mismatch is associated with larger downstream degradation, while our method keeps projected memories better aligned with the evolving representation.
Co-Learning: Towards Semi-Supervised Object Detection with Road-side Cameras
Nov 28, 2024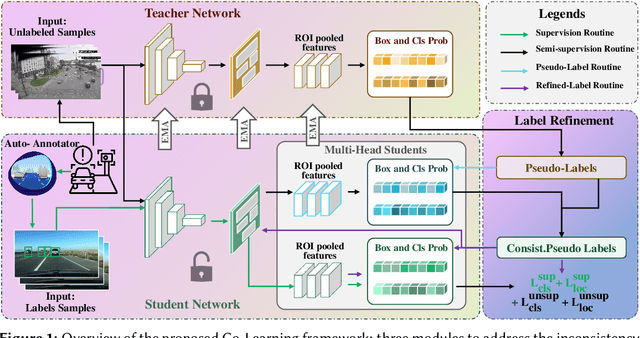


Recently, deep learning has experienced rapid expansion, contributing significantly to the progress of supervised learning methodologies. However, acquiring labeled data in real-world settings can be costly, labor-intensive, and sometimes scarce. This challenge inhibits the extensive use of neural networks for practical tasks due to the impractical nature of labeling vast datasets for every individual application. To tackle this, semi-supervised learning (SSL) offers a promising solution by using both labeled and unlabeled data to train object detectors, potentially enhancing detection efficacy and reducing annotation costs. Nevertheless, SSL faces several challenges, including pseudo-target inconsistencies, disharmony between classification and regression tasks, and efficient use of abundant unlabeled data, especially on edge devices, such as roadside cameras. Thus, we developed a teacher-student-based SSL framework, Co-Learning, which employs mutual learning and annotation-alignment strategies to adeptly navigate these complexities and achieves comparable performance as fully-supervised solutions using 10\% labeled data.
A comparison of extended object tracking with multi-modal sensors in indoor environment
Nov 27, 2024

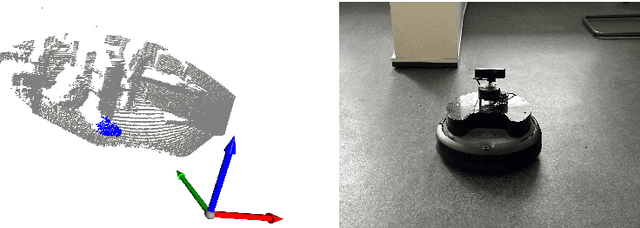

This paper presents a preliminary study of an efficient object tracking approach, comparing the performance of two different 3D point cloud sensory sources: LiDAR and stereo cameras, which have significant price differences. In this preliminary work, we focus on single object tracking. We first developed a fast heuristic object detector that utilizes prior information about the environment and target. The resulting target points are subsequently fed into an extended object tracking framework, where the target shape is parameterized using a star-convex hypersurface model. Experimental results show that our object tracking method using a stereo camera achieves performance similar to that of a LiDAR sensor, with a cost difference of more than tenfold.
Experimental comparison of graph-based approximate nearest neighbor search algorithms on edge devices
Nov 21, 2024In this paper, we present an experimental comparison of various graph-based approximate nearest neighbor (ANN) search algorithms deployed on edge devices for real-time nearest neighbor search applications, such as smart city infrastructure and autonomous vehicles. To the best of our knowledge, this specific comparative analysis has not been previously conducted. While existing research has explored graph-based ANN algorithms, it has often been limited to single-threaded implementations on standard commodity hardware. Our study leverages the full computational and storage capabilities of edge devices, incorporating additional metrics such as insertion and deletion latency of new vectors and power consumption. This comprehensive evaluation aims to provide valuable insights into the performance and suitability of these algorithms for edge-based real-time tracking systems enhanced by nearest-neighbor search algorithms.
Exploring the Practicality of Federated Learning: A Survey Towards the Communication Perspective
May 30, 2024Federated Learning (FL) is a promising paradigm that offers significant advancements in privacy-preserving, decentralized machine learning by enabling collaborative training of models across distributed devices without centralizing data. However, the practical deployment of FL systems faces a significant bottleneck: the communication overhead caused by frequently exchanging large model updates between numerous devices and a central server. This communication inefficiency can hinder training speed, model performance, and the overall feasibility of real-world FL applications. In this survey, we investigate various strategies and advancements made in communication-efficient FL, highlighting their impact and potential to overcome the communication challenges inherent in FL systems. Specifically, we define measures for communication efficiency, analyze sources of communication inefficiency in FL systems, and provide a taxonomy and comprehensive review of state-of-the-art communication-efficient FL methods. Additionally, we discuss promising future research directions for enhancing the communication efficiency of FL systems. By addressing the communication bottleneck, FL can be effectively applied and enable scalable and practical deployment across diverse applications that require privacy-preserving, decentralized machine learning, such as IoT, healthcare, or finance.
Cooperative Students: Navigating Unsupervised Domain Adaptation in Nighttime Object Detection
Apr 03, 2024Unsupervised Domain Adaptation (UDA) has shown significant advancements in object detection under well-lit conditions; however, its performance degrades notably in low-visibility scenarios, especially at night, posing challenges not only for its adaptability in low signal-to-noise ratio (SNR) conditions but also for the reliability and efficiency of automated vehicles. To address this problem, we propose a \textbf{Co}operative \textbf{S}tudents (\textbf{CoS}) framework that innovatively employs global-local transformations (GLT) and a proxy-based target consistency (PTC) mechanism to capture the spatial consistency in day- and night-time scenarios effectively, and thus bridge the significant domain shift across contexts. Building upon this, we further devise an adaptive IoU-informed thresholding (AIT) module to gradually avoid overlooking potential true positives and enrich the latent information in the target domain. Comprehensive experiments show that CoS essentially enhanced UDA performance in low-visibility conditions and surpasses current state-of-the-art techniques, achieving an increase in mAP of 3.0\%, 1.9\%, and 2.5\% on BDD100K, SHIFT, and ACDC datasets, respectively. Code is available at https://github.com/jichengyuan/Cooperitive_Students.
Efficiently Assemble Normalization Layers and Regularization for Federated Domain Generalization
Mar 22, 2024Domain shift is a formidable issue in Machine Learning that causes a model to suffer from performance degradation when tested on unseen domains. Federated Domain Generalization (FedDG) attempts to train a global model using collaborative clients in a privacy-preserving manner that can generalize well to unseen clients possibly with domain shift. However, most existing FedDG methods either cause additional privacy risks of data leakage or induce significant costs in client communication and computation, which are major concerns in the Federated Learning paradigm. To circumvent these challenges, here we introduce a novel architectural method for FedDG, namely gPerXAN, which relies on a normalization scheme working with a guiding regularizer. In particular, we carefully design Personalized eXplicitly Assembled Normalization to enforce client models selectively filtering domain-specific features that are biased towards local data while retaining discrimination of those features. Then, we incorporate a simple yet effective regularizer to guide these models in directly capturing domain-invariant representations that the global model's classifier can leverage. Extensive experimental results on two benchmark datasets, i.e., PACS and Office-Home, and a real-world medical dataset, Camelyon17, indicate that our proposed method outperforms other existing methods in addressing this particular problem.
VisionKG: Unleashing the Power of Visual Datasets via Knowledge Graph
Sep 24, 2023



The availability of vast amounts of visual data with heterogeneous features is a key factor for developing, testing, and benchmarking of new computer vision (CV) algorithms and architectures. Most visual datasets are created and curated for specific tasks or with limited image data distribution for very specific situations, and there is no unified approach to manage and access them across diverse sources, tasks, and taxonomies. This not only creates unnecessary overheads when building robust visual recognition systems, but also introduces biases into learning systems and limits the capabilities of data-centric AI. To address these problems, we propose the Vision Knowledge Graph (VisionKG), a novel resource that interlinks, organizes and manages visual datasets via knowledge graphs and Semantic Web technologies. It can serve as a unified framework facilitating simple access and querying of state-of-the-art visual datasets, regardless of their heterogeneous formats and taxonomies. One of the key differences between our approach and existing methods is that ours is knowledge-based rather than metadatabased. It enhances the enrichment of the semantics at both image and instance levels and offers various data retrieval and exploratory services via SPARQL. VisionKG currently contains 519 million RDF triples that describe approximately 40 million entities, and are accessible at https://vision.semkg.org and through APIs. With the integration of 30 datasets and four popular CV tasks, we demonstrate its usefulness across various scenarios when working with CV pipelines.
An Empirical Study of Federated Learning on IoT-Edge Devices: Resource Allocation and Heterogeneity
May 31, 2023
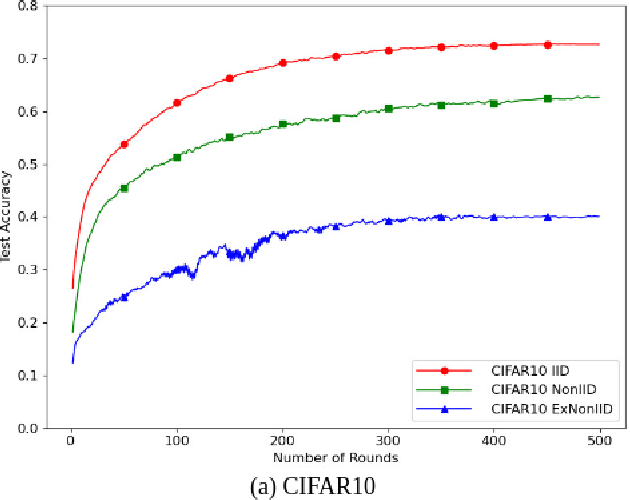


Nowadays, billions of phones, IoT and edge devices around the world generate data continuously, enabling many Machine Learning (ML)-based products and applications. However, due to increasing privacy concerns and regulations, these data tend to reside on devices (clients) instead of being centralized for performing traditional ML model training. Federated Learning (FL) is a distributed approach in which a single server and multiple clients collaboratively build an ML model without moving data away from clients. Whereas existing studies on FL have their own experimental evaluations, most experiments were conducted using a simulation setting or a small-scale testbed. This might limit the understanding of FL implementation in realistic environments. In this empirical study, we systematically conduct extensive experiments on a large network of IoT and edge devices (called IoT-Edge devices) to present FL real-world characteristics, including learning performance and operation (computation and communication) costs. Moreover, we mainly concentrate on heterogeneous scenarios, which is the most challenging issue of FL. By investigating the feasibility of on-device implementation, our study provides valuable insights for researchers and practitioners, promoting the practicality of FL and assisting in improving the current design of real FL systems.
Put Attention to Temporal Saliency Patterns of Multi-Horizon Time Series
Dec 15, 2022Time series, sets of sequences in chronological order, are essential data in statistical research with many forecasting applications. Although recent performance in many Transformer-based models has been noticeable, long multi-horizon time series forecasting remains a very challenging task. Going beyond transformers in sequence translation and transduction research, we observe the effects of down-and-up samplings that can nudge temporal saliency patterns to emerge in time sequences. Motivated by the mentioned observation, in this paper, we propose a novel architecture, Temporal Saliency Detection (TSD), on top of the attention mechanism and apply it to multi-horizon time series prediction. We renovate the traditional encoder-decoder architecture by making as a series of deep convolutional blocks to work in tandem with the multi-head self-attention. The proposed TSD approach facilitates the multiresolution of saliency patterns upon condensed multi-heads, thus progressively enhancing complex time series forecasting. Experimental results illustrate that our proposed approach has significantly outperformed existing state-of-the-art methods across multiple standard benchmark datasets in many far-horizon forecasting settings. Overall, TSD achieves 31% and 46% relative improvement over the current state-of-the-art models in multivariate and univariate time series forecasting scenarios on standard benchmarks. The Git repository is available at https://github.com/duongtrung/time-series-temporal-saliency-patterns.