 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCo-Learning: Towards Semi-Supervised Object Detection with Road-side Cameras
Nov 28, 2024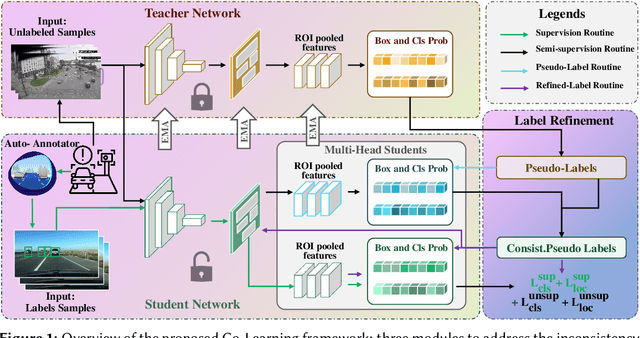


Recently, deep learning has experienced rapid expansion, contributing significantly to the progress of supervised learning methodologies. However, acquiring labeled data in real-world settings can be costly, labor-intensive, and sometimes scarce. This challenge inhibits the extensive use of neural networks for practical tasks due to the impractical nature of labeling vast datasets for every individual application. To tackle this, semi-supervised learning (SSL) offers a promising solution by using both labeled and unlabeled data to train object detectors, potentially enhancing detection efficacy and reducing annotation costs. Nevertheless, SSL faces several challenges, including pseudo-target inconsistencies, disharmony between classification and regression tasks, and efficient use of abundant unlabeled data, especially on edge devices, such as roadside cameras. Thus, we developed a teacher-student-based SSL framework, Co-Learning, which employs mutual learning and annotation-alignment strategies to adeptly navigate these complexities and achieves comparable performance as fully-supervised solutions using 10\% labeled data.
Experimental comparison of graph-based approximate nearest neighbor search algorithms on edge devices
Nov 21, 2024In this paper, we present an experimental comparison of various graph-based approximate nearest neighbor (ANN) search algorithms deployed on edge devices for real-time nearest neighbor search applications, such as smart city infrastructure and autonomous vehicles. To the best of our knowledge, this specific comparative analysis has not been previously conducted. While existing research has explored graph-based ANN algorithms, it has often been limited to single-threaded implementations on standard commodity hardware. Our study leverages the full computational and storage capabilities of edge devices, incorporating additional metrics such as insertion and deletion latency of new vectors and power consumption. This comprehensive evaluation aims to provide valuable insights into the performance and suitability of these algorithms for edge-based real-time tracking systems enhanced by nearest-neighbor search algorithms.
Cooperative Students: Navigating Unsupervised Domain Adaptation in Nighttime Object Detection
Apr 03, 2024Unsupervised Domain Adaptation (UDA) has shown significant advancements in object detection under well-lit conditions; however, its performance degrades notably in low-visibility scenarios, especially at night, posing challenges not only for its adaptability in low signal-to-noise ratio (SNR) conditions but also for the reliability and efficiency of automated vehicles. To address this problem, we propose a \textbf{Co}operative \textbf{S}tudents (\textbf{CoS}) framework that innovatively employs global-local transformations (GLT) and a proxy-based target consistency (PTC) mechanism to capture the spatial consistency in day- and night-time scenarios effectively, and thus bridge the significant domain shift across contexts. Building upon this, we further devise an adaptive IoU-informed thresholding (AIT) module to gradually avoid overlooking potential true positives and enrich the latent information in the target domain. Comprehensive experiments show that CoS essentially enhanced UDA performance in low-visibility conditions and surpasses current state-of-the-art techniques, achieving an increase in mAP of 3.0\%, 1.9\%, and 2.5\% on BDD100K, SHIFT, and ACDC datasets, respectively. Code is available at https://github.com/jichengyuan/Cooperitive_Students.
VisionKG: Unleashing the Power of Visual Datasets via Knowledge Graph
Sep 24, 2023



The availability of vast amounts of visual data with heterogeneous features is a key factor for developing, testing, and benchmarking of new computer vision (CV) algorithms and architectures. Most visual datasets are created and curated for specific tasks or with limited image data distribution for very specific situations, and there is no unified approach to manage and access them across diverse sources, tasks, and taxonomies. This not only creates unnecessary overheads when building robust visual recognition systems, but also introduces biases into learning systems and limits the capabilities of data-centric AI. To address these problems, we propose the Vision Knowledge Graph (VisionKG), a novel resource that interlinks, organizes and manages visual datasets via knowledge graphs and Semantic Web technologies. It can serve as a unified framework facilitating simple access and querying of state-of-the-art visual datasets, regardless of their heterogeneous formats and taxonomies. One of the key differences between our approach and existing methods is that ours is knowledge-based rather than metadatabased. It enhances the enrichment of the semantics at both image and instance levels and offers various data retrieval and exploratory services via SPARQL. VisionKG currently contains 519 million RDF triples that describe approximately 40 million entities, and are accessible at https://vision.semkg.org and through APIs. With the integration of 30 datasets and four popular CV tasks, we demonstrate its usefulness across various scenarios when working with CV pipelines.
Fantastic Data and How to Query Them
Jan 13, 2022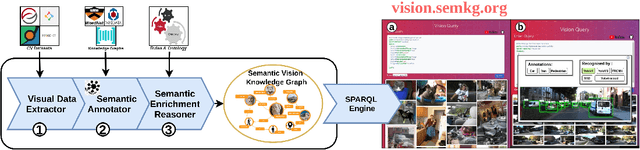
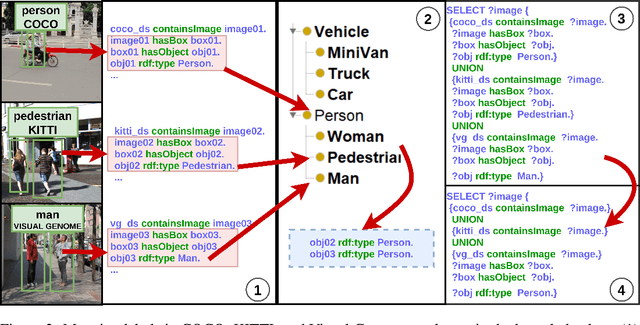
It is commonly acknowledged that the availability of the huge amount of (training) data is one of the most important factors for many recent advances in Artificial Intelligence (AI). However, datasets are often designed for specific tasks in narrow AI sub areas and there is no unified way to manage and access them. This not only creates unnecessary overheads when training or deploying Machine Learning models but also limits the understanding of the data, which is very important for data-centric AI. In this paper, we present our vision about a unified framework for different datasets so that they can be integrated and queried easily, e.g., using standard query languages. We demonstrate this in our ongoing work to create a framework for datasets in Computer Vision and show its advantages in different scenarios. Our demonstration is available at https://vision.semkg.org.