 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReasonVQA: A Multi-hop Reasoning Benchmark with Structural Knowledge for Visual Question Answering
Jul 22, 2025In this paper, we propose a new dataset, ReasonVQA, for the Visual Question Answering (VQA) task. Our dataset is automatically integrated with structured encyclopedic knowledge and constructed using a low-cost framework, which is capable of generating complex, multi-hop questions. We evaluated state-of-the-art VQA models on ReasonVQA, and the empirical results demonstrate that ReasonVQA poses significant challenges to these models, highlighting its potential for benchmarking and advancing the field of VQA. Additionally, our dataset can be easily scaled with respect to input images; the current version surpasses the largest existing datasets requiring external knowledge by more than an order of magnitude.
Approximating Probabilistic Inference in Statistical EL with Knowledge Graph Embeddings
Jul 16, 2024Statistical information is ubiquitous but drawing valid conclusions from it is prohibitively hard. We explain how knowledge graph embeddings can be used to approximate probabilistic inference efficiently using the example of Statistical EL (SEL), a statistical extension of the lightweight Description Logic EL. We provide proofs for runtime and soundness guarantees, and empirically evaluate the runtime and approximation quality of our approach.
Explaining Graph Neural Networks for Node Similarity on Graphs
Jul 10, 2024Similarity search is a fundamental task for exploiting information in various applications dealing with graph data, such as citation networks or knowledge graphs. While this task has been intensively approached from heuristics to graph embeddings and graph neural networks (GNNs), providing explanations for similarity has received less attention. In this work we are concerned with explainable similarity search over graphs, by investigating how GNN-based methods for computing node similarities can be augmented with explanations. Specifically, we evaluate the performance of two prominent approaches towards explanations in GNNs, based on the concepts of mutual information (MI), and gradient-based explanations (GB). We discuss their suitability and empirically validate the properties of their explanations over different popular graph benchmarks. We find that unlike MI explanations, gradient-based explanations have three desirable properties. First, they are actionable: selecting inputs depending on them results in predictable changes in similarity scores. Second, they are consistent: the effect of selecting certain inputs overlaps very little with the effect of discarding them. Third, they can be pruned significantly to obtain sparse explanations that retain the effect on similarity scores.
VisionKG: Unleashing the Power of Visual Datasets via Knowledge Graph
Sep 24, 2023



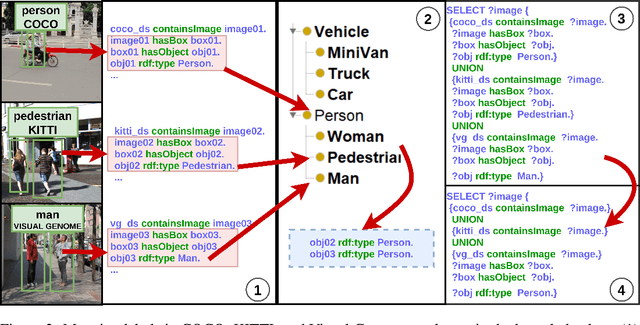
The availability of vast amounts of visual data with heterogeneous features is a key factor for developing, testing, and benchmarking of new computer vision (CV) algorithms and architectures. Most visual datasets are created and curated for specific tasks or with limited image data distribution for very specific situations, and there is no unified approach to manage and access them across diverse sources, tasks, and taxonomies. This not only creates unnecessary overheads when building robust visual recognition systems, but also introduces biases into learning systems and limits the capabilities of data-centric AI. To address these problems, we propose the Vision Knowledge Graph (VisionKG), a novel resource that interlinks, organizes and manages visual datasets via knowledge graphs and Semantic Web technologies. It can serve as a unified framework facilitating simple access and querying of state-of-the-art visual datasets, regardless of their heterogeneous formats and taxonomies. One of the key differences between our approach and existing methods is that ours is knowledge-based rather than metadatabased. It enhances the enrichment of the semantics at both image and instance levels and offers various data retrieval and exploratory services via SPARQL. VisionKG currently contains 519 million RDF triples that describe approximately 40 million entities, and are accessible at https://vision.semkg.org and through APIs. With the integration of 30 datasets and four popular CV tasks, we demonstrate its usefulness across various scenarios when working with CV pipelines.
CQELS 2.0: Towards A Unified Framework for Semantic Stream Fusion
Feb 15, 2022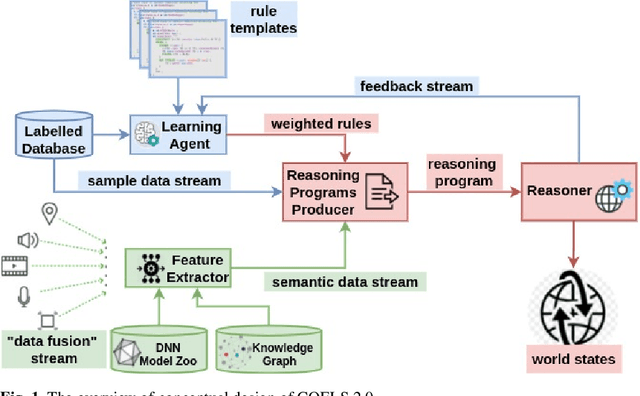
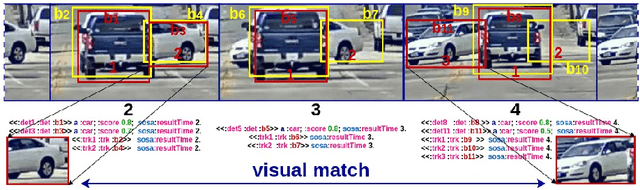
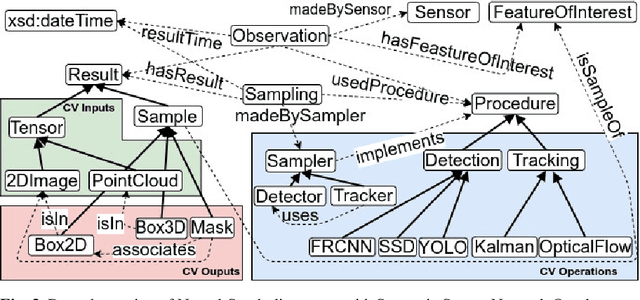
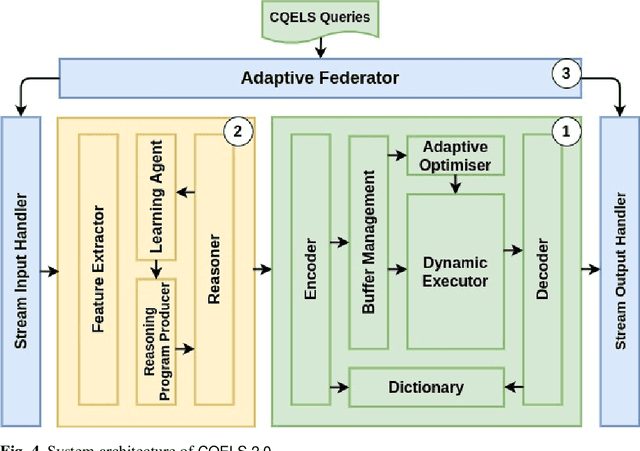
We present CQELS 2.0, the second version of Continuous Query Evaluation over Linked Streams. CQELS 2.0 is a platform-agnostic federated execution framework towards semantic stream fusion. In this version, we introduce a novel neural-symbolic stream reasoning component that enables specifying deep neural network (DNN) based data fusion pipelines via logic rules with learnable probabilistic degrees as weights. As a platform-agnostic framework, CQELS 2.0 can be implemented for devices with different hardware architectures (from embedded devices to cloud infrastructures). Moreover, this version also includes an adaptive federator that allows CQELS instances on different nodes in a network to coordinate their resources to distribute processing pipelines by delegating partial workloads to their peers via subscribing continuous queries
Box Embeddings for the Description Logic EL++
Jan 24, 2022

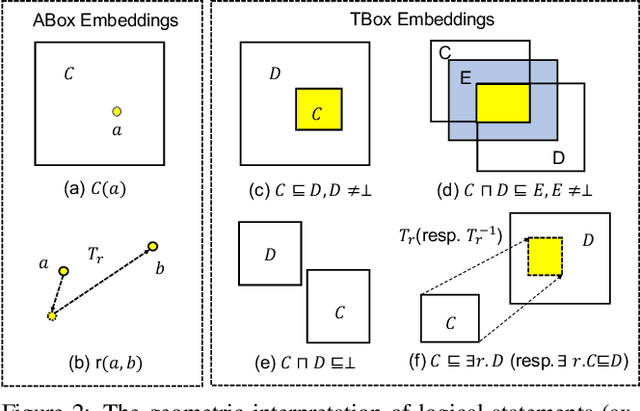

Recently, various methods for representation learning on Knowledge Bases (KBs) have been developed. However, these approaches either only focus on learning the embeddings of the data-level knowledge (ABox) or exhibit inherent limitations when dealing with the concept-level knowledge (TBox), e.g., not properly modelling the structure of the logical knowledge. We present BoxEL, a geometric KB embedding approach that allows for better capturing logical structure expressed in the theories of Description Logic EL++. BoxEL models concepts in a KB as axis-parallel boxes exhibiting the advantage of intersectional closure, entities as points inside boxes, and relations between concepts/entities as affine transformations. We show theoretical guarantees (soundness) of BoxEL for preserving logical structure. Namely, the trained model of BoxEL embedding with loss 0 is a (logical) model of the KB. Experimental results on subsumption reasoning and a real-world application--protein-protein prediction show that BoxEL outperforms traditional knowledge graph embedding methods as well as state-of-the-art EL++ embedding approaches.
Fantastic Data and How to Query Them
Jan 13, 2022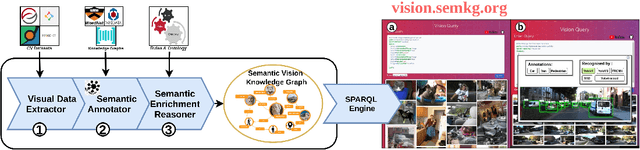
It is commonly acknowledged that the availability of the huge amount of (training) data is one of the most important factors for many recent advances in Artificial Intelligence (AI). However, datasets are often designed for specific tasks in narrow AI sub areas and there is no unified way to manage and access them. This not only creates unnecessary overheads when training or deploying Machine Learning models but also limits the understanding of the data, which is very important for data-centric AI. In this paper, we present our vision about a unified framework for different datasets so that they can be integrated and queried easily, e.g., using standard query languages. We demonstrate this in our ongoing work to create a framework for datasets in Computer Vision and show its advantages in different scenarios. Our demonstration is available at https://vision.semkg.org.
A Neural-symbolic Approach for Ontology-mediated Query Answering
Jun 26, 2021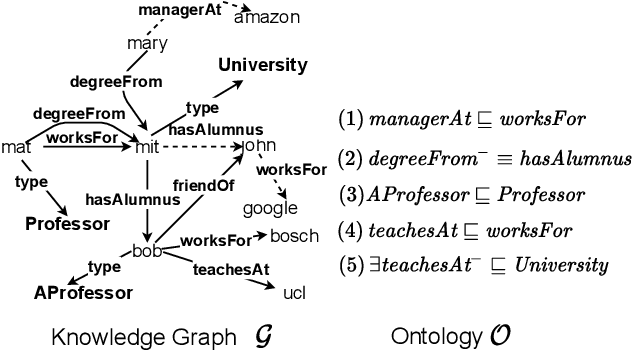
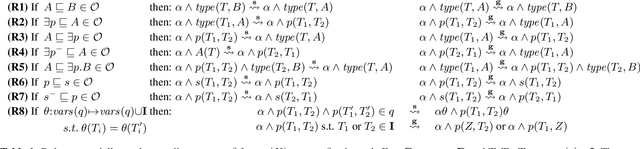
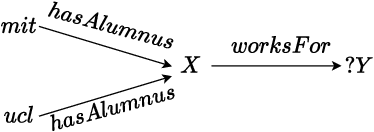

Recently, low-dimensional vector space representations of knowledge graphs (KGs) have been applied to find answers to conjunctive queries (CQs) over incomplete KGs. However, the current methods only focus on inductive reasoning, i.e. answering CQs by predicting facts based on patterns learned from the data, and lack the ability of deductive reasoning by applying external domain knowledge. Such (expert or commonsense) domain knowledge is an invaluable resource which can be used to advance machine intelligence. To address this shortcoming, we introduce a neural-symbolic method for ontology-mediated CQ answering over incomplete KGs that operates in the embedding space. More specifically, we propose various data augmentation strategies to generate training queries using query-rewriting based methods and then exploit a novel loss function for training the model. The experimental results demonstrate the effectiveness of our training strategies and the new loss function, i.e., our method significantly outperforms the baseline in the settings that require both inductive and deductive reasoning.