 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRadar Spectra-Language Model for Automotive Scene Parsing
Jun 04, 2024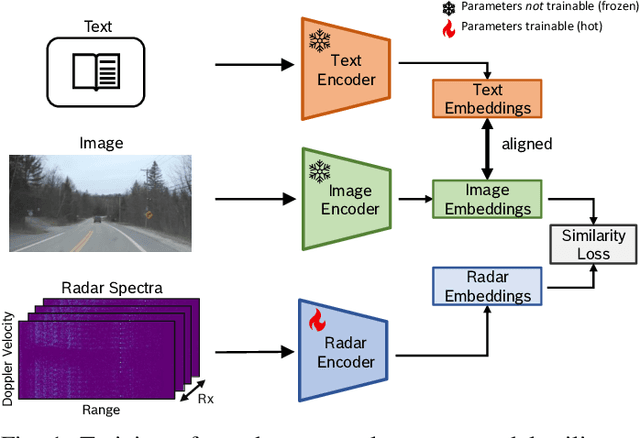



Radar sensors are low cost, long-range, and weather-resilient. Therefore, they are widely used for driver assistance functions, and are expected to be crucial for the success of autonomous driving in the future. In many perception tasks only pre-processed radar point clouds are considered. In contrast, radar spectra are a raw form of radar measurements and contain more information than radar point clouds. However, radar spectra are rather difficult to interpret. In this work, we aim to explore the semantic information contained in spectra in the context of automated driving, thereby moving towards better interpretability of radar spectra. To this end, we create a radar spectra-language model, allowing us to query radar spectra measurements for the presence of scene elements using free text. We overcome the scarcity of radar spectra data by matching the embedding space of an existing vision-language model (VLM). Finally, we explore the benefit of the learned representation for scene parsing, and obtain improvements in free space segmentation and object detection merely by injecting the spectra embedding into a baseline model.
A Neural-symbolic Approach for Ontology-mediated Query Answering
Jun 26, 2021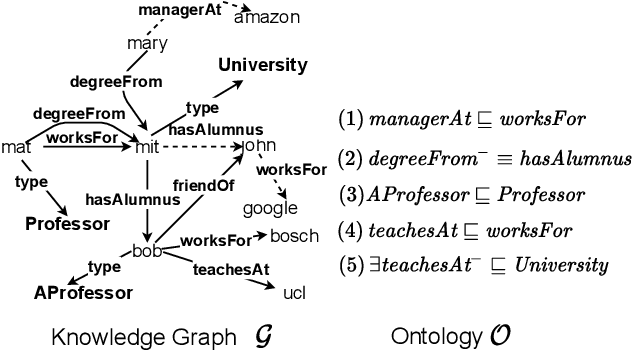
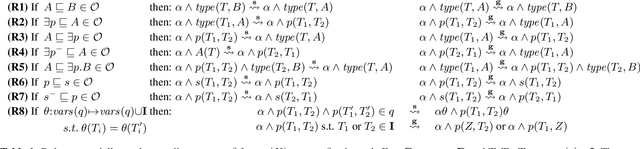
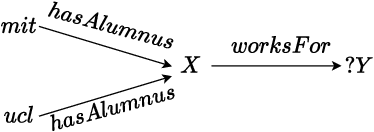

Recently, low-dimensional vector space representations of knowledge graphs (KGs) have been applied to find answers to conjunctive queries (CQs) over incomplete KGs. However, the current methods only focus on inductive reasoning, i.e. answering CQs by predicting facts based on patterns learned from the data, and lack the ability of deductive reasoning by applying external domain knowledge. Such (expert or commonsense) domain knowledge is an invaluable resource which can be used to advance machine intelligence. To address this shortcoming, we introduce a neural-symbolic method for ontology-mediated CQ answering over incomplete KGs that operates in the embedding space. More specifically, we propose various data augmentation strategies to generate training queries using query-rewriting based methods and then exploit a novel loss function for training the model. The experimental results demonstrate the effectiveness of our training strategies and the new loss function, i.e., our method significantly outperforms the baseline in the settings that require both inductive and deductive reasoning.
Probabilistic Discriminative Learning with Layered Graphical Models
Jan 31, 2019
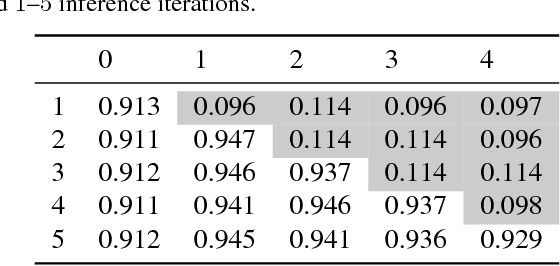


Probabilistic graphical models are traditionally known for their successes in generative modeling. In this work, we advocate layered graphical models (LGMs) for probabilistic discriminative learning. To this end, we design LGMs in close analogy to neural networks (NNs), that is, they have deep hierarchical structures and convolutional or local connections between layers. Equipped with tensorized truncated variational inference, our LGMs can be efficiently trained via backpropagation on mainstream deep learning frameworks such as PyTorch. To deal with continuous valued inputs, we use a simple yet effective soft-clamping strategy for efficient inference. Through extensive experiments on image classification over MNIST and FashionMNIST datasets, we demonstrate that LGMs are capable of achieving competitive results comparable to NNs of similar architectures, while preserving transparent probabilistic modeling.
Discrete-Continuous ADMM for Transductive Inference in Higher-Order MRFs
Apr 28, 2018
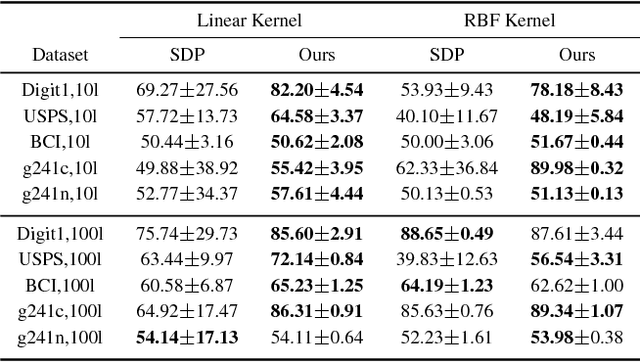


This paper introduces a novel algorithm for transductive inference in higher-order MRFs, where the unary energies are parameterized by a variable classifier. The considered task is posed as a joint optimization problem in the continuous classifier parameters and the discrete label variables. In contrast to prior approaches such as convex relaxations, we propose an advantageous decoupling of the objective function into discrete and continuous subproblems and a novel, efficient optimization method related to ADMM. This approach preserves integrality of the discrete label variables and guarantees global convergence to a critical point. We demonstrate the advantages of our approach in several experiments including video object segmentation on the DAVIS data set and interactive image segmentation.