 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Rules from KGs Guided by Language Models
Sep 12, 2024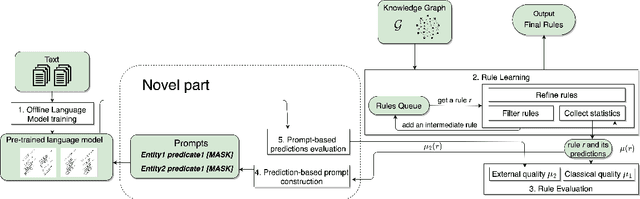
Advances in information extraction have enabled the automatic construction of large knowledge graphs (e.g., Yago, Wikidata or Google KG), which are widely used in many applications like semantic search or data analytics. However, due to their semi-automatic construction, KGs are often incomplete. Rule learning methods, concerned with the extraction of frequent patterns from KGs and casting them into rules, can be applied to predict potentially missing facts. A crucial step in this process is rule ranking. Ranking of rules is especially challenging over highly incomplete or biased KGs (e.g., KGs predominantly storing facts about famous people), as in this case biased rules might fit the data best and be ranked at the top based on standard statistical metrics like rule confidence. To address this issue, prior works proposed to rank rules not only relying on the original KG but also facts predicted by a KG embedding model. At the same time, with the recent rise of Language Models (LMs), several works have claimed that LMs can be used as alternative means for KG completion. In this work, our goal is to verify to which extent the exploitation of LMs is helpful for improving the quality of rule learning systems.
Explaining Graph Neural Networks for Node Similarity on Graphs
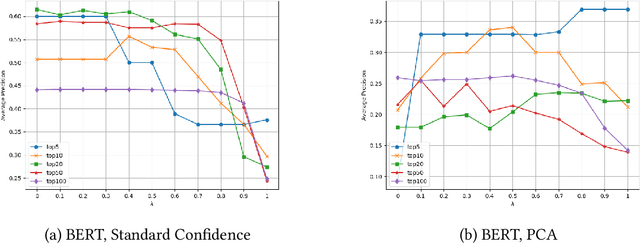
Jul 10, 2024Similarity search is a fundamental task for exploiting information in various applications dealing with graph data, such as citation networks or knowledge graphs. While this task has been intensively approached from heuristics to graph embeddings and graph neural networks (GNNs), providing explanations for similarity has received less attention. In this work we are concerned with explainable similarity search over graphs, by investigating how GNN-based methods for computing node similarities can be augmented with explanations. Specifically, we evaluate the performance of two prominent approaches towards explanations in GNNs, based on the concepts of mutual information (MI), and gradient-based explanations (GB). We discuss their suitability and empirically validate the properties of their explanations over different popular graph benchmarks. We find that unlike MI explanations, gradient-based explanations have three desirable properties. First, they are actionable: selecting inputs depending on them results in predictable changes in similarity scores. Second, they are consistent: the effect of selecting certain inputs overlaps very little with the effect of discarding them. Third, they can be pruned significantly to obtain sparse explanations that retain the effect on similarity scores.
Contextual Reasoning for Scene Generation (Technical Report)
May 03, 2023

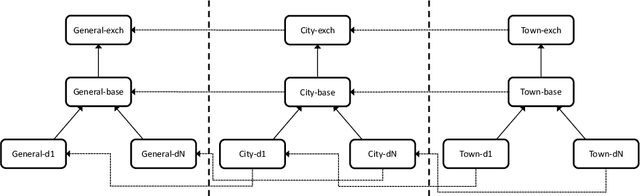

We present a continuation to our previous work, in which we developed the MR-CKR framework to reason with knowledge overriding across contexts organized in multi-relational hierarchies. Reasoning is realized via ASP with algebraic measures, allowing for flexible definitions of preferences. In this paper, we show how to apply our theoretical work to real autonomous-vehicle scene data. Goal of this work is to apply MR-CKR to the problem of generating challenging scenes for autonomous vehicle learning. In practice, most of the scene data for AV learning models common situations, thus it might be difficult to capture cases where a particular situation occurs (e.g. partial occlusions of a crossing pedestrian). The MR-CKR model allows for data organization exploiting the multi-dimensionality of such data (e.g., temporal and spatial). Reasoning over multiple contexts enables the verification and configuration of scenes, using the combination of different scene ontologies. We describe a framework for semantically guided data generation, based on a combination of MR-CKR and Algebraic Measures. The framework is implemented in a proof-of-concept prototype exemplifying some cases of scene generation.
Answer-Set Programming for Lexicographical Makespan Optimisation in Parallel Machine Scheduling
Dec 18, 2022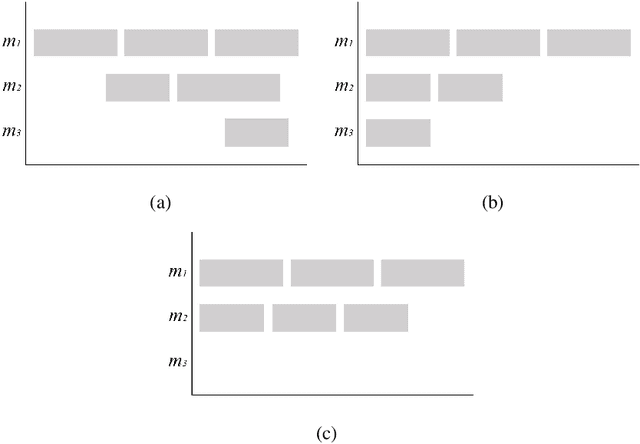


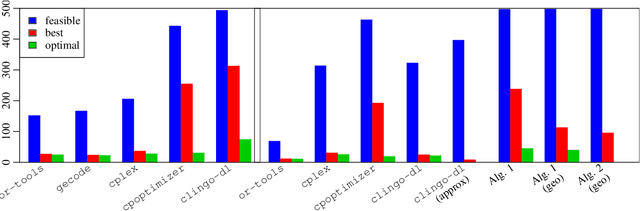
We deal with a challenging scheduling problem on parallel machines with sequence-dependent setup times and release dates from a real-world application of semiconductor work-shop production. There, jobs can only be processed by dedicated machines, thus few machines can determine the makespan almost regardless of how jobs are scheduled on the remaining ones. This causes problems when machines fail and jobs need to be rescheduled. Instead of optimising only the makespan, we put the individual machine spans in non-ascending order and lexicographically minimise the resulting tuples. This achieves that all machines complete as early as possible and increases the robustness of the schedule. We study the application of Answer-Set Programming (ASP) to solve this problem. While ASP eases modelling, the combination of timing constraints and the considered objective function challenges current solving technology. The former issue is addressed by using an extension of ASP by difference logic. For the latter, we devise different algorithms that use multi-shot solving. To tackle industrial-sized instances, we study different approximations and heuristics. Our experimental results show that ASP is indeed a promising KRR paradigm for this problem and is competitive with state-of-the-art CP and MIP solvers. Under consideration in Theory and Practice of Logic Programming (TPLP).
On Event-Driven Knowledge Graph Completion in Digital Factories
Sep 08, 2021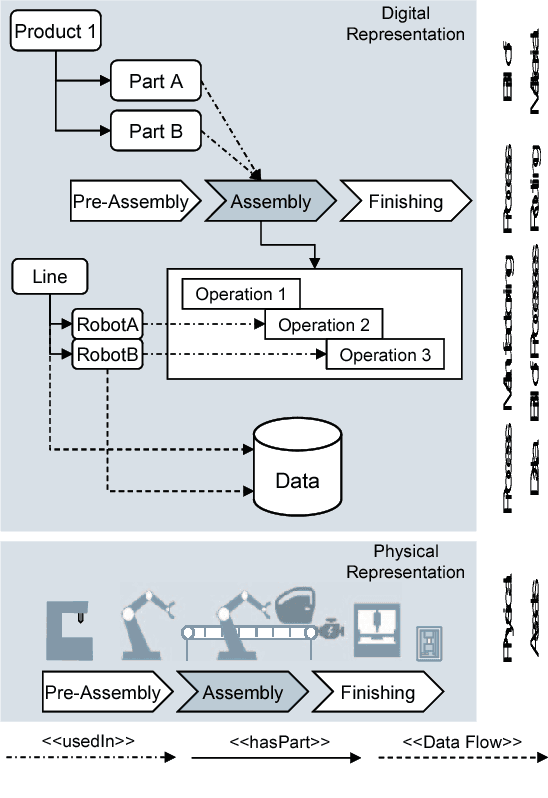
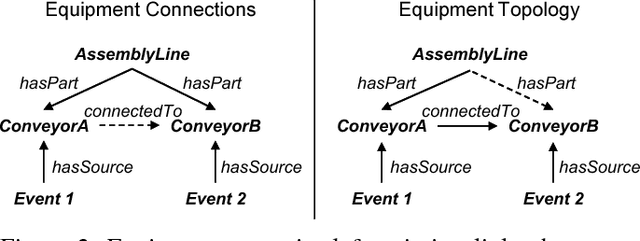


Smart factories are equipped with machines that can sense their manufacturing environments, interact with each other, and control production processes. Smooth operation of such factories requires that the machines and engineering personnel that conduct their monitoring and diagnostics share a detailed common industrial knowledge about the factory, e.g., in the form of knowledge graphs. Creation and maintenance of such knowledge is expensive and requires automation. In this work we show how machine learning that is specifically tailored towards industrial applications can help in knowledge graph completion. In particular, we show how knowledge completion can benefit from event logs that are common in smart factories. We evaluate this on the knowledge graph from a real world-inspired smart factory with encouraging results.
A Neural-symbolic Approach for Ontology-mediated Query Answering
Jun 26, 2021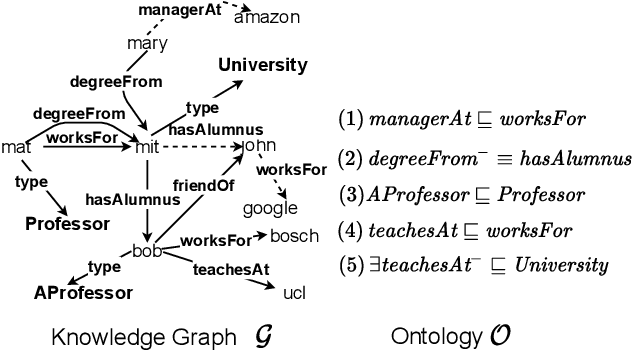
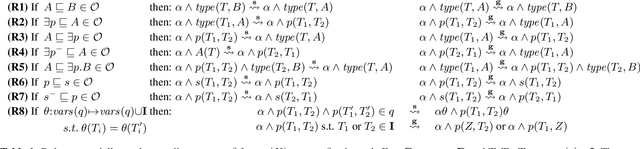
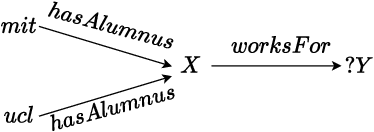

Recently, low-dimensional vector space representations of knowledge graphs (KGs) have been applied to find answers to conjunctive queries (CQs) over incomplete KGs. However, the current methods only focus on inductive reasoning, i.e. answering CQs by predicting facts based on patterns learned from the data, and lack the ability of deductive reasoning by applying external domain knowledge. Such (expert or commonsense) domain knowledge is an invaluable resource which can be used to advance machine intelligence. To address this shortcoming, we introduce a neural-symbolic method for ontology-mediated CQ answering over incomplete KGs that operates in the embedding space. More specifically, we propose various data augmentation strategies to generate training queries using query-rewriting based methods and then exploit a novel loss function for training the model. The experimental results demonstrate the effectiveness of our training strategies and the new loss function, i.e., our method significantly outperforms the baseline in the settings that require both inductive and deductive reasoning.
Hybrid ASP-based Approach to Pattern Mining
Aug 22, 2018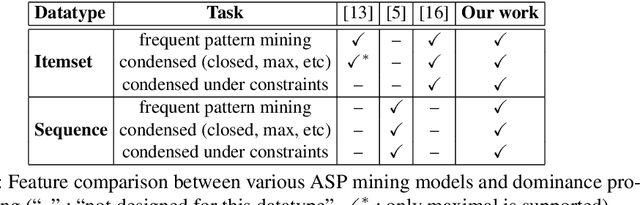
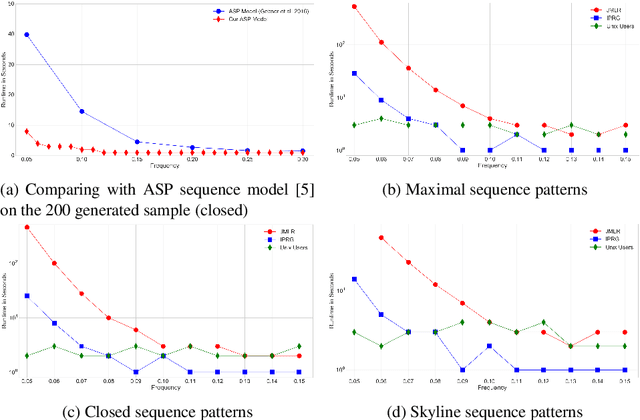

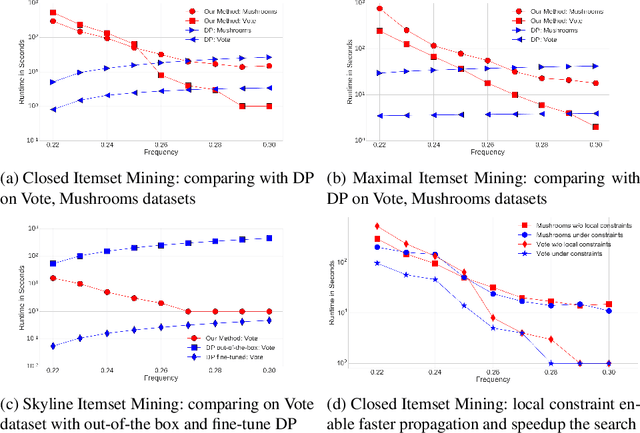
Detecting small sets of relevant patterns from a given dataset is a central challenge in data mining. The relevance of a pattern is based on user-provided criteria; typically, all patterns that satisfy certain criteria are considered relevant. Rule-based languages like Answer Set Programming (ASP) seem well-suited for specifying such criteria in a form of constraints. Although progress has been made, on the one hand, on solving individual mining problems and, on the other hand, developing generic mining systems, the existing methods either focus on scalability or on generality. In this paper we make steps towards combining local (frequency, size, cost) and global (various condensed representations like maximal, closed, skyline) constraints in a generic and efficient way. We present a hybrid approach for itemset, sequence and graph mining which exploits dedicated highly optimized mining systems to detect frequent patterns and then filters the results using declarative ASP. To further demonstrate the generic nature of our hybrid framework we apply it to a problem of approximately tiling a database. Experiments on real-world datasets show the effectiveness of the proposed method and computational gains for itemset, sequence and graph mining, as well as approximate tiling. Under consideration in Theory and Practice of Logic Programming (TPLP).