 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePPT: A Process-based Preference Learning Framework for Self Improving Table Question Answering Models
May 23, 2025

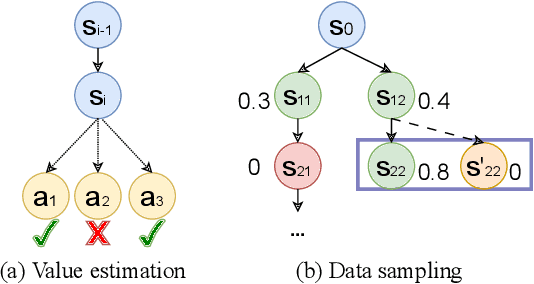
Improving large language models (LLMs) with self-generated data has demonstrated success in tasks such as mathematical reasoning and code generation. Yet, no exploration has been made on table question answering (TQA), where a system answers questions based on tabular data. Addressing this gap is crucial for TQA, as effective self-improvement can boost performance without requiring costly or manually annotated data. In this work, we propose PPT, a Process-based Preference learning framework for TQA. It decomposes reasoning chains into discrete states, assigns scores to each state, and samples contrastive steps for preference learning. Experimental results show that PPT effectively improves TQA models by up to 5% on in-domain datasets and 2.4% on out-of-domain datasets, with only 8,000 preference pairs. Furthermore, the resulting models achieve competitive results compared to more complex and larger state-of-the-art TQA systems, while being five times more efficient during inference.
Texts or Images? A Fine-grained Analysis on the Effectiveness of Input Representations and Models for Table Question Answering
May 20, 2025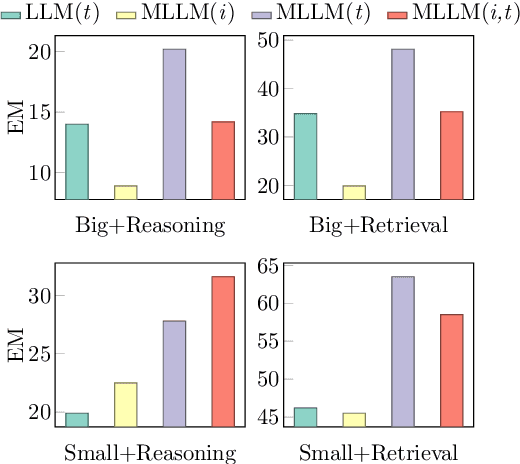
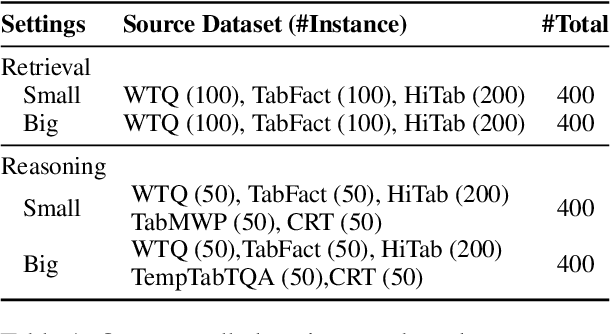

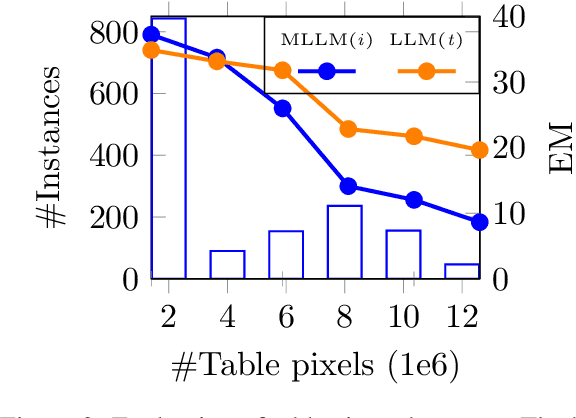
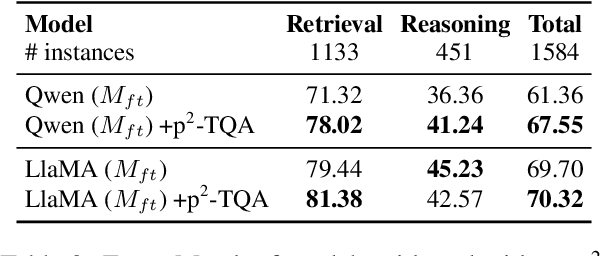
In table question answering (TQA), tables are encoded as either texts or images. Prior work suggests that passing images of tables to multi-modal large language models (MLLMs) performs comparably to or even better than using textual input with large language models (LLMs). However, the lack of controlled setups limits fine-grained distinctions between these approaches. In this paper, we conduct the first controlled study on the effectiveness of several combinations of table representations and models from two perspectives: question complexity and table size. We build a new benchmark based on existing TQA datasets. In a systematic analysis of seven pairs of MLLMs and LLMs, we find that the best combination of table representation and model varies across setups. We propose FRES, a method selecting table representations dynamically, and observe a 10% average performance improvement compared to using both representations indiscriminately.
Language Mixing in Reasoning Language Models: Patterns, Impact, and Internal Causes
May 20, 2025Reasoning language models (RLMs) excel at complex tasks by leveraging a chain-of-thought process to generate structured intermediate steps. However, language mixing, i.e., reasoning steps containing tokens from languages other than the prompt, has been observed in their outputs and shown to affect performance, though its impact remains debated. We present the first systematic study of language mixing in RLMs, examining its patterns, impact, and internal causes across 15 languages, 7 task difficulty levels, and 18 subject areas, and show how all three factors influence language mixing. Moreover, we demonstrate that the choice of reasoning language significantly affects performance: forcing models to reason in Latin or Han scripts via constrained decoding notably improves accuracy. Finally, we show that the script composition of reasoning traces closely aligns with that of the model's internal representations, indicating that language mixing reflects latent processing preferences in RLMs. Our findings provide actionable insights for optimizing multilingual reasoning and open new directions for controlling reasoning languages to build more interpretable and adaptable RLMs.
Lost in Multilinguality: Dissecting Cross-lingual Factual Inconsistency in Transformer Language Models
Apr 05, 2025



Multilingual language models (MLMs) store factual knowledge across languages but often struggle to provide consistent responses to semantically equivalent prompts in different languages. While previous studies point out this cross-lingual inconsistency issue, the underlying causes remain unexplored. In this work, we use mechanistic interpretability methods to investigate cross-lingual inconsistencies in MLMs. We find that MLMs encode knowledge in a language-independent concept space through most layers, and only transition to language-specific spaces in the final layers. Failures during the language transition often result in incorrect predictions in the target language, even when the answers are correct in other languages. To mitigate this inconsistency issue, we propose a linear shortcut method that bypasses computations in the final layers, enhancing both prediction accuracy and cross-lingual consistency. Our findings shed light on the internal mechanisms of MLMs and provide a lightweight, effective strategy for producing more consistent factual outputs.
Bring Your Own Knowledge: A Survey of Methods for LLM Knowledge Expansion
Feb 18, 2025Adapting large language models (LLMs) to new and diverse knowledge is essential for their lasting effectiveness in real-world applications. This survey provides an overview of state-of-the-art methods for expanding the knowledge of LLMs, focusing on integrating various knowledge types, including factual information, domain expertise, language proficiency, and user preferences. We explore techniques, such as continual learning, model editing, and retrieval-based explicit adaptation, while discussing challenges like knowledge consistency and scalability. Designed as a guide for researchers and practitioners, this survey sheds light on opportunities for advancing LLMs as adaptable and robust knowledge systems.
Efficient Multi-Agent Collaboration with Tool Use for Online Planning in Complex Table Question Answering
Dec 28, 2024



Complex table question answering (TQA) aims to answer questions that require complex reasoning, such as multi-step or multi-category reasoning, over data represented in tabular form. Previous approaches demonstrated notable performance by leveraging either closed-source large language models (LLMs) or fine-tuned open-weight LLMs. However, fine-tuning LLMs requires high-quality training data, which is costly to obtain, and utilizing closed-source LLMs poses accessibility challenges and leads to reproducibility issues. In this paper, we propose Multi-Agent Collaboration with Tool use (MACT), a framework that requires neither closed-source models nor fine-tuning. In MACT, a planning agent and a coding agent that also make use of tools collaborate to answer questions. Our experiments on four TQA benchmarks show that MACT outperforms previous SoTA systems on three out of four benchmarks and that it performs comparably to the larger and more expensive closed-source model GPT-4 on two benchmarks, even when using only open-weight models without any fine-tuning. We conduct extensive analyses to prove the effectiveness of MACT's multi-agent collaboration in TQA.
Human vs. AI: A Novel Benchmark and a Comparative Study on the Detection of Generated Images and the Impact of Prompts
Dec 12, 2024With the advent of publicly available AI-based text-to-image systems, the process of creating photorealistic but fully synthetic images has been largely democratized. This can pose a threat to the public through a simplified spread of disinformation. Machine detectors and human media expertise can help to differentiate between AI-generated (fake) and real images and counteract this danger. Although AI generation models are highly prompt-dependent, the impact of the prompt on the fake detection performance has rarely been investigated yet. This work therefore examines the influence of the prompt's level of detail on the detectability of fake images, both with an AI detector and in a user study. For this purpose, we create a novel dataset, COCOXGEN, which consists of real photos from the COCO dataset as well as images generated with SDXL and Fooocus using prompts of two standardized lengths. Our user study with 200 participants shows that images generated with longer, more detailed prompts are detected significantly more easily than those generated with short prompts. Similarly, an AI-based detection model achieves better performance on images generated with longer prompts. However, humans and AI models seem to pay attention to different details, as we show in a heat map analysis.
Better Call SAUL: Fluent and Consistent Language Model Editing with Generation Regularization
Oct 03, 2024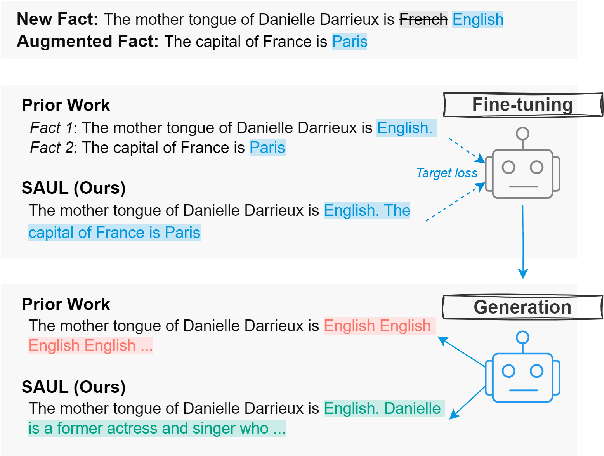
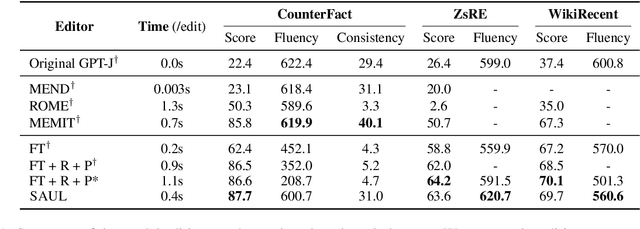

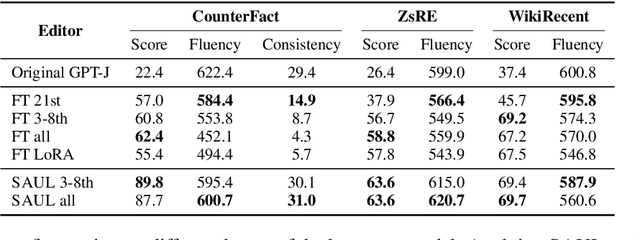
To ensure large language models contain up-to-date knowledge, they need to be updated regularly. However, model editing is challenging as it might also affect knowledge that is unrelated to the new data. State-of-the-art methods identify parameters associated with specific knowledge and then modify them via direct weight updates. However, these locate-and-edit methods suffer from heavy computational overhead and lack theoretical validation. In contrast, directly fine-tuning the model on requested edits affects the model's behavior on unrelated knowledge, and significantly damages the model's generation fluency and consistency. To address these challenges, we propose SAUL, a streamlined model editing method that uses sentence concatenation with augmented random facts for generation regularization. Evaluations on three model editing benchmarks show that SAUL is a practical and reliable solution for model editing outperforming state-of-the-art methods while maintaining generation quality and reducing computational overhead.
Learning Rules from KGs Guided by Language Models
Sep 12, 2024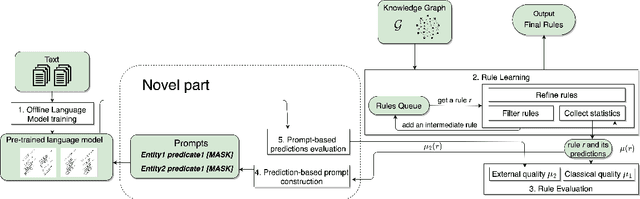
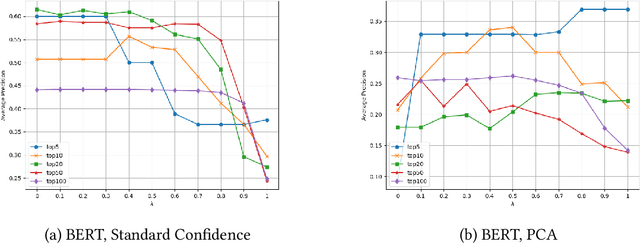
Advances in information extraction have enabled the automatic construction of large knowledge graphs (e.g., Yago, Wikidata or Google KG), which are widely used in many applications like semantic search or data analytics. However, due to their semi-automatic construction, KGs are often incomplete. Rule learning methods, concerned with the extraction of frequent patterns from KGs and casting them into rules, can be applied to predict potentially missing facts. A crucial step in this process is rule ranking. Ranking of rules is especially challenging over highly incomplete or biased KGs (e.g., KGs predominantly storing facts about famous people), as in this case biased rules might fit the data best and be ranked at the top based on standard statistical metrics like rule confidence. To address this issue, prior works proposed to rank rules not only relying on the original KG but also facts predicted by a KG embedding model. At the same time, with the recent rise of Language Models (LMs), several works have claimed that LMs can be used as alternative means for KG completion. In this work, our goal is to verify to which extent the exploitation of LMs is helpful for improving the quality of rule learning systems.
Learn it or Leave it: Module Composition and Pruning for Continual Learning
Jun 26, 2024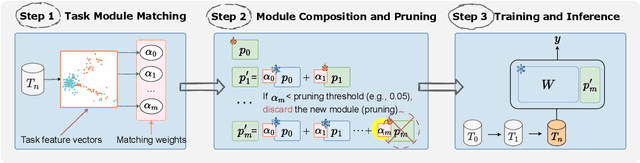
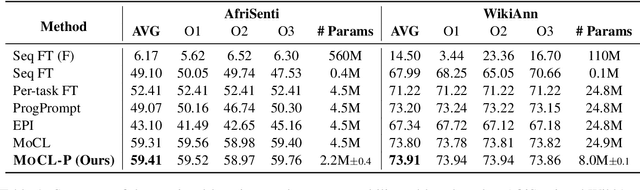
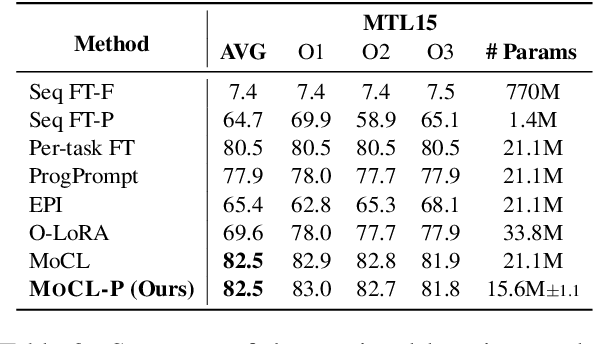
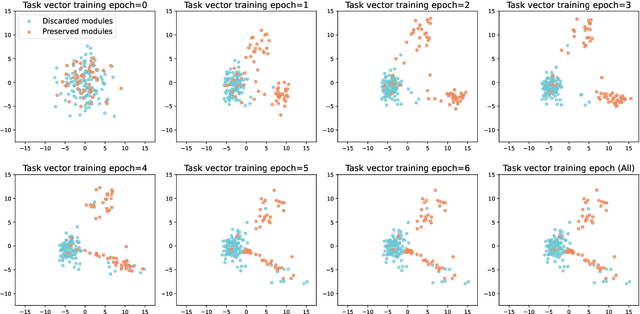
In real-world environments, continual learning is essential for machine learning models, as they need to acquire new knowledge incrementally without forgetting what they have already learned. While pretrained language models have shown impressive capabilities on various static tasks, applying them to continual learning poses significant challenges, including avoiding catastrophic forgetting, facilitating knowledge transfer, and maintaining parameter efficiency. In this paper, we introduce MoCL-P, a novel lightweight continual learning method that addresses these challenges simultaneously. Unlike traditional approaches that continuously expand parameters for newly arriving tasks, MoCL-P integrates task representation-guided module composition with adaptive pruning, effectively balancing knowledge integration and computational overhead. Our evaluation across three continual learning benchmarks with up to 176 tasks shows that MoCL-P achieves state-of-the-art performance and improves parameter efficiency by up to three times, demonstrating its potential for practical applications where resource requirements are constrained.