 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Rules from KGs Guided by Language Models
Paper and Code
Sep 12, 2024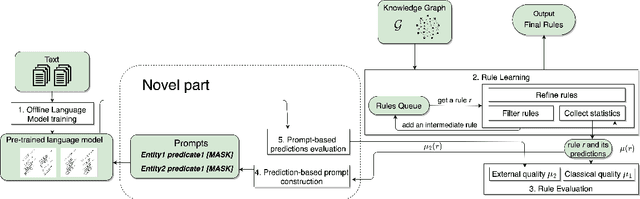
Advances in information extraction have enabled the automatic construction of large knowledge graphs (e.g., Yago, Wikidata or Google KG), which are widely used in many applications like semantic search or data analytics. However, due to their semi-automatic construction, KGs are often incomplete. Rule learning methods, concerned with the extraction of frequent patterns from KGs and casting them into rules, can be applied to predict potentially missing facts. A crucial step in this process is rule ranking. Ranking of rules is especially challenging over highly incomplete or biased KGs (e.g., KGs predominantly storing facts about famous people), as in this case biased rules might fit the data best and be ranked at the top based on standard statistical metrics like rule confidence. To address this issue, prior works proposed to rank rules not only relying on the original KG but also facts predicted by a KG embedding model. At the same time, with the recent rise of Language Models (LMs), several works have claimed that LMs can be used as alternative means for KG completion. In this work, our goal is to verify to which extent the exploitation of LMs is helpful for improving the quality of rule learning systems.