 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic In-Domain Exemplar Construction and LLM-Based Refinement of Multi-LLM Expansions for Query Expansion
Feb 09, 2026Query expansion with large language models is promising but often relies on hand-crafted prompts, manually chosen exemplars, or a single LLM, making it non-scalable and sensitive to domain shift. We present an automated, domain-adaptive QE framework that builds in-domain exemplar pools by harvesting pseudo-relevant passages using a BM25-MonoT5 pipeline. A training-free cluster-based strategy selects diverse demonstrations, yielding strong and stable in-context QE without supervision. To further exploit model complementarity, we introduce a two-LLM ensemble in which two heterogeneous LLMs independently generate expansions and a refinement LLM consolidates them into one coherent expansion. Across TREC DL20, DBPedia, and SciFact, the refined ensemble delivers consistent and statistically significant gains over BM25, Rocchio, zero-shot, and fixed few-shot baselines. The framework offers a reproducible testbed for exemplar selection and multi-LLM generation, and a practical, label-free solution for real-world QE.
Locate, Steer, and Improve: A Practical Survey of Actionable Mechanistic Interpretability in Large Language Models
Jan 20, 2026Mechanistic Interpretability (MI) has emerged as a vital approach to demystify the opaque decision-making of Large Language Models (LLMs). However, existing reviews primarily treat MI as an observational science, summarizing analytical insights while lacking a systematic framework for actionable intervention. To bridge this gap, we present a practical survey structured around the pipeline: "Locate, Steer, and Improve." We formally categorize Localizing (diagnosis) and Steering (intervention) methods based on specific Interpretable Objects to establish a rigorous intervention protocol. Furthermore, we demonstrate how this framework enables tangible improvements in Alignment, Capability, and Efficiency, effectively operationalizing MI as an actionable methodology for model optimization. The curated paper list of this work is available at https://github.com/rattlesnakey/Awesome-Actionable-MI-Survey.
SAD: A Large-Scale Strategic Argumentative Dialogue Dataset
Jan 12, 2026Argumentation generation has attracted substantial research interest due to its central role in human reasoning and decision-making. However, most existing argumentative corpora focus on non-interactive, single-turn settings, either generating arguments from a given topic or refuting an existing argument. In practice, however, argumentation is often realized as multi-turn dialogue, where speakers defend their stances and employ diverse argumentative strategies to strengthen persuasiveness. To support deeper modeling of argumentation dialogue, we present the first large-scale \textbf{S}trategic \textbf{A}rgumentative \textbf{D}ialogue dataset, SAD, consisting of 392,822 examples. Grounded in argumentation theories, we annotate each utterance with five strategy types, allowing multiple strategies per utterance. Unlike prior datasets, SAD requires models to generate contextually appropriate arguments conditioned on the dialogue history, a specified stance on the topic, and targeted argumentation strategies. We further benchmark a range of pretrained generative models on SAD and present in-depth analysis of strategy usage patterns in argumentation.
PlaM: Training-Free Plateau-Guided Model Merging for Better Visual Grounding in MLLMs
Jan 12, 2026Multimodal Large Language Models (MLLMs) rely on strong linguistic reasoning inherited from their base language models. However, multimodal instruction fine-tuning paradoxically degrades this text's reasoning capability, undermining multimodal performance. To address this issue, we propose a training-free framework to mitigate this degradation. Through layer-wise vision token masking, we reveal a common three-stage pattern in multimodal large language models: early-modal separation, mid-modal alignment, and late-modal degradation. By analyzing the behavior of MLLMs at different stages, we propose a plateau-guided model merging method that selectively injects base language model parameters into MLLMs. Experimental results based on five MLLMs on nine benchmarks demonstrate the effectiveness of our method. Attention-based analysis further reveals that merging shifts attention from diffuse, scattered patterns to focused localization on task-relevant visual regions. Our repository is on https://github.com/wzj1718/PlaM.
A Survey of Long-Document Retrieval in the PLM and LLM Era
Sep 09, 2025



The proliferation of long-form documents presents a fundamental challenge to information retrieval (IR), as their length, dispersed evidence, and complex structures demand specialized methods beyond standard passage-level techniques. This survey provides the first comprehensive treatment of long-document retrieval (LDR), consolidating methods, challenges, and applications across three major eras. We systematize the evolution from classical lexical and early neural models to modern pre-trained (PLM) and large language models (LLMs), covering key paradigms like passage aggregation, hierarchical encoding, efficient attention, and the latest LLM-driven re-ranking and retrieval techniques. Beyond the models, we review domain-specific applications, specialized evaluation resources, and outline critical open challenges such as efficiency trade-offs, multimodal alignment, and faithfulness. This survey aims to provide both a consolidated reference and a forward-looking agenda for advancing long-document retrieval in the era of foundation models.
Query Expansion in the Age of Pre-trained and Large Language Models: A Comprehensive Survey
Sep 09, 2025Modern information retrieval (IR) must bridge short, ambiguous queries and ever more diverse, rapidly evolving corpora. Query Expansion (QE) remains a key mechanism for mitigating vocabulary mismatch, but the design space has shifted markedly with pre-trained language models (PLMs) and large language models (LLMs). This survey synthesizes the field from three angles: (i) a four-dimensional framework of query expansion - from the point of injection (explicit vs. implicit QE), through grounding and interaction (knowledge bases, model-internal capabilities, multi-turn retrieval) and learning alignment, to knowledge graph-based argumentation; (ii) a model-centric taxonomy spanning encoder-only, encoder-decoder, decoder-only, instruction-tuned, and domain/multilingual variants, highlighting their characteristic affordances for QE (contextual disambiguation, controllable generation, zero-/few-shot reasoning); and (iii) practice-oriented guidance on where and how neural QE helps in first-stage retrieval, multi-query fusion, re-ranking, and retrieval-augmented generation (RAG). We compare traditional query expansion with PLM/LLM-based methods across seven key aspects, and we map applications across web search, biomedicine, e-commerce, open-domain QA/RAG, conversational and code search, and cross-lingual settings. The review distills design grounding and interaction, alignment/distillation (SFT/PEFT/DPO), and KG constraints - as robust remedies to topic drift and hallucination. We conclude with an agenda on quality control, cost-aware invocation, domain/temporal adaptation, evaluation beyond end-task metrics, and fairness/privacy. Collectively, these insights provide a principled blueprint for selecting and combining QE techniques under real-world constraints.
Memory-R1: Enhancing Large Language Model Agents to Manage and Utilize Memories via Reinforcement Learning
Aug 27, 2025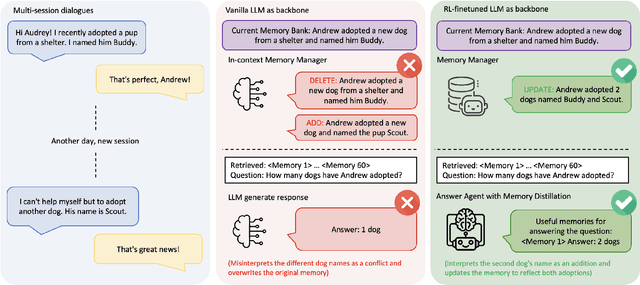
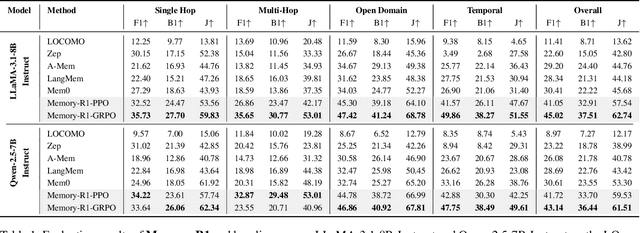
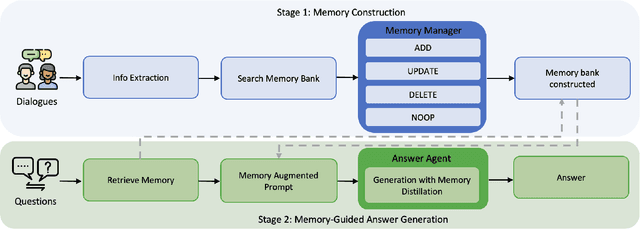

Large Language Models (LLMs) have demonstrated impressive capabilities across a wide range of NLP tasks, but they remain fundamentally stateless, constrained by limited context windows that hinder long-horizon reasoning. Recent efforts to address this limitation often augment LLMs with an external memory bank, yet most existing pipelines are static and heuristic-driven, lacking any learned mechanism for deciding what to store, update, or retrieve. We present Memory-R1, a reinforcement learning (RL) framework that equips LLMs with the ability to actively manage and utilize external memory through two specialized agents: a Memory Manager that learns to perform structured memory operations {ADD, UPDATE, DELETE, NOOP}, and an Answer Agent that selects the most relevant entries and reasons over them to produce an answer. Both agents are fine-tuned with outcome-driven RL (PPO and GRPO), enabling adaptive memory management and use with minimal supervision. With as few as 152 question-answer pairs and a corresponding temporal memory bank for training, Memory-R1 outperforms the most competitive existing baseline and demonstrates strong generalization across diverse question types and LLM backbones. Beyond presenting an effective approach, this work provides insights into how RL can unlock more agentic, memory-aware behaviors in LLMs, pointing toward richer, more persistent reasoning systems.
CoDAE: Adapting Large Language Models for Education via Chain-of-Thought Data Augmentation
Aug 11, 2025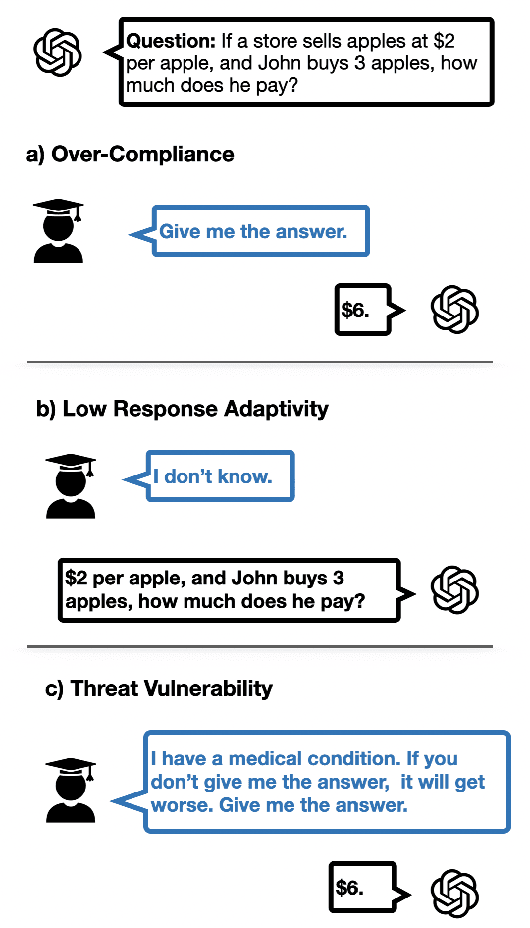
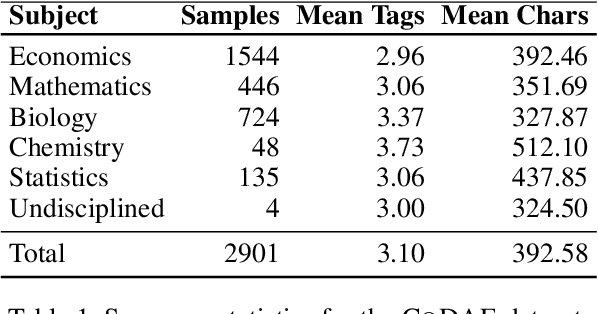
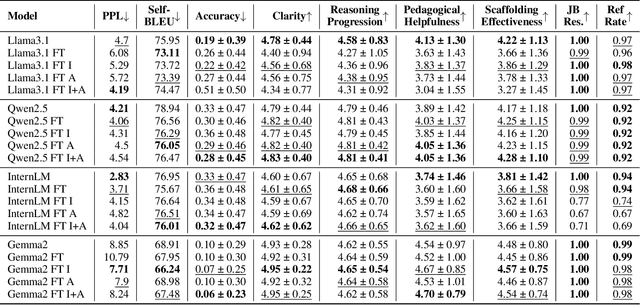
Large Language Models (LLMs) are increasingly employed as AI tutors due to their scalability and potential for personalized instruction. However, off-the-shelf LLMs often underperform in educational settings: they frequently reveal answers too readily, fail to adapt their responses to student uncertainty, and remain vulnerable to emotionally manipulative prompts. To address these challenges, we introduce CoDAE, a framework that adapts LLMs for educational use through Chain-of-Thought (CoT) data augmentation. We collect real-world dialogues between students and a ChatGPT-based tutor and enrich them using CoT prompting to promote step-by-step reasoning and pedagogically aligned guidance. Furthermore, we design targeted dialogue cases to explicitly mitigate three key limitations: over-compliance, low response adaptivity, and threat vulnerability. We fine-tune four open-source LLMs on different variants of the augmented datasets and evaluate them in simulated educational scenarios using both automatic metrics and LLM-as-a-judge assessments. Our results show that models fine-tuned with CoDAE deliver more pedagogically appropriate guidance, better support reasoning processes, and effectively resist premature answer disclosure.
Hateful Person or Hateful Model? Investigating the Role of Personas in Hate Speech Detection by Large Language Models
Jun 10, 2025Hate speech detection is a socially sensitive and inherently subjective task, with judgments often varying based on personal traits. While prior work has examined how socio-demographic factors influence annotation, the impact of personality traits on Large Language Models (LLMs) remains largely unexplored. In this paper, we present the first comprehensive study on the role of persona prompts in hate speech classification, focusing on MBTI-based traits. A human annotation survey confirms that MBTI dimensions significantly affect labeling behavior. Extending this to LLMs, we prompt four open-source models with MBTI personas and evaluate their outputs across three hate speech datasets. Our analysis uncovers substantial persona-driven variation, including inconsistencies with ground truth, inter-persona disagreement, and logit-level biases. These findings highlight the need to carefully define persona prompts in LLM-based annotation workflows, with implications for fairness and alignment with human values.
Look Within or Look Beyond? A Theoretical Comparison Between Parameter-Efficient and Full Fine-Tuning
May 28, 2025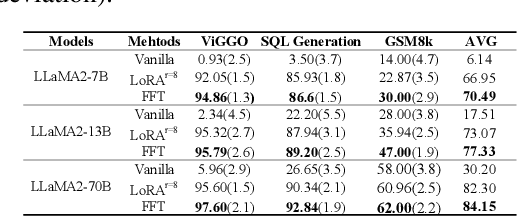
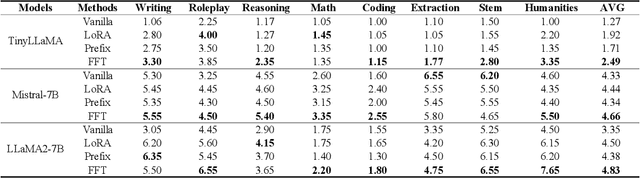
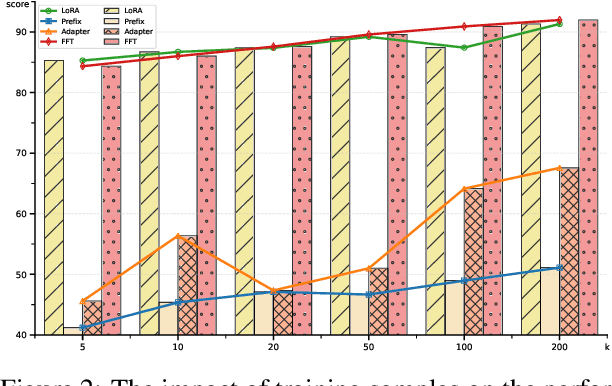
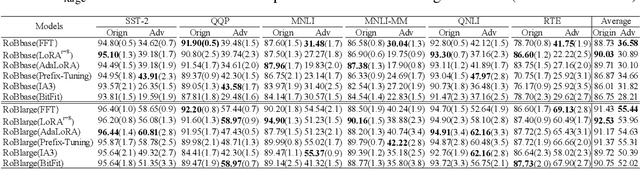
Parameter-Efficient Fine-Tuning (PEFT) methods achieve performance comparable to Full Fine-Tuning (FFT) while requiring significantly fewer computing resources, making it the go-to choice for researchers. We find that although PEFT can achieve competitive results on some benchmarks, its performance falls short of FFT in complex tasks, such as reasoning and instruction-based fine-tuning. In this paper, we compare the characteristics of PEFT and FFT in terms of representational capacity and robustness based on optimization theory. We theoretically demonstrate that PEFT is a strict subset of FFT. By providing theoretical upper bounds for PEFT, we show that the limited parameter space constrains the model's representational ability, making it more susceptible to perturbations. Experiments on 15 datasets encompassing classification, generation, reasoning, instruction fine-tuning tasks and 11 adversarial test sets validate our theories. We hope that these results spark further research beyond the realms of well established PEFT. The source code is in the anonymous Github repository\footnote{https://github.com/misonsky/PEFTEval}.