 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNEAT: Neuron-Based Early Exit for Large Reasoning Models
Feb 02, 2026Large Reasoning Models (LRMs) often suffer from \emph{overthinking}, a phenomenon in which redundant reasoning steps are generated after a correct solution has already been reached. Existing early reasoning exit methods primarily rely on output-level heuristics or trained probing models to skip redundant reasoning steps, thereby mitigating overthinking. However, these approaches typically require additional rollout computation or externally labeled datasets. In this paper, we propose \textbf{NEAT}, a \textbf{N}euron-based \textbf{E}arly re\textbf{A}soning exi\textbf{T} framework that monitors neuron-level activation dynamics to enable training-free early exits, without introducing additional test-time computation. NEAT identifies exit-associated neurons and tracks their activation patterns during reasoning to dynamically trigger early exit or suppress reflection, thereby reducing unnecessary reasoning while preserving solution quality. Experiments on four reasoning benchmarks across six models with different scales and architectures show that, for each model, NEAT achieves an average token reduction of 22\% to 28\% when averaged over the four benchmarks, while maintaining accuracy.
PlaM: Training-Free Plateau-Guided Model Merging for Better Visual Grounding in MLLMs
Jan 12, 2026Multimodal Large Language Models (MLLMs) rely on strong linguistic reasoning inherited from their base language models. However, multimodal instruction fine-tuning paradoxically degrades this text's reasoning capability, undermining multimodal performance. To address this issue, we propose a training-free framework to mitigate this degradation. Through layer-wise vision token masking, we reveal a common three-stage pattern in multimodal large language models: early-modal separation, mid-modal alignment, and late-modal degradation. By analyzing the behavior of MLLMs at different stages, we propose a plateau-guided model merging method that selectively injects base language model parameters into MLLMs. Experimental results based on five MLLMs on nine benchmarks demonstrate the effectiveness of our method. Attention-based analysis further reveals that merging shifts attention from diffuse, scattered patterns to focused localization on task-relevant visual regions. Our repository is on https://github.com/wzj1718/PlaM.
SAD: A Large-Scale Strategic Argumentative Dialogue Dataset
Jan 12, 2026Argumentation generation has attracted substantial research interest due to its central role in human reasoning and decision-making. However, most existing argumentative corpora focus on non-interactive, single-turn settings, either generating arguments from a given topic or refuting an existing argument. In practice, however, argumentation is often realized as multi-turn dialogue, where speakers defend their stances and employ diverse argumentative strategies to strengthen persuasiveness. To support deeper modeling of argumentation dialogue, we present the first large-scale \textbf{S}trategic \textbf{A}rgumentative \textbf{D}ialogue dataset, SAD, consisting of 392,822 examples. Grounded in argumentation theories, we annotate each utterance with five strategy types, allowing multiple strategies per utterance. Unlike prior datasets, SAD requires models to generate contextually appropriate arguments conditioned on the dialogue history, a specified stance on the topic, and targeted argumentation strategies. We further benchmark a range of pretrained generative models on SAD and present in-depth analysis of strategy usage patterns in argumentation.
High-Rank Structured Modulation for Parameter-Efficient Fine-Tuning
Jan 12, 2026As the number of model parameters increases, parameter-efficient fine-tuning (PEFT) has become the go-to choice for tailoring pre-trained large language models. Low-rank Adaptation (LoRA) uses a low-rank update method to simulate full parameter fine-tuning, which is widely used to reduce resource requirements. However, decreasing the rank encounters challenges with limited representational capacity when compared to full parameter fine-tuning. We present \textbf{SMoA}, a high-rank \textbf{S}tructured \textbf{MO}dulation \textbf{A}dapter that uses fewer trainable parameters while maintaining a higher rank, thereby improving the model's representational capacity and offering improved performance potential. The core idea is to freeze the original pretrained weights and selectively amplify or suppress important features of the original weights across multiple subspaces. The subspace mechanism provides an efficient way to increase the capacity and complexity of a model. We conduct both theoretical analyses and empirical studies on various tasks. Experiment results show that SMoA outperforms LoRA and its variants on 10 tasks, with extensive ablation studies validating its effectiveness.
SAFE-QAQ: End-to-End Slow-Thinking Audio-Text Fraud Detection via Reinforcement Learning
Jan 04, 2026Existing fraud detection methods predominantly rely on transcribed text, suffering from ASR errors and missing crucial acoustic cues like vocal tone and environmental context. This limits their effectiveness against complex deceptive strategies. To address these challenges, we first propose \textbf{SAFE-QAQ}, an end-to-end comprehensive framework for audio-based slow-thinking fraud detection. First, the SAFE-QAQ framework eliminates the impact of transcription errors on detection performance. Secondly, we propose rule-based slow-thinking reward mechanisms that systematically guide the system to identify fraud-indicative patterns by accurately capturing fine-grained audio details, through hierarchical reasoning processes. Besides, our framework introduces a dynamic risk assessment framework during live calls, enabling early detection and prevention of fraud. Experiments on the TeleAntiFraud-Bench demonstrate that SAFE-QAQ achieves dramatic improvements over existing methods in multiple key dimensions, including accuracy, inference efficiency, and real-time processing capabilities. Currently deployed and analyzing over 70,000 calls daily, SAFE-QAQ effectively automates complex fraud detection, reducing human workload and financial losses. Code: https://anonymous.4open.science/r/SAFE-QAQ.
Every Step Evolves: Scaling Reinforcement Learning for Trillion-Scale Thinking Model
Oct 21, 2025



We present Ring-1T, the first open-source, state-of-the-art thinking model with a trillion-scale parameter. It features 1 trillion total parameters and activates approximately 50 billion per token. Training such models at a trillion-parameter scale introduces unprecedented challenges, including train-inference misalignment, inefficiencies in rollout processing, and bottlenecks in the RL system. To address these, we pioneer three interconnected innovations: (1) IcePop stabilizes RL training via token-level discrepancy masking and clipping, resolving instability from training-inference mismatches; (2) C3PO++ improves resource utilization for long rollouts under a token budget by dynamically partitioning them, thereby obtaining high time efficiency; and (3) ASystem, a high-performance RL framework designed to overcome the systemic bottlenecks that impede trillion-parameter model training. Ring-1T delivers breakthrough results across critical benchmarks: 93.4 on AIME-2025, 86.72 on HMMT-2025, 2088 on CodeForces, and 55.94 on ARC-AGI-v1. Notably, it attains a silver medal-level result on the IMO-2025, underscoring its exceptional reasoning capabilities. By releasing the complete 1T parameter MoE model to the community, we provide the research community with direct access to cutting-edge reasoning capabilities. This contribution marks a significant milestone in democratizing large-scale reasoning intelligence and establishes a new baseline for open-source model performance.
Ring-lite: Scalable Reasoning via C3PO-Stabilized Reinforcement Learning for LLMs
Jun 18, 2025We present Ring-lite, a Mixture-of-Experts (MoE)-based large language model optimized via reinforcement learning (RL) to achieve efficient and robust reasoning capabilities. Built upon the publicly available Ling-lite model, a 16.8 billion parameter model with 2.75 billion activated parameters, our approach matches the performance of state-of-the-art (SOTA) small-scale reasoning models on challenging benchmarks (e.g., AIME, LiveCodeBench, GPQA-Diamond) while activating only one-third of the parameters required by comparable models. To accomplish this, we introduce a joint training pipeline integrating distillation with RL, revealing undocumented challenges in MoE RL training. First, we identify optimization instability during RL training, and we propose Constrained Contextual Computation Policy Optimization(C3PO), a novel approach that enhances training stability and improves computational throughput via algorithm-system co-design methodology. Second, we empirically demonstrate that selecting distillation checkpoints based on entropy loss for RL training, rather than validation metrics, yields superior performance-efficiency trade-offs in subsequent RL training. Finally, we develop a two-stage training paradigm to harmonize multi-domain data integration, addressing domain conflicts that arise in training with mixed dataset. We will release the model, dataset, and code.
Look Within or Look Beyond? A Theoretical Comparison Between Parameter-Efficient and Full Fine-Tuning
May 28, 2025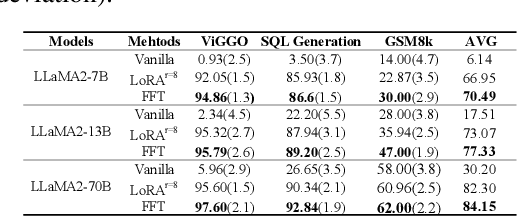
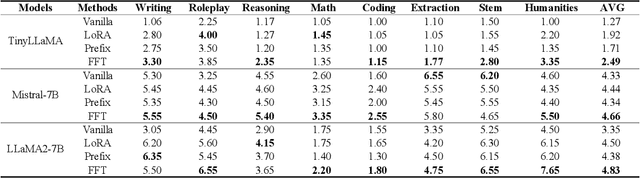
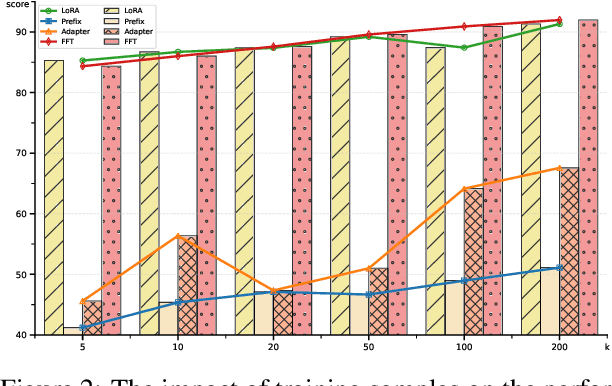
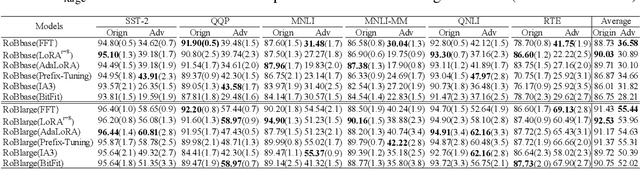
Parameter-Efficient Fine-Tuning (PEFT) methods achieve performance comparable to Full Fine-Tuning (FFT) while requiring significantly fewer computing resources, making it the go-to choice for researchers. We find that although PEFT can achieve competitive results on some benchmarks, its performance falls short of FFT in complex tasks, such as reasoning and instruction-based fine-tuning. In this paper, we compare the characteristics of PEFT and FFT in terms of representational capacity and robustness based on optimization theory. We theoretically demonstrate that PEFT is a strict subset of FFT. By providing theoretical upper bounds for PEFT, we show that the limited parameter space constrains the model's representational ability, making it more susceptible to perturbations. Experiments on 15 datasets encompassing classification, generation, reasoning, instruction fine-tuning tasks and 11 adversarial test sets validate our theories. We hope that these results spark further research beyond the realms of well established PEFT. The source code is in the anonymous Github repository\footnote{https://github.com/misonsky/PEFTEval}.
Why Do More Experts Fail? A Theoretical Analysis of Model Merging
May 27, 2025
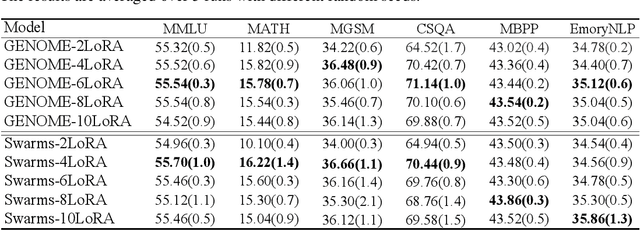


Model merging dramatically reduces storage and computational resources by combining multiple expert models into a single multi-task model. Although recent model merging methods have shown promising results, they struggle to maintain performance gains as the number of merged models increases. In this paper, we investigate the key obstacles that limit the scalability of model merging when integrating a large number of expert models. First, we prove that there is an upper bound on model merging. Further theoretical analysis reveals that the limited effective parameter space imposes a strict constraint on the number of models that can be successfully merged. Gaussian Width shows that the marginal benefit of merging additional models diminishes according to a strictly concave function. This implies that the effective parameter space becomes rapidly saturated as the number of merged models increases. Furthermore, using Approximate Kinematics Theory, we prove the existence of a unique optimal threshold beyond which adding more models does not yield significant performance improvements. At the same time, we introduce a straightforward Reparameterized Heavy-Tailed method (RHT) to extend the coverage of the merged model, thereby enhancing its performance. Empirical results on 12 benchmarks, including both knowledge-intensive and general-purpose tasks, validate our theoretical analysis. We believe that these results spark further research beyond the current scope of model merging. The source code is in the anonymous Github repository https://github.com/wzj1718/ModelMergingAnalysis.
Enhancing LLM-based Recommendation through Semantic-Aligned Collaborative Knowledge
Apr 14, 2025Large Language Models (LLMs) demonstrate remarkable capabilities in leveraging comprehensive world knowledge and sophisticated reasoning mechanisms for recommendation tasks. However, a notable limitation lies in their inability to effectively model sparse identifiers (e.g., user and item IDs), unlike conventional collaborative filtering models (Collabs.), thus hindering LLM to learn distinctive user-item representations and creating a performance bottleneck. Prior studies indicate that integrating collaborative knowledge from Collabs. into LLMs can mitigate the above limitations and enhance their recommendation performance. Nevertheless, the significant discrepancy in knowledge distribution and semantic space between LLMs and Collab. presents substantial challenges for effective knowledge transfer. To tackle these challenges, we propose a novel framework, SeLLa-Rec, which focuses on achieving alignment between the semantic spaces of Collabs. and LLMs. This alignment fosters effective knowledge fusion, mitigating the influence of discriminative noise and facilitating the deep integration of knowledge from diverse models. Specifically, three special tokens with collaborative knowledge are embedded into the LLM's semantic space through a hybrid projection layer and integrated into task-specific prompts to guide the recommendation process. Experiments conducted on two public benchmark datasets (MovieLens-1M and Amazon Book) demonstrate that SeLLa-Rec achieves state-of-the-art performance.