 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCooperverse: A Mobile-Edge-Cloud Framework for Universal Cooperative Perception with Mixed Connectivity and Automation
Feb 06, 2023Cooperative perception (CP) is attracting increasing attention and is regarded as the core foundation to support cooperative driving automation, a potential key solution to addressing the safety, mobility, and sustainability issues of contemporary transportation systems. However, current research on CP is still at the beginning stages where a systematic problem formulation of CP is still missing, acting as the essential guideline of the system design of a CP system under real-world situations. In this paper, we formulate a universal CP system into an optimization problem and a mobile-edge-cloud framework called Cooperverse. This system addresses CP in a mixed connectivity and automation environment. A Dynamic Feature Sharing (DFS) methodology is introduced to support this CP system under certain constraints and a Random Priority Filtering (RPF) method is proposed to conduct DFS with high performance. Experiments have been conducted based on a high-fidelity CP platform, and the results show that the Cooperverse framework is effective for dynamic node engagement and the proposed DFS methodology can improve system CP performance by 14.5% and the RPF method can reduce the communication cost for mobile nodes by 90% with only 1.7% drop for average precision.
VINet: Lightweight, Scalable, and Heterogeneous Cooperative Perception for 3D Object Detection
Dec 14, 2022Utilizing the latest advances in Artificial Intelligence (AI), the computer vision community is now witnessing an unprecedented evolution in all kinds of perception tasks, particularly in object detection. Based on multiple spatially separated perception nodes, Cooperative Perception (CP) has emerged to significantly advance the perception of automated driving. However, current cooperative object detection methods mainly focus on ego-vehicle efficiency without considering the practical issues of system-wide costs. In this paper, we introduce VINet, a unified deep learning-based CP network for scalable, lightweight, and heterogeneous cooperative 3D object detection. VINet is the first CP method designed from the standpoint of large-scale system-level implementation and can be divided into three main phases: 1) Global Pre-Processing and Lightweight Feature Extraction which prepare the data into global style and extract features for cooperation in a lightweight manner; 2) Two-Stream Fusion which fuses the features from scalable and heterogeneous perception nodes; and 3) Central Feature Backbone and 3D Detection Head which further process the fused features and generate cooperative detection results. A cooperative perception platform is designed and developed for CP dataset acquisition and several baselines are compared during the experiments. The experimental analysis shows that VINet can achieve remarkable improvements for pedestrians and cars with 2x less system-wide computational costs and 12x less system-wide communicational costs.
A Survey and Framework of Cooperative Perception: From Heterogeneous Singleton to Hierarchical Cooperation
Aug 22, 2022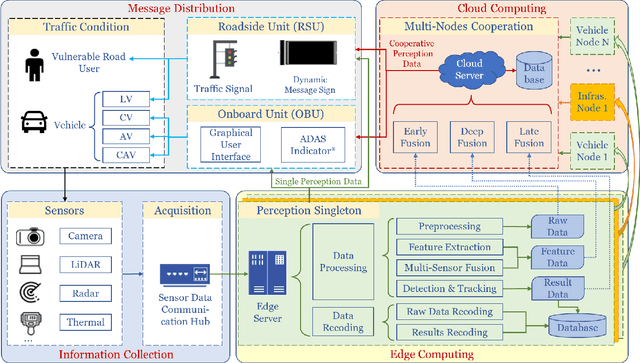
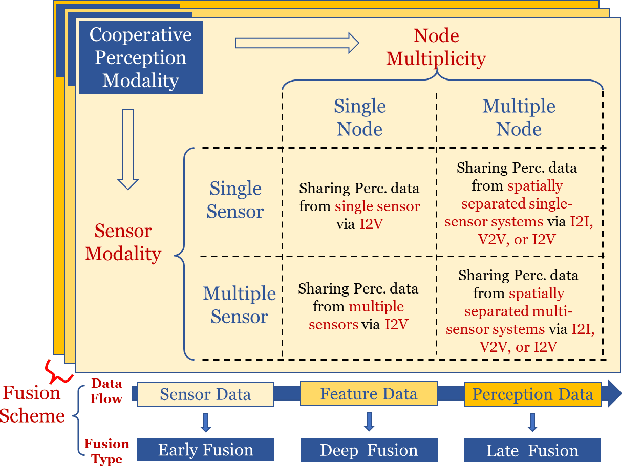
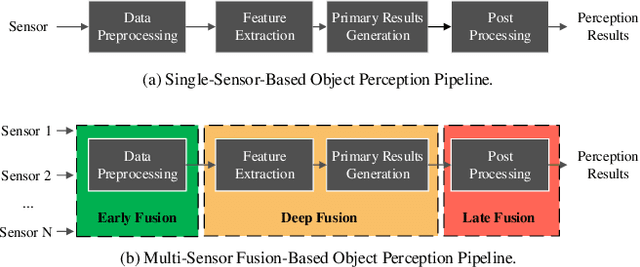
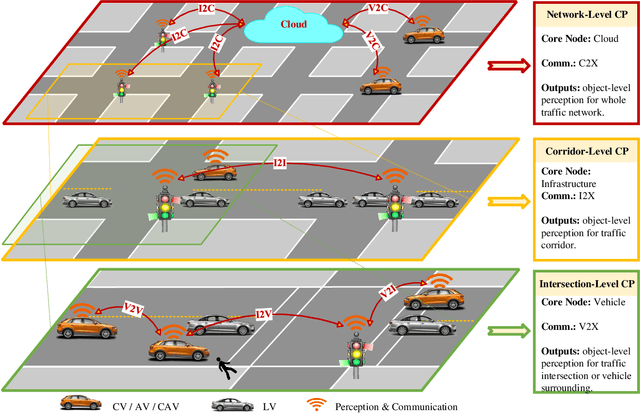
Perceiving the environment is one of the most fundamental keys to enabling Cooperative Driving Automation (CDA), which is regarded as the revolutionary solution to addressing the safety, mobility, and sustainability issues of contemporary transportation systems. Although an unprecedented evolution is now happening in the area of computer vision for object perception, state-of-the-art perception methods are still struggling with sophisticated real-world traffic environments due to the inevitably physical occlusion and limited receptive field of single-vehicle systems. Based on multiple spatially separated perception nodes, Cooperative Perception (CP) is born to unlock the bottleneck of perception for driving automation. In this paper, we comprehensively review and analyze the research progress on CP and, to the best of our knowledge, this is the first time to propose a unified CP framework. Architectures and taxonomy of CP systems based on different types of sensors are reviewed to show a high-level description of the workflow and different structures for CP systems. Node structure, sensor modality, and fusion schemes are reviewed and analyzed with comprehensive literature to provide detailed explanations of specific methods. A Hierarchical CP framework is proposed, followed by a review of existing Datasets and Simulators to sketch an overall landscape of CP. Discussion highlights the current opportunities, open challenges, and anticipated future trends.
Cyber Mobility Mirror: A Deep Learning-based Real-World Object Perception Platform Using Roadside LiDAR
Apr 07, 2022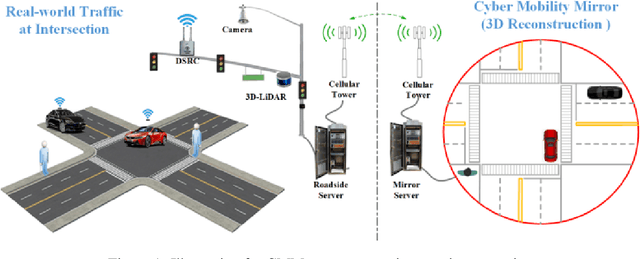
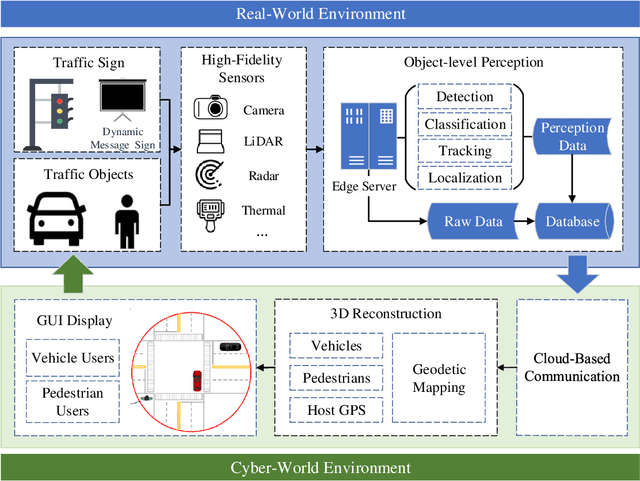
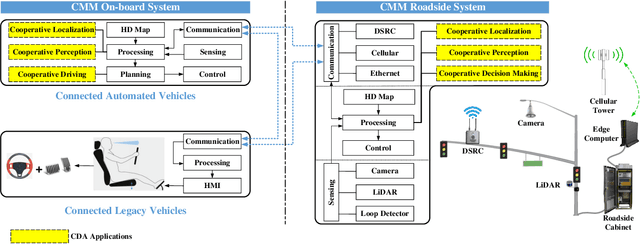
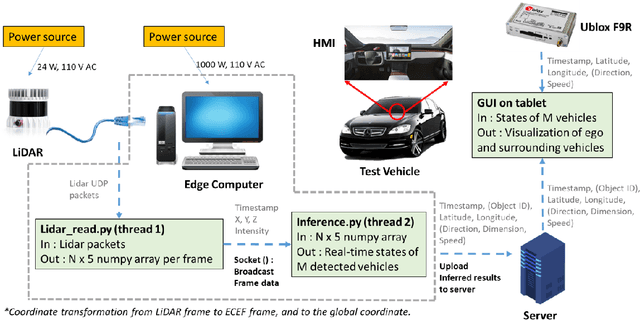
Object perception plays a fundamental role in Cooperative Driving Automation (CDA) which is regarded as a revolutionary promoter for the next-generation transportation systems. However, the vehicle-based perception may suffer from the limited sensing range and occlusion as well as low penetration rates in connectivity. In this paper, we propose Cyber Mobility Mirror (CMM), a next-generation real-time traffic surveillance system for 3D object perception and reconstruction, to explore the potential of roadside sensors for enabling CDA in the real world. The CMM system consists of six main components: 1) the data pre-processor to retrieve and preprocess the raw data; 2) the roadside 3D object detector to generate 3D detection results; 3) the multi-object tracker to identify detected objects; 4) the global locator to map positioning information from the LiDAR coordinate to geographic coordinate using coordinate transformation; 5) the cloud-based communicator to transmit perception information from roadside sensors to equipped vehicles, and 6) the onboard advisor to reconstruct and display the real-time traffic conditions via Graphical User Interface (GUI). In this study, a field-operational system is deployed at a real-world intersection, University Avenue and Iowa Avenue in Riverside, California to assess the feasibility and performance of our CMM system. Results from field tests demonstrate that our CMM prototype system can provide satisfactory perception performance with 96.99% precision and 83.62% recall. High-fidelity real-time traffic conditions (at the object level) can be geo-localized with an average error of 0.14m and displayed on the GUI of the equipped vehicle with a frequency of 3-4 Hz.
PillarGrid: Deep Learning-based Cooperative Perception for 3D Object Detection from Onboard-Roadside LiDAR
Mar 19, 2022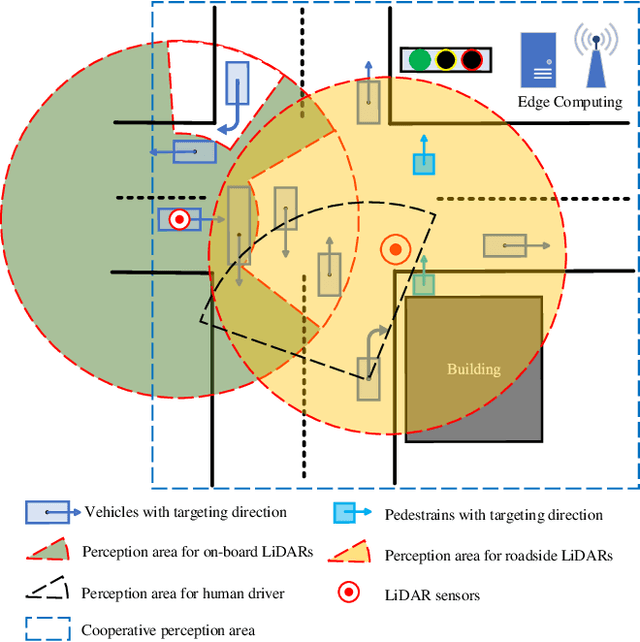
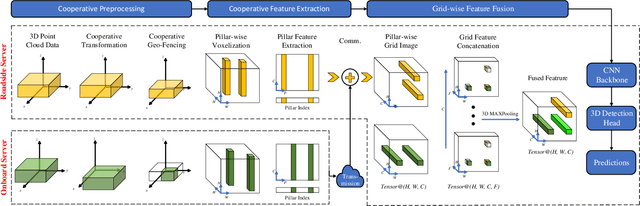
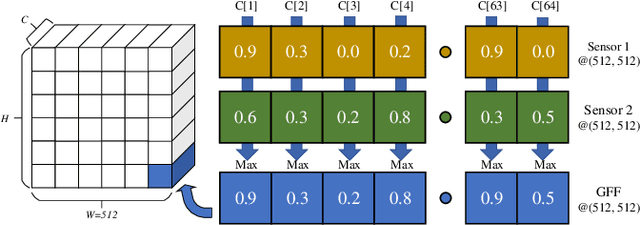
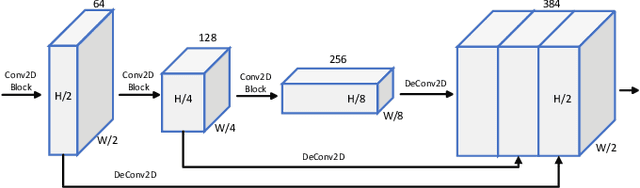
3D object detection plays a fundamental role in enabling autonomous driving, which is regarded as the significant key to unlocking the bottleneck of contemporary transportation systems from the perspectives of safety, mobility, and sustainability. Most of the state-of-the-art (SOTA) object detection methods from point clouds are developed based on a single onboard LiDAR, whose performance will be inevitably limited by the range and occlusion, especially in dense traffic scenarios. In this paper, we propose \textit{PillarGrid}, a novel cooperative perception method fusing information from multiple 3D LiDARs (both on-board and roadside), to enhance the situation awareness for connected and automated vehicles (CAVs). PillarGrid consists of four main phases: 1) cooperative preprocessing of point clouds, 2) pillar-wise voxelization and feature extraction, 3) grid-wise deep fusion of features from multiple sensors, and 4) convolutional neural network (CNN)-based augmented 3D object detection. A novel cooperative perception platform is developed for model training and testing. Extensive experimentation shows that PillarGrid outperforms the SOTA single-LiDAR-based 3D object detection methods with respect to both accuracy and range by a large margin.