 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforcement Learning with Latent State Inference for Autonomous On-ramp Merging under Observation Delay
Mar 19, 2024



This paper presents a novel approach to address the challenging problem of autonomous on-ramp merging, where a self-driving vehicle needs to seamlessly integrate into a flow of vehicles on a multi-lane highway. We introduce the Lane-keeping, Lane-changing with Latent-state Inference and Safety Controller (L3IS) agent, designed to perform the on-ramp merging task safely without comprehensive knowledge about surrounding vehicles' intents or driving styles. We also present an augmentation of this agent called AL3IS that accounts for observation delays, allowing the agent to make more robust decisions in real-world environments with vehicle-to-vehicle (V2V) communication delays. By modeling the unobservable aspects of the environment through latent states, such as other drivers' intents, our approach enhances the agent's ability to adapt to dynamic traffic conditions, optimize merging maneuvers, and ensure safe interactions with other vehicles. We demonstrate the effectiveness of our method through extensive simulations generated from real traffic data and compare its performance with existing approaches. L3IS shows a 99.90% success rate in a challenging on-ramp merging case generated from the real US Highway 101 data. We further perform a sensitivity analysis on AL3IS to evaluate its robustness against varying observation delays, which demonstrates an acceptable performance of 93.84% success rate in 1-second V2V communication delay.
Continuous Layout Editing of Single Images with Diffusion Models
Jun 22, 2023Recent advancements in large-scale text-to-image diffusion models have enabled many applications in image editing. However, none of these methods have been able to edit the layout of single existing images. To address this gap, we propose the first framework for layout editing of a single image while preserving its visual properties, thus allowing for continuous editing on a single image. Our approach is achieved through two key modules. First, to preserve the characteristics of multiple objects within an image, we disentangle the concepts of different objects and embed them into separate textual tokens using a novel method called masked textual inversion. Next, we propose a training-free optimization method to perform layout control for a pre-trained diffusion model, which allows us to regenerate images with learned concepts and align them with user-specified layouts. As the first framework to edit the layout of existing images, we demonstrate that our method is effective and outperforms other baselines that were modified to support this task. Our code will be freely available for public use upon acceptance.
UniColor: A Unified Framework for Multi-Modal Colorization with Transformer
Sep 22, 2022

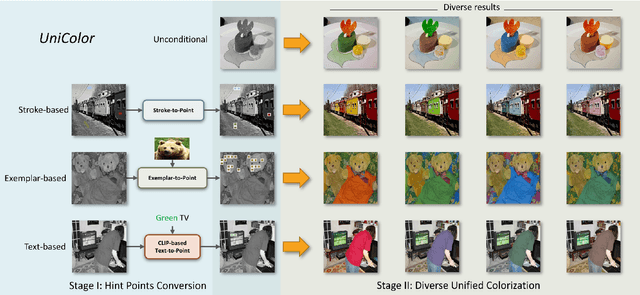
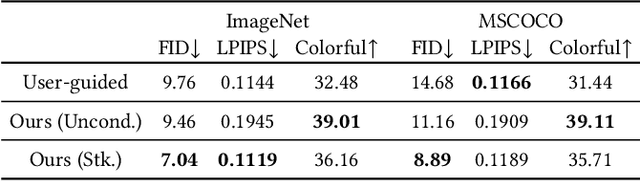
We propose the first unified framework UniColor to support colorization in multiple modalities, including both unconditional and conditional ones, such as stroke, exemplar, text, and even a mix of them. Rather than learning a separate model for each type of condition, we introduce a two-stage colorization framework for incorporating various conditions into a single model. In the first stage, multi-modal conditions are converted into a common representation of hint points. Particularly, we propose a novel CLIP-based method to convert the text to hint points. In the second stage, we propose a Transformer-based network composed of Chroma-VQGAN and Hybrid-Transformer to generate diverse and high-quality colorization results conditioned on hint points. Both qualitative and quantitative comparisons demonstrate that our method outperforms state-of-the-art methods in every control modality and further enables multi-modal colorization that was not feasible before. Moreover, we design an interactive interface showing the effectiveness of our unified framework in practical usage, including automatic colorization, hybrid-control colorization, local recolorization, and iterative color editing. Our code and models are available at https://luckyhzt.github.io/unicolor.
A Survey and Framework of Cooperative Perception: From Heterogeneous Singleton to Hierarchical Cooperation
Aug 22, 2022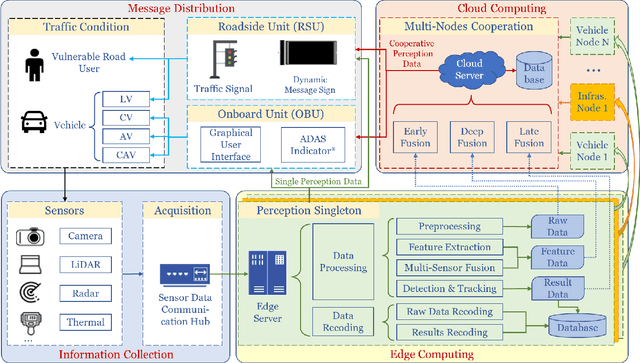
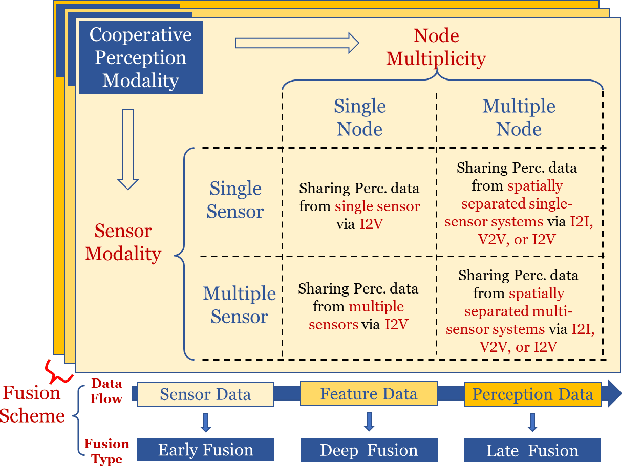
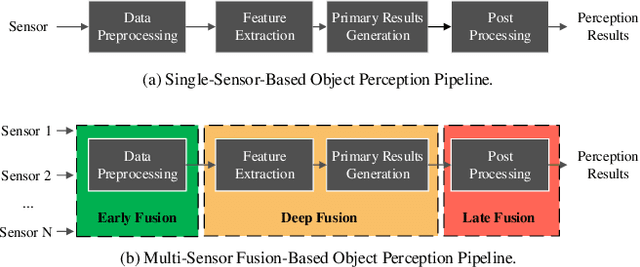
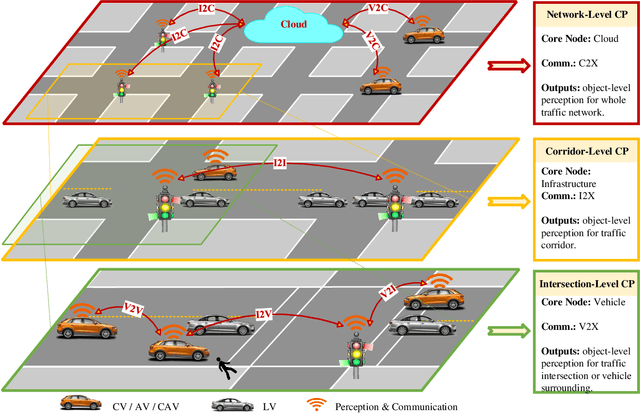
Perceiving the environment is one of the most fundamental keys to enabling Cooperative Driving Automation (CDA), which is regarded as the revolutionary solution to addressing the safety, mobility, and sustainability issues of contemporary transportation systems. Although an unprecedented evolution is now happening in the area of computer vision for object perception, state-of-the-art perception methods are still struggling with sophisticated real-world traffic environments due to the inevitably physical occlusion and limited receptive field of single-vehicle systems. Based on multiple spatially separated perception nodes, Cooperative Perception (CP) is born to unlock the bottleneck of perception for driving automation. In this paper, we comprehensively review and analyze the research progress on CP and, to the best of our knowledge, this is the first time to propose a unified CP framework. Architectures and taxonomy of CP systems based on different types of sensors are reviewed to show a high-level description of the workflow and different structures for CP systems. Node structure, sensor modality, and fusion schemes are reviewed and analyzed with comprehensive literature to provide detailed explanations of specific methods. A Hierarchical CP framework is proposed, followed by a review of existing Datasets and Simulators to sketch an overall landscape of CP. Discussion highlights the current opportunities, open challenges, and anticipated future trends.