 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVISA: VLM-Guided Instance Semantic Auditing for 3D Occupancy World Models
Jun 11, 2026Semantic 3D occupancy provides a voxelized world state for autonomous driving and robot decision making, but object and rare-class errors can affect free-space interpretation, collision checking, and temporal state propagation. We show that a common VLM strategy, aligning 3D voxel or object features with crop-caption embeddings, improves text-space similarity without reliably improving closed-set occupancy mIoU. Motivated by this mismatch, we propose VISA, a training-time semantic auditing approach for existing occupancy world models. VISA queries an offline VLM on a representative crop of each physical object instance, obtains a structured audit with class hypotheses, plausible confusions, reliability, attributes, and evidence, and propagates it along the object track. The audit is grounded to matched 3D object voxels and distilled into semantic logits through reliability-weighted taxonomy, attribute-factor, and scene-level audit graph losses, while inference remains unchanged and requires no VLM. On nuScenes, averaged across three runs, VISA improves OccWorld from 19.06 to 20.05 mIoU and GaussianWorld from 21.36 to 21.91 mIoU; on GaussianWorld, object mIoU improves from 18.18 to 19.16 and rare-class mIoU from 15.60 to 16.79. These results suggest that VLMs are better suited to closed-set occupancy as reliability-aware semantic auditors than as generic caption-embedding targets.
GaussianSSC: Triplane-Guided Directional Gaussian Fields for 3D Semantic Completion
Mar 23, 2026We present \emph{GaussianSSC}, a two-stage, grid-native and triplane-guided approach to semantic scene completion (SSC) that injects the benefits of Gaussians without replacing the voxel grid or maintaining a separate Gaussian set. We introduce \emph{Gaussian Anchoring}, a sub-pixel, Gaussian-weighted image aggregation over fused FPN features that tightens voxel--image alignment and improves monocular occupancy estimation. We further convert point-like voxel features into a learned per-voxel Gaussian field and refine triplane features via a triplane-aligned \emph{Gaussian--Triplane Refinement} module that combines \emph{local gathering} (target-centric) and \emph{global aggregation} (source-centric). This directional, anisotropic support captures surface tangency, scale, and occlusion-aware asymmetry while preserving the efficiency of triplane representations. On SemanticKITTI~\cite{behley2019semantickitti}, GaussianSSC improves Stage~1 occupancy by +1.0\% Recall, +2.0\% Precision, and +1.8\% IoU over state-of-the-art baselines, and improves Stage~2 semantic prediction by +1.8\% IoU and +0.8\% mIoU.
HomeEmergency -- Using Audio to Find and Respond to Emergencies in the Home
Apr 01, 2025



In the United States alone accidental home deaths exceed 128,000 per year. Our work aims to enable home robots who respond to emergency scenarios in the home, preventing injuries and deaths. We introduce a new dataset of household emergencies based in the ThreeDWorld simulator. Each scenario in our dataset begins with an instantaneous or periodic sound which may or may not be an emergency. The agent must navigate the multi-room home scene using prior observations, alongside audio signals and images from the simulator, to determine if there is an emergency or not. In addition to our new dataset, we present a modular approach for localizing and identifying potential home emergencies. Underpinning our approach is a novel probabilistic dynamic scene graph (P-DSG), where our key insight is that graph nodes corresponding to agents can be represented with a probabilistic edge. This edge, when refined using Bayesian inference, enables efficient and effective localization of agents in the scene. We also utilize multi-modal vision-language models (VLMs) as a component in our approach, determining object traits (e.g. flammability) and identifying emergencies. We present a demonstration of our method completing a real-world version of our task on a consumer robot, showing the transferability of both our task and our method. Our dataset will be released to the public upon this papers publication.
ET-Former: Efficient Triplane Deformable Attention for 3D Semantic Scene Completion From Monocular Camera
Oct 14, 2024



We introduce ET-Former, a novel end-to-end algorithm for semantic scene completion using a single monocular camera. Our approach generates a semantic occupancy map from single RGB observation while simultaneously providing uncertainty estimates for semantic predictions. By designing a triplane-based deformable attention mechanism, our approach improves geometric understanding of the scene than other SOTA approaches and reduces noise in semantic predictions. Additionally, through the use of a Conditional Variational AutoEncoder (CVAE), we estimate the uncertainties of these predictions. The generated semantic and uncertainty maps will aid in the formulation of navigation strategies that facilitate safe and permissible decision-making in the future. Evaluated on the Semantic-KITTI dataset, ET-Former achieves the highest IoU and mIoU, surpassing other methods by 15.16% in IoU and 24.24% in mIoU, while reducing GPU memory usage of existing methods by 25%-50.5%.
Learning to View: Decision Transformers for Active Object Detection
Jan 23, 2023



Active perception describes a broad class of techniques that couple planning and perception systems to move the robot in a way to give the robot more information about the environment. In most robotic systems, perception is typically independent of motion planning. For example, traditional object detection is passive: it operates only on the images it receives. However, we have a chance to improve the results if we allow planning to consume detection signals and move the robot to collect views that maximize the quality of the results. In this paper, we use reinforcement learning (RL) methods to control the robot in order to obtain images that maximize the detection quality. Specifically, we propose using a Decision Transformer with online fine-tuning, which first optimizes the policy with a pre-collected expert dataset and then improves the learned policy by exploring better solutions in the environment. We evaluate the performance of proposed method on an interactive dataset collected from an indoor scenario simulator. Experimental results demonstrate that our method outperforms all baselines, including expert policy and pure offline RL methods. We also provide exhaustive analyses of the reward distribution and observation space.
Cyber Mobility Mirror: A Deep Learning-based Real-World Object Perception Platform Using Roadside LiDAR
Apr 07, 2022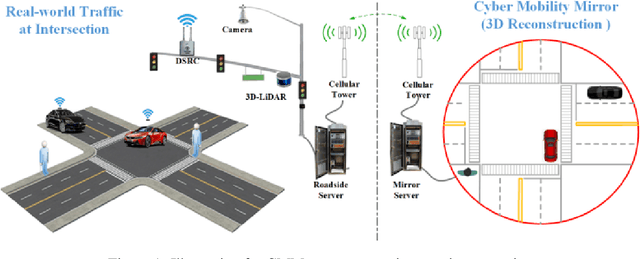
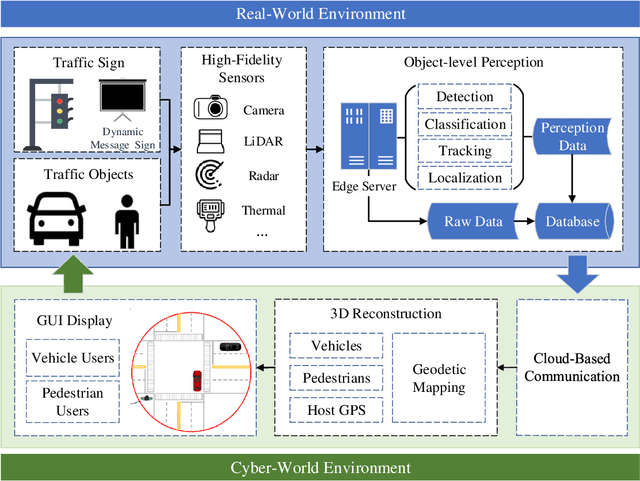
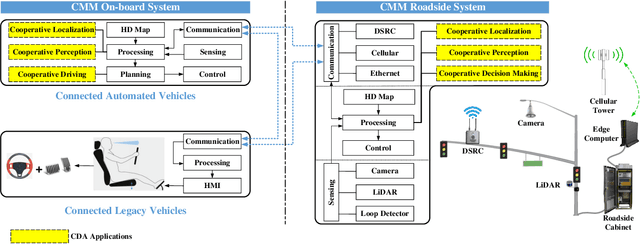
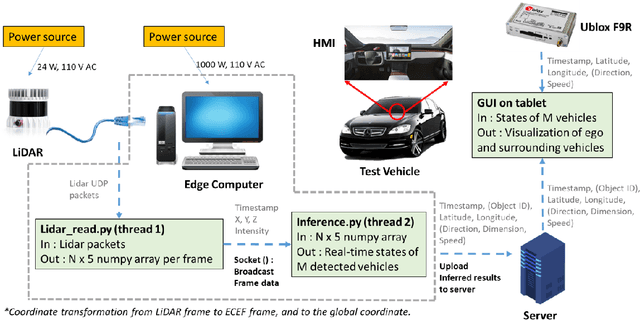
Object perception plays a fundamental role in Cooperative Driving Automation (CDA) which is regarded as a revolutionary promoter for the next-generation transportation systems. However, the vehicle-based perception may suffer from the limited sensing range and occlusion as well as low penetration rates in connectivity. In this paper, we propose Cyber Mobility Mirror (CMM), a next-generation real-time traffic surveillance system for 3D object perception and reconstruction, to explore the potential of roadside sensors for enabling CDA in the real world. The CMM system consists of six main components: 1) the data pre-processor to retrieve and preprocess the raw data; 2) the roadside 3D object detector to generate 3D detection results; 3) the multi-object tracker to identify detected objects; 4) the global locator to map positioning information from the LiDAR coordinate to geographic coordinate using coordinate transformation; 5) the cloud-based communicator to transmit perception information from roadside sensors to equipped vehicles, and 6) the onboard advisor to reconstruct and display the real-time traffic conditions via Graphical User Interface (GUI). In this study, a field-operational system is deployed at a real-world intersection, University Avenue and Iowa Avenue in Riverside, California to assess the feasibility and performance of our CMM system. Results from field tests demonstrate that our CMM prototype system can provide satisfactory perception performance with 96.99% precision and 83.62% recall. High-fidelity real-time traffic conditions (at the object level) can be geo-localized with an average error of 0.14m and displayed on the GUI of the equipped vehicle with a frequency of 3-4 Hz.
Spatiotemporal Transformer Attention Network for 3D Voxel Level Joint Segmentation and Motion Prediction in Point Cloud
Feb 28, 2022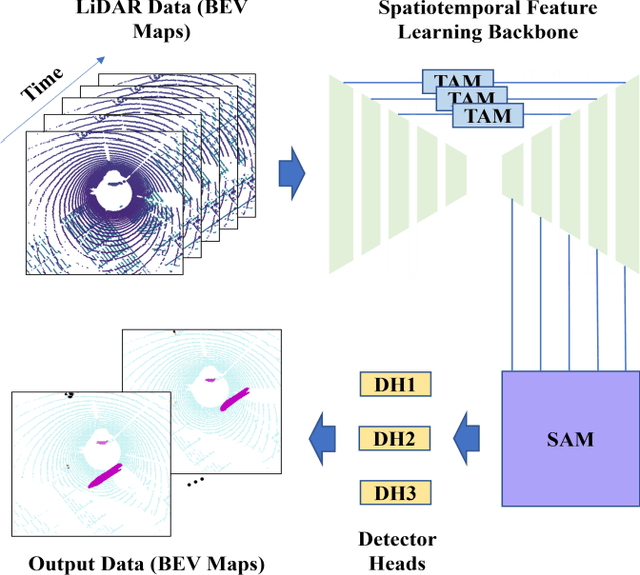
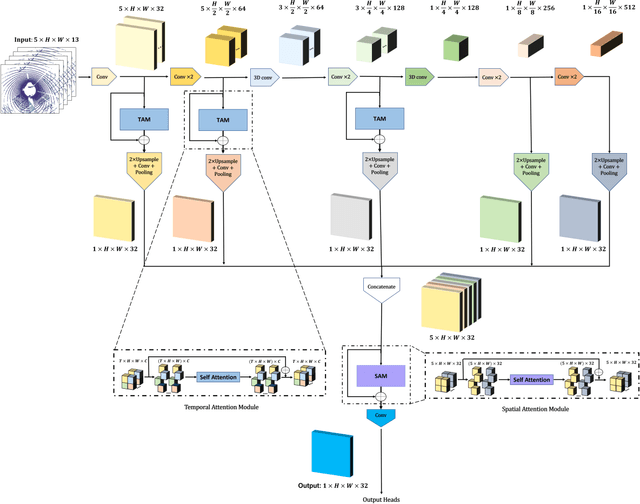
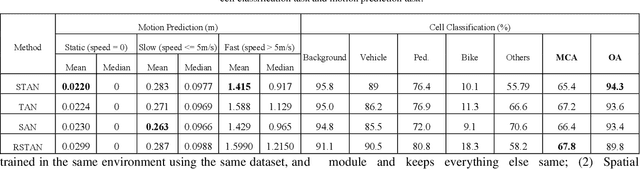
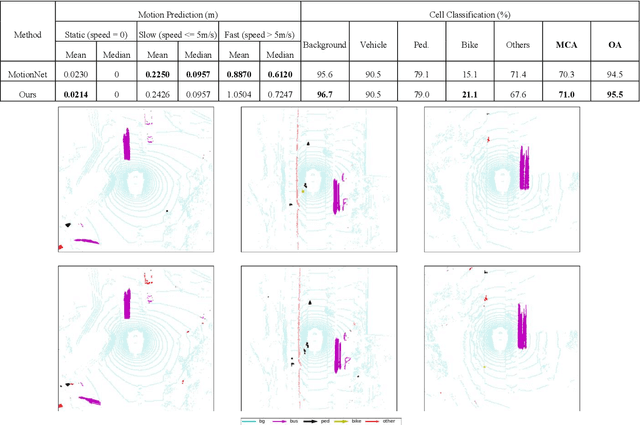
Environment perception including detection, classification, tracking, and motion prediction are key enablers for automated driving systems and intelligent transportation applications. Fueled by the advances in sensing technologies and machine learning techniques, LiDAR-based sensing systems have become a promising solution. The current challenges of this solution are how to effectively combine different perception tasks into a single backbone and how to efficiently learn the spatiotemporal features directly from point cloud sequences. In this research, we propose a novel spatiotemporal attention network based on a transformer self-attention mechanism for joint semantic segmentation and motion prediction within a point cloud at the voxel level. The network is trained to simultaneously outputs the voxel level class and predicted motion by learning directly from a sequence of point cloud datasets. The proposed backbone includes both a temporal attention module (TAM) and a spatial attention module (SAM) to learn and extract the complex spatiotemporal features. This approach has been evaluated with the nuScenes dataset, and promising performance has been achieved.
Infrastructure-Based Object Detection and Tracking for Cooperative Driving Automation: A Survey
Jan 28, 2022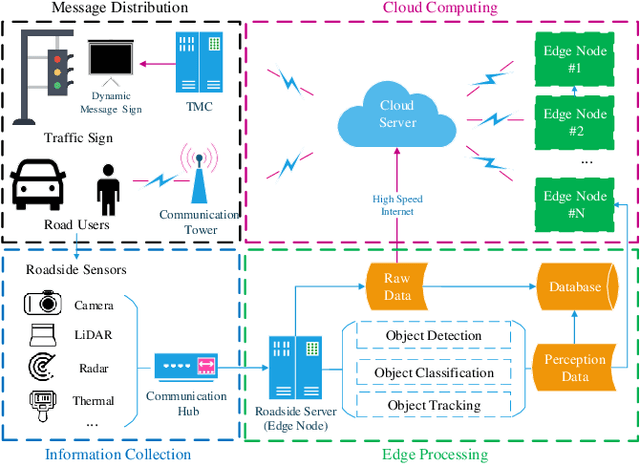
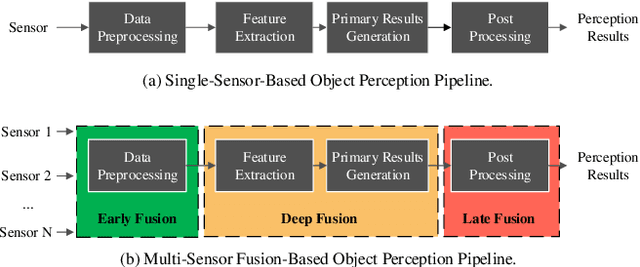

Object detection plays a fundamental role in enabling Cooperative Driving Automation (CDA), which is regarded as the revolutionary solution to addressing safety, mobility, and sustainability issues of contemporary transportation systems. Although current computer vision technologies could provide satisfactory object detection results in occlusion-free scenarios, the perception performance of onboard sensors could be inevitably limited by the range and occlusion. Owing to flexible position and pose for sensor installation, infrastructure-based detection and tracking systems can enhance the perception capability for connected vehicles and thus quickly become one of the most popular research topics. In this paper, we review the research progress for infrastructure-based object detection and tracking systems. Architectures of roadside perception systems based on different types of sensors are reviewed to show a high-level description of the workflows for infrastructure-based perception systems. Roadside sensors and different perception methodologies are reviewed and analyzed with detailed literature to provide a low-level explanation for specific methods followed by Datasets and Simulators to draw an overall landscape of infrastructure-based object detection and tracking methods. Discussions are conducted to point out current opportunities, open problems, and anticipated future trends.
Cyber Mobility Mirror for Enabling Cooperative Driving Automation: A Co-Simulation Platform
Jan 24, 2022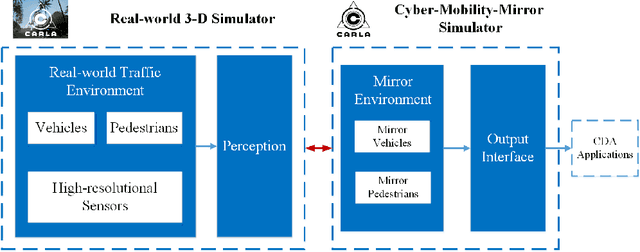
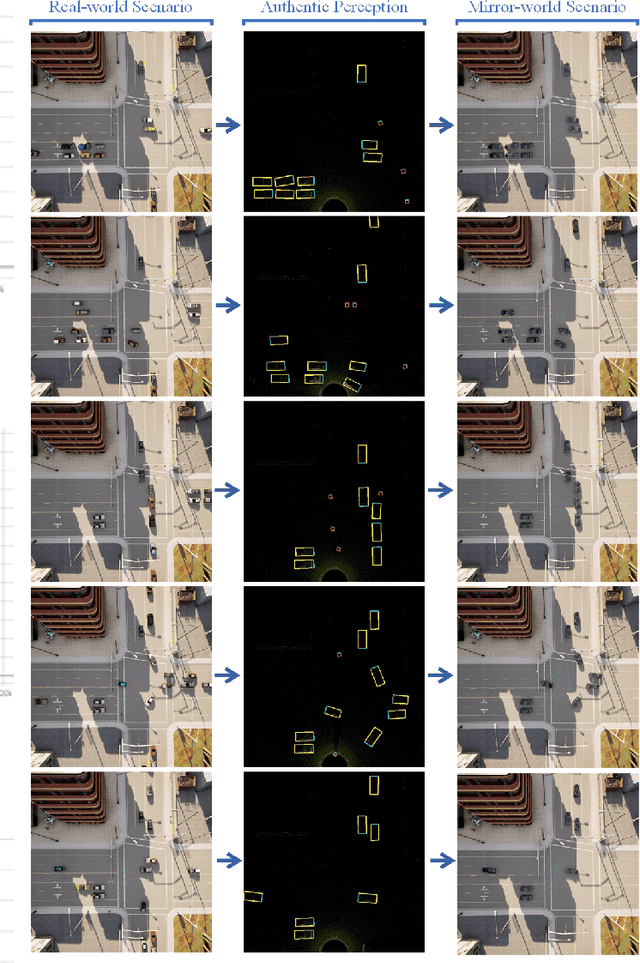
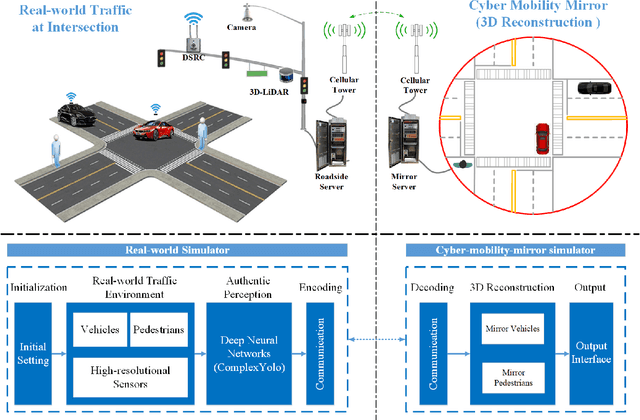
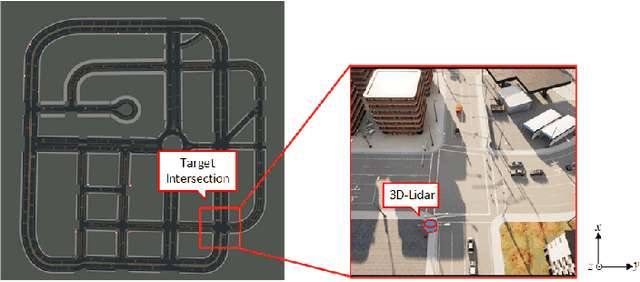
Endowed with automation and connectivity, Connected and Automated Vehicles (CAVs) are meant to be a revolutionary promoter for Cooperative Driving Automation (CDA). Nevertheless, CAVs need high-fidelity perception information on their surroundings, which is available but costly to collect from various on-board sensors, such as radar, camera, and LiDAR, as well as vehicle-to-everything (V2X) communications. Therefore, precisely simulating the sensing process with high-fidelity sensor inputs and timely retrieving the perception information via a cost-effective platform are of increasing significance for enabling CDA-related research, e.g., development of decision-making or control module. Most state-of-the-art traffic simulation studies for CAVs rely on the situation-awareness information by directly calling on intrinsic attributes of the objects, which impedes the reliability and fidelity for testing and validation of CDA algorithms. In this study, a co-simulation platform is developed, which can simulate both the real world with a high-fidelity sensor perception system and the cyber world (or "mirror" world) with a real-time 3D reconstruction system. Specifically, the real-world simulator is mainly in charge of simulating the road-users (such as vehicles, bicyclists, and pedestrians), infrastructure (e.g., traffic signals and roadside sensors) as well as the object detection process. The mirror-world simulator is responsible for reconstructing 3D objects and their trajectories from the perceived information (provided by those roadside sensors in the real-world simulator) to support the development and evaluation of CDA algorithms. To illustrate the efficacy of this co-simulation platform, a roadside LiDAR-based real-time vehicle detection and 3D reconstruction system is prototyped as a study case.
Accelerated Policy Evaluation: Learning Adversarial Environments with Adaptive Importance Sampling
Jun 19, 2021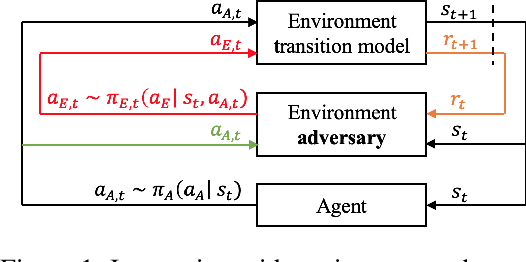
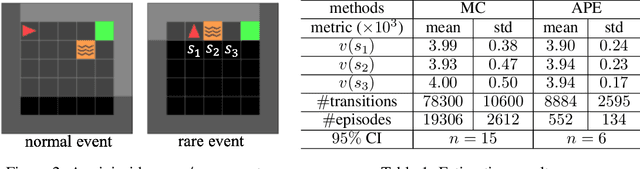
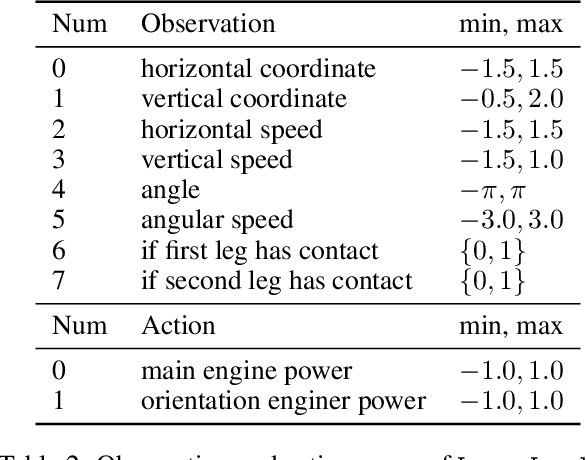
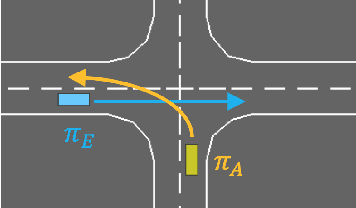
The evaluation of rare but high-stakes events remains one of the main difficulties in obtaining reliable policies from intelligent agents, especially in large or continuous state/action spaces where limited scalability enforces the use of a prohibitively large number of testing iterations. On the other hand, a biased or inaccurate policy evaluation in a safety-critical system could potentially cause unexpected catastrophic failures during deployment. In this paper, we propose the Accelerated Policy Evaluation (APE) method, which simultaneously uncovers rare events and estimates the rare event probability in Markov decision processes. The APE method treats the environment nature as an adversarial agent and learns towards, through adaptive importance sampling, the zero-variance sampling distribution for the policy evaluation. Moreover, APE is scalable to large discrete or continuous spaces by incorporating function approximators. We investigate the convergence properties of proposed algorithms under suitable regularity conditions. Our empirical studies show that APE estimates rare event probability with a smaller variance while only using orders of magnitude fewer samples compared to baseline methods in both multi-agent and single-agent environments.