 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJointly Learning Structured Representations and Stabilized Affinity for Human Motion Segmentation
May 07, 2026Human Motion Segmentation (HMS), which aims to partition a video into non-overlapping segments corresponding to different human motions, has recently attracted increasing research attention. Existing HMS approaches are predominantly based on subspace clustering, which are grounded on the assumption that the distribution of high-dimensional temporal features well aligns with a Union-of-Subspaces (UoS). For videos in the real world, however, the raw frame-level features often violate the UoS assumption and yield unsatisfactory segmentation performance. To address this issue, we propose an efficient and effective approach for HMS, named Temporal Deep Self-expressive subspace Clustering (TDSC), which jointly learns temporally consistent structured representations and stabilized affinity for accurate and robust HMS. Specifically, in TDSC, we alternately learn structured representations of the input frame features and self-expressive coefficients via a properly regularized self-expressive model, in which a coding-rate maximization regularizer is incorporated to avoid representation collapse and conform the learned representations to span a desired UoS distribution, and meanwhile, temporal constraints are incorporated to promote temporally adjacent frames to be partitioned into the same groups. Moreover, we develop a temporal momentum averaging mechanism to stabilize affinity evolution and design a reparameterization strategy to enable efficient optimization. We conduct extensive experiments on five benchmark HMS datasets using both conventional (HoG) and up-to-date deep features (i.e., CLIP, DINOv2) to validate the effectiveness of our approach.
Multi-Modal Representation Learning via Semi-Supervised Rate Reduction for Generalized Category Discovery
Feb 23, 2026Generalized Category Discovery (GCD) aims to identify both known and unknown categories, with only partial labels given for the known categories, posing a challenging open-set recognition problem. State-of-the-art approaches for GCD task are usually built on multi-modality representation learning, which is heavily dependent upon inter-modality alignment. However, few of them cast a proper intra-modality alignment to generate a desired underlying structure of representation distributions. In this paper, we propose a novel and effective multi-modal representation learning framework for GCD via Semi-Supervised Rate Reduction, called SSR$^2$-GCD, to learn cross-modality representations with desired structural properties based on emphasizing to properly align intra-modality relationships. Moreover, to boost knowledge transfer, we integrate prompt candidates by leveraging the inter-modal alignment offered by Vision Language Models. We conduct extensive experiments on generic and fine-grained benchmark datasets demonstrating superior performance of our approach.
MiTA Attention: Efficient Fast-Weight Scaling via a Mixture of Top-k Activations
Feb 03, 2026The attention operator in Transformers can be viewed as a two-layer fast-weight MLP, whose weights are dynamically instantiated from input tokens and whose width equals sequence length N. As the context extends, the expressive capacity of such an N-width MLP increases, but scaling its fast weights becomes prohibitively expensive for extremely long sequences. Recently, this fast-weight scaling perspective has motivated the Mixture-of-Experts (MoE) attention, which partitions the sequence into fast-weight experts and sparsely routes the tokens to them. In this paper, we elevate this perspective to a unifying framework for a wide range of efficient attention methods by interpreting them as scaling fast weights through routing and/or compression. Then we propose a compress-and-route strategy, which compresses the N-width MLP into a narrower one using a small set of landmark queries and constructs deformable experts by gathering top-k activated key-value pairs for each landmark query. We call this strategy a Mixture of Top-k Activations (MiTA), and refer to the resulting efficient mechanism as MiTA attention. Preliminary experiments on vision tasks demonstrate the promise of our MiTA attention and motivate further investigation on its optimization and broader applications in more challenging settings.
SlidesGen-Bench: Evaluating Slides Generation via Computational and Quantitative Metrics
Jan 14, 2026The rapid evolution of Large Language Models (LLMs) has fostered diverse paradigms for automated slide generation, ranging from code-driven layouts to image-centric synthesis. However, evaluating these heterogeneous systems remains challenging, as existing protocols often struggle to provide comparable scores across architectures or rely on uncalibrated judgments. In this paper, we introduce SlidesGen-Bench, a benchmark designed to evaluate slide generation through a lens of three core principles: universality, quantification, and reliability. First, to establish a unified evaluation framework, we ground our analysis in the visual domain, treating terminal outputs as renderings to remain agnostic to the underlying generation method. Second, we propose a computational approach that quantitatively assesses slides across three distinct dimensions - Content, Aesthetics, and Editability - offering reproducible metrics where prior works relied on subjective or reference-dependent proxies. Finally, to ensure high correlation with human preference, we construct the Slides-Align1.5k dataset, a human preference aligned dataset covering slides from nine mainstream generation systems across seven scenarios. Our experiments demonstrate that SlidesGen-Bench achieves a higher degree of alignment with human judgment than existing evaluation pipelines. Our code and data are available at https://github.com/YunqiaoYang/SlidesGen-Bench.
Navi-plus: Managing Ambiguous GUI Navigation Tasks with Follow-up
Mar 31, 2025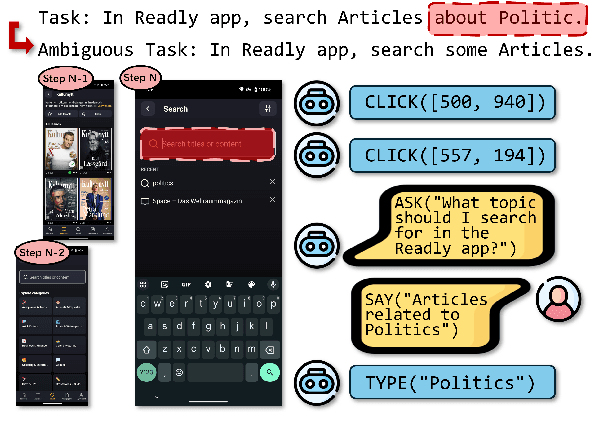
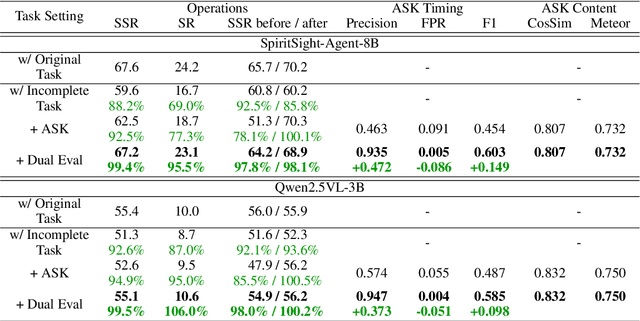
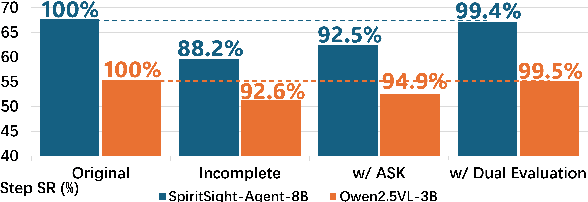
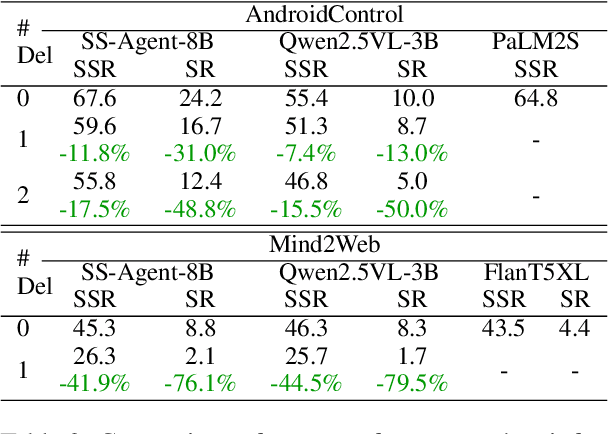
Graphical user interfaces (GUI) automation agents are emerging as powerful tools, enabling humans to accomplish increasingly complex tasks on smart devices. However, users often inadvertently omit key information when conveying tasks, which hinders agent performance in the current agent paradigm that does not support immediate user intervention. To address this issue, we introduce a $\textbf{Self-Correction GUI Navigation}$ task that incorporates interactive information completion capabilities within GUI agents. We developed the $\textbf{Navi-plus}$ dataset with GUI follow-up question-answer pairs, alongside a $\textbf{Dual-Stream Trajectory Evaluation}$ method to benchmark this new capability. Our results show that agents equipped with the ability to ask GUI follow-up questions can fully recover their performance when faced with ambiguous user tasks.
Exploring a Principled Framework for Deep Subspace Clustering
Mar 21, 2025Subspace clustering is a classical unsupervised learning task, built on a basic assumption that high-dimensional data can be approximated by a union of subspaces (UoS). Nevertheless, the real-world data are often deviating from the UoS assumption. To address this challenge, state-of-the-art deep subspace clustering algorithms attempt to jointly learn UoS representations and self-expressive coefficients. However, the general framework of the existing algorithms suffers from a catastrophic feature collapse and lacks a theoretical guarantee to learn desired UoS representation. In this paper, we present a Principled fRamewOrk for Deep Subspace Clustering (PRO-DSC), which is designed to learn structured representations and self-expressive coefficients in a unified manner. Specifically, in PRO-DSC, we incorporate an effective regularization on the learned representations into the self-expressive model, prove that the regularized self-expressive model is able to prevent feature space collapse, and demonstrate that the learned optimal representations under certain condition lie on a union of orthogonal subspaces. Moreover, we provide a scalable and efficient approach to implement our PRO-DSC and conduct extensive experiments to verify our theoretical findings and demonstrate the superior performance of our proposed deep subspace clustering approach. The code is available at https://github.com/mengxianghan123/PRO-DSC.
SpiritSight Agent: Advanced GUI Agent with One Look
Mar 05, 2025Graphical User Interface (GUI) agents show amazing abilities in assisting human-computer interaction, automating human user's navigation on digital devices. An ideal GUI agent is expected to achieve high accuracy, low latency, and compatibility for different GUI platforms. Recent vision-based approaches have shown promise by leveraging advanced Vision Language Models (VLMs). While they generally meet the requirements of compatibility and low latency, these vision-based GUI agents tend to have low accuracy due to their limitations in element grounding. To address this issue, we propose $\textbf{SpiritSight}$, a vision-based, end-to-end GUI agent that excels in GUI navigation tasks across various GUI platforms. First, we create a multi-level, large-scale, high-quality GUI dataset called $\textbf{GUI-Lasagne}$ using scalable methods, empowering SpiritSight with robust GUI understanding and grounding capabilities. Second, we introduce the $\textbf{Universal Block Parsing (UBP)}$ method to resolve the ambiguity problem in dynamic high-resolution of visual inputs, further enhancing SpiritSight's ability to ground GUI objects. Through these efforts, SpiritSight agent outperforms other advanced methods on diverse GUI benchmarks, demonstrating its superior capability and compatibility in GUI navigation tasks. Models are available at $\href{https://huggingface.co/SenseLLM/SpiritSight-Agent-8B}{this\ URL}$.
AgentStudio: A Toolkit for Building General Virtual Agents
Mar 26, 2024Creating autonomous virtual agents capable of using arbitrary software on any digital device remains a major challenge for artificial intelligence. Two key obstacles hinder progress: insufficient infrastructure for building virtual agents in real-world environments, and the need for in-the-wild evaluation of fundamental agent abilities. To address this, we introduce AgentStudio, an online, realistic, and multimodal toolkit that covers the entire lifecycle of agent development. This includes environment setups, data collection, agent evaluation, and visualization. The observation and action spaces are highly generic, supporting both function calling and human-computer interfaces. This versatility is further enhanced by AgentStudio's graphical user interfaces, which allow efficient development of datasets and benchmarks in real-world settings. To illustrate, we introduce a visual grounding dataset and a real-world benchmark suite, both created with our graphical interfaces. Furthermore, we present several actionable insights derived from AgentStudio, e.g., general visual grounding, open-ended tool creation, learning from videos, etc. We have open-sourced the environments, datasets, benchmarks, and interfaces to promote research towards developing general virtual agents for the future.
TeacherLM: Teaching to Fish Rather Than Giving the Fish, Language Modeling Likewise
Oct 31, 2023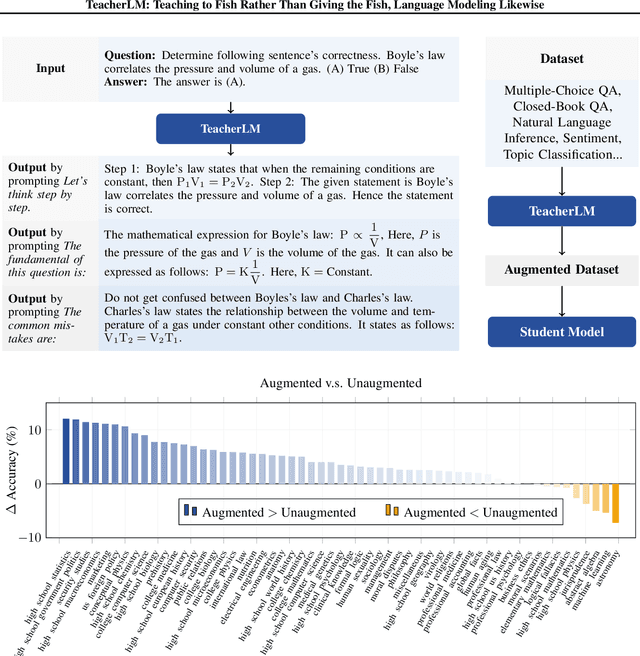

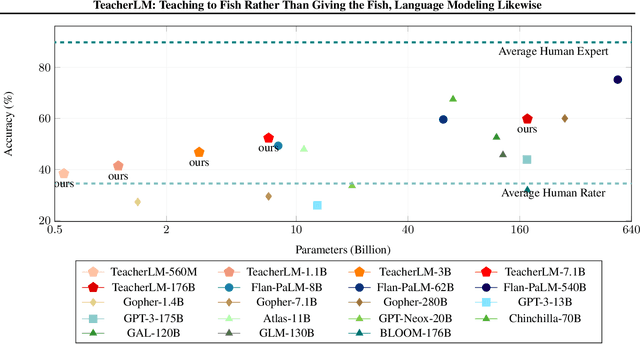

Large Language Models (LLMs) exhibit impressive reasoning and data augmentation capabilities in various NLP tasks. However, what about small models? In this work, we propose TeacherLM-7.1B, capable of annotating relevant fundamentals, chain of thought, and common mistakes for most NLP samples, which makes annotation more than just an answer, thus allowing other models to learn "why" instead of just "what". The TeacherLM-7.1B model achieved a zero-shot score of 52.3 on MMLU, surpassing most models with over 100B parameters. Even more remarkable is its data augmentation ability. Based on TeacherLM-7.1B, we augmented 58 NLP datasets and taught various student models with different parameters from OPT and BLOOM series in a multi-task setting. The experimental results indicate that the data augmentation provided by TeacherLM has brought significant benefits. We will release the TeacherLM series of models and augmented datasets as open-source.
Certifiable Deep Importance Sampling for Rare-Event Simulation of Black-Box Systems
Nov 03, 2021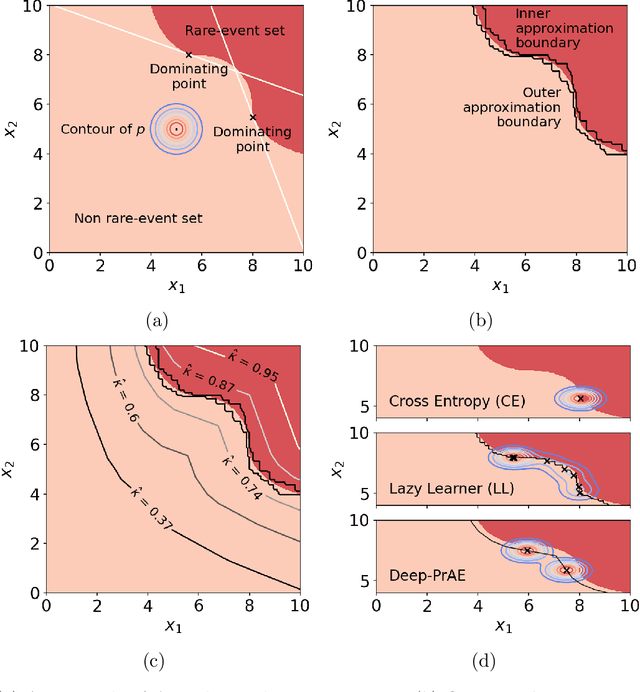

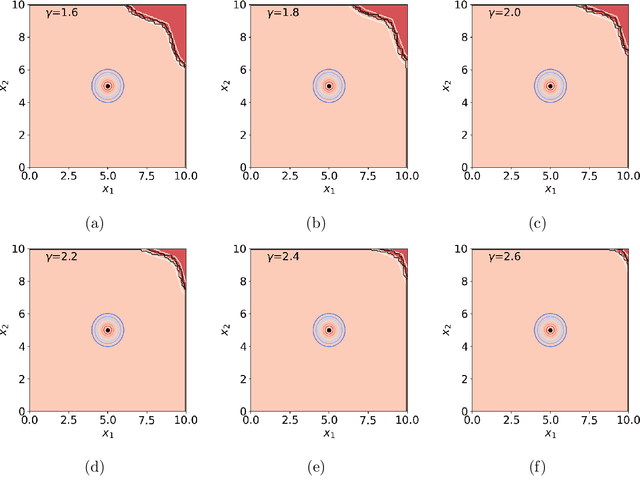
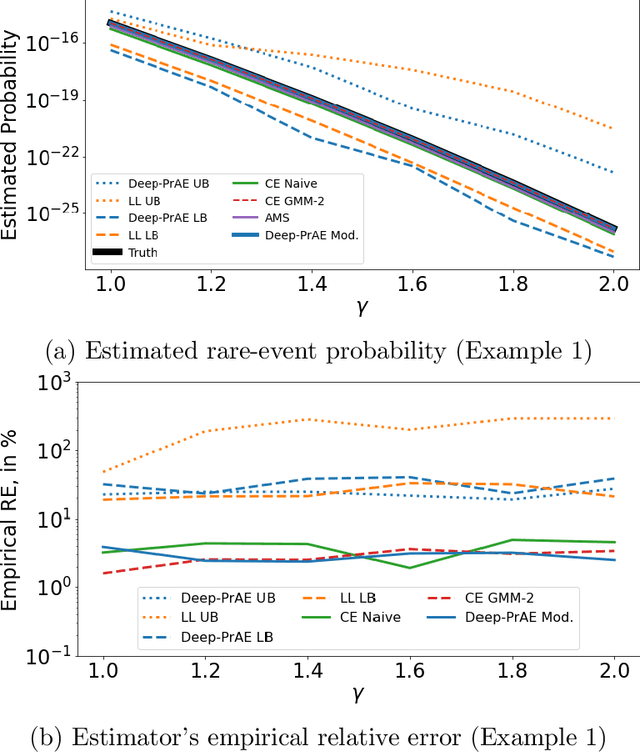
Rare-event simulation techniques, such as importance sampling (IS), constitute powerful tools to speed up challenging estimation of rare catastrophic events. These techniques often leverage the knowledge and analysis on underlying system structures to endow desirable efficiency guarantees. However, black-box problems, especially those arising from recent safety-critical applications of AI-driven physical systems, can fundamentally undermine their efficiency guarantees and lead to dangerous under-estimation without diagnostically detected. We propose a framework called Deep Probabilistic Accelerated Evaluation (Deep-PrAE) to design statistically guaranteed IS, by converting black-box samplers that are versatile but could lack guarantees, into one with what we call a relaxed efficiency certificate that allows accurate estimation of bounds on the rare-event probability. We present the theory of Deep-PrAE that combines the dominating point concept with rare-event set learning via deep neural network classifiers, and demonstrate its effectiveness in numerical examples including the safety-testing of intelligent driving algorithms.