 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Autonomous Agents: A Closer Look at Why They Fail When Completing Tasks
Aug 18, 2025Autonomous agent systems powered by Large Language Models (LLMs) have demonstrated promising capabilities in automating complex tasks. However, current evaluations largely rely on success rates without systematically analyzing the interactions, communication mechanisms, and failure causes within these systems. To bridge this gap, we present a benchmark of 34 representative programmable tasks designed to rigorously assess autonomous agents. Using this benchmark, we evaluate three popular open-source agent frameworks combined with two LLM backbones, observing a task completion rate of approximately 50%. Through in-depth failure analysis, we develop a three-tier taxonomy of failure causes aligned with task phases, highlighting planning errors, task execution issues, and incorrect response generation. Based on these insights, we propose actionable improvements to enhance agent planning and self-diagnosis capabilities. Our failure taxonomy, together with mitigation advice, provides an empirical foundation for developing more robust and effective autonomous agent systems in the future.
Next Edit Prediction: Learning to Predict Code Edits from Context and Interaction History
Aug 13, 2025The rapid advancement of large language models (LLMs) has led to the widespread adoption of AI-powered coding assistants integrated into a development environment. On one hand, low-latency code completion offers completion suggestions but is fundamentally constrained to the cursor's current position. On the other hand, chat-based editing can perform complex modifications, yet forces developers to stop their work, describe the intent in natural language, which causes a context-switch away from the code. This creates a suboptimal user experience, as neither paradigm proactively predicts the developer's next edit in a sequence of related edits. To bridge this gap and provide the seamless code edit suggestion, we introduce the task of Next Edit Prediction, a novel task designed to infer developer intent from recent interaction history to predict both the location and content of the subsequent edit. Specifically, we curate a high-quality supervised fine-tuning dataset and an evaluation benchmark for the Next Edit Prediction task. Then, we conduct supervised fine-tuning on a series of models and performed a comprehensive evaluation of both the fine-tuned models and other baseline models, yielding several novel findings. This work lays the foundation for a new interaction paradigm that proactively collaborate with developers by anticipating their following action, rather than merely reacting to explicit instructions.
TeacherLM: Teaching to Fish Rather Than Giving the Fish, Language Modeling Likewise
Oct 31, 2023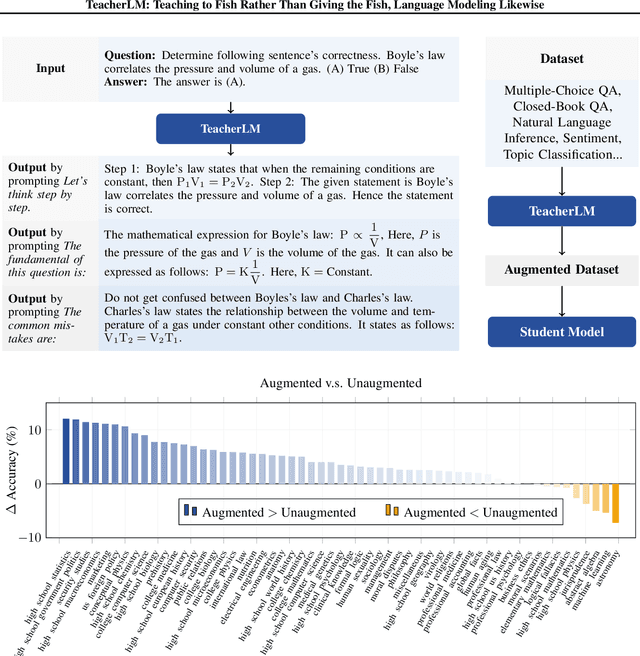

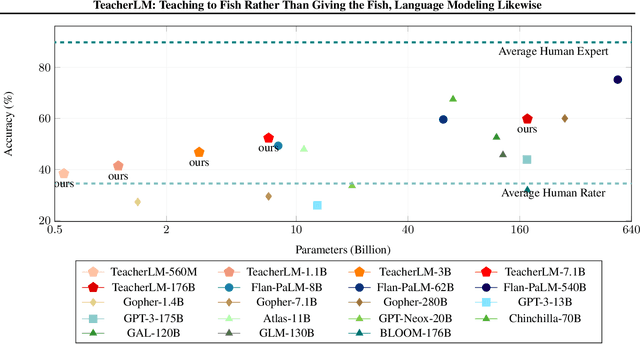

Large Language Models (LLMs) exhibit impressive reasoning and data augmentation capabilities in various NLP tasks. However, what about small models? In this work, we propose TeacherLM-7.1B, capable of annotating relevant fundamentals, chain of thought, and common mistakes for most NLP samples, which makes annotation more than just an answer, thus allowing other models to learn "why" instead of just "what". The TeacherLM-7.1B model achieved a zero-shot score of 52.3 on MMLU, surpassing most models with over 100B parameters. Even more remarkable is its data augmentation ability. Based on TeacherLM-7.1B, we augmented 58 NLP datasets and taught various student models with different parameters from OPT and BLOOM series in a multi-task setting. The experimental results indicate that the data augmentation provided by TeacherLM has brought significant benefits. We will release the TeacherLM series of models and augmented datasets as open-source.