 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInference-Time Scaling of Verification: Self-Evolving Deep Research Agents via Test-Time Rubric-Guided Verification
Jan 22, 2026Recent advances in Deep Research Agents (DRAs) are transforming automated knowledge discovery and problem-solving. While the majority of existing efforts focus on enhancing policy capabilities via post-training, we propose an alternative paradigm: self-evolving the agent's ability by iteratively verifying the policy model's outputs, guided by meticulously crafted rubrics. This approach gives rise to the inference-time scaling of verification, wherein an agent self-improves by evaluating its generated answers to produce iterative feedback and refinements. We derive the rubrics based on an automatically constructed DRA Failure Taxonomy, which systematically classifies agent failures into five major categories and thirteen sub-categories. We present DeepVerifier, a rubrics-based outcome reward verifier that leverages the asymmetry of verification and outperforms vanilla agent-as-judge and LLM judge baselines by 12%-48% in meta-evaluation F1 score. To enable practical self-evolution, DeepVerifier integrates as a plug-and-play module during test-time inference. The verifier produces detailed rubric-based feedback, which is fed back to the agent for iterative bootstrapping, refining responses without additional training. This test-time scaling delivers 8%-11% accuracy gains on challenging subsets of GAIA and XBench-DeepResearch when powered by capable closed-source LLMs. Finally, to support open-source advancement, we release DeepVerifier-4K, a curated supervised fine-tuning dataset of 4,646 high-quality agent steps focused on DRA verification. These examples emphasize reflection and self-critique, enabling open models to develop robust verification capabilities.
Exploring Autonomous Agents: A Closer Look at Why They Fail When Completing Tasks
Aug 18, 2025Autonomous agent systems powered by Large Language Models (LLMs) have demonstrated promising capabilities in automating complex tasks. However, current evaluations largely rely on success rates without systematically analyzing the interactions, communication mechanisms, and failure causes within these systems. To bridge this gap, we present a benchmark of 34 representative programmable tasks designed to rigorously assess autonomous agents. Using this benchmark, we evaluate three popular open-source agent frameworks combined with two LLM backbones, observing a task completion rate of approximately 50%. Through in-depth failure analysis, we develop a three-tier taxonomy of failure causes aligned with task phases, highlighting planning errors, task execution issues, and incorrect response generation. Based on these insights, we propose actionable improvements to enhance agent planning and self-diagnosis capabilities. Our failure taxonomy, together with mitigation advice, provides an empirical foundation for developing more robust and effective autonomous agent systems in the future.
Next Edit Prediction: Learning to Predict Code Edits from Context and Interaction History
Aug 13, 2025The rapid advancement of large language models (LLMs) has led to the widespread adoption of AI-powered coding assistants integrated into a development environment. On one hand, low-latency code completion offers completion suggestions but is fundamentally constrained to the cursor's current position. On the other hand, chat-based editing can perform complex modifications, yet forces developers to stop their work, describe the intent in natural language, which causes a context-switch away from the code. This creates a suboptimal user experience, as neither paradigm proactively predicts the developer's next edit in a sequence of related edits. To bridge this gap and provide the seamless code edit suggestion, we introduce the task of Next Edit Prediction, a novel task designed to infer developer intent from recent interaction history to predict both the location and content of the subsequent edit. Specifically, we curate a high-quality supervised fine-tuning dataset and an evaluation benchmark for the Next Edit Prediction task. Then, we conduct supervised fine-tuning on a series of models and performed a comprehensive evaluation of both the fine-tuned models and other baseline models, yielding several novel findings. This work lays the foundation for a new interaction paradigm that proactively collaborate with developers by anticipating their following action, rather than merely reacting to explicit instructions.
DesignBench: A Comprehensive Benchmark for MLLM-based Front-end Code Generation
Jun 06, 2025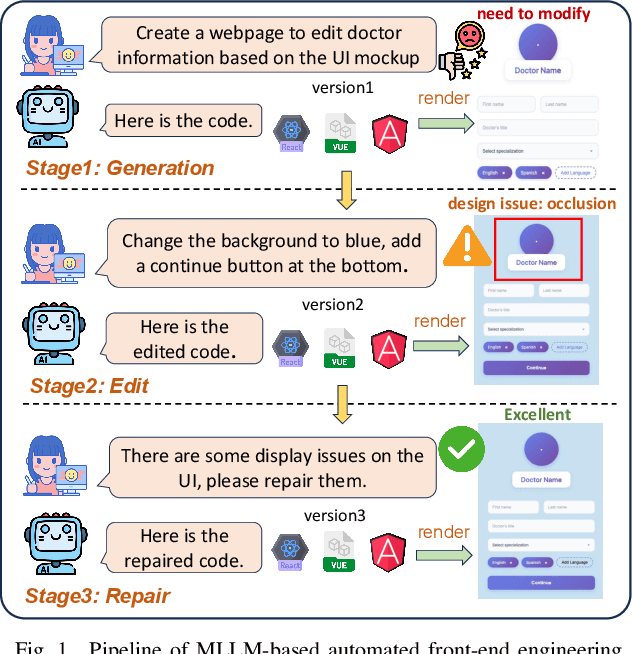
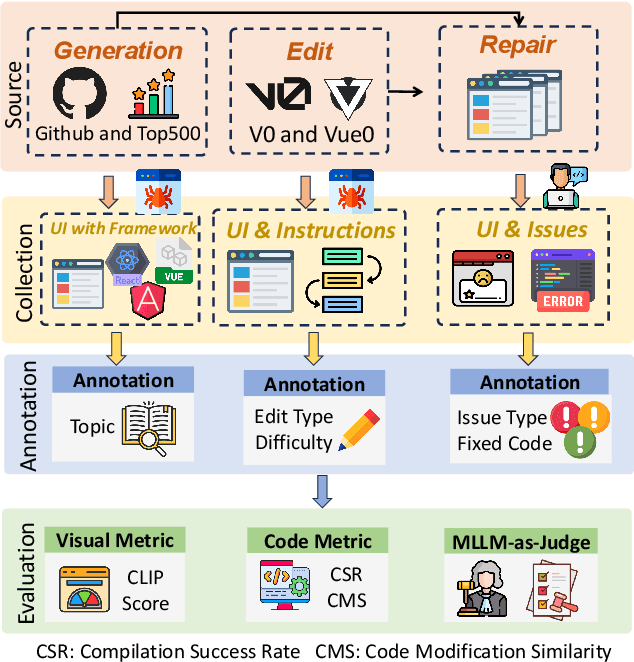

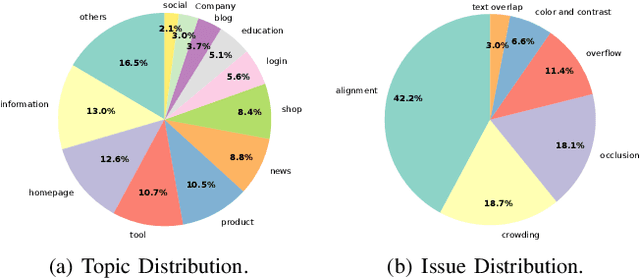
Multimodal Large Language Models (MLLMs) have demonstrated remarkable capabilities in automated front-end engineering, e.g., generating UI code from visual designs. However, existing front-end UI code generation benchmarks have the following limitations: (1) While framework-based development becomes predominant in modern front-end programming, current benchmarks fail to incorporate mainstream development frameworks. (2) Existing evaluations focus solely on the UI code generation task, whereas practical UI development involves several iterations, including refining editing, and repairing issues. (3) Current benchmarks employ unidimensional evaluation, lacking investigation into influencing factors like task difficulty, input context variations, and in-depth code-level analysis. To bridge these gaps, we introduce DesignBench, a multi-framework, multi-task evaluation benchmark for assessing MLLMs' capabilities in automated front-end engineering. DesignBench encompasses three widely-used UI frameworks (React, Vue, and Angular) alongside vanilla HTML/CSS, and evaluates on three essential front-end tasks (generation, edit, and repair) in real-world development workflows. DesignBench contains 900 webpage samples spanning over 11 topics, 9 edit types, and 6 issue categories, enabling detailed analysis of MLLM performance across multiple dimensions. Our systematic evaluation reveals critical insights into MLLMs' framework-specific limitations, task-related bottlenecks, and performance variations under different conditions, providing guidance for future research in automated front-end development. Our code and data are available at https://github.com/WebPAI/DesignBench.
Financial Named Entity Recognition: How Far Can LLM Go?
Jan 04, 2025



The surge of large language models (LLMs) has revolutionized the extraction and analysis of crucial information from a growing volume of financial statements, announcements, and business news. Recognition for named entities to construct structured data poses a significant challenge in analyzing financial documents and is a foundational task for intelligent financial analytics. However, how effective are these generic LLMs and their performance under various prompts are yet need a better understanding. To fill in the blank, we present a systematic evaluation of state-of-the-art LLMs and prompting methods in the financial Named Entity Recognition (NER) problem. Specifically, our experimental results highlight their strengths and limitations, identify five representative failure types, and provide insights into their potential and challenges for domain-specific tasks.
MRWeb: An Exploration of Generating Multi-Page Resource-Aware Web Code from UI Designs
Dec 19, 2024Multi-page websites dominate modern web development. However, existing design-to-code methods rely on simplified assumptions, limiting to single-page, self-contained webpages without external resource connection. To address this gap, we introduce the Multi-Page Resource-Aware Webpage (MRWeb) generation task, which transforms UI designs into multi-page, functional web UIs with internal/external navigation, image loading, and backend routing. We propose a novel resource list data structure to track resources, links, and design components. Our study applies existing methods to the MRWeb problem using a newly curated dataset of 500 websites (300 synthetic, 200 real-world). Specifically, we identify the best metric to evaluate the similarity of the web UI, assess the impact of the resource list on MRWeb generation, analyze MLLM limitations, and evaluate the effectiveness of the MRWeb tool in real-world workflows. The results show that resource lists boost navigation functionality from 0% to 66%-80% while facilitating visual similarity. Our proposed metrics and evaluation framework provide new insights into MLLM performance on MRWeb tasks. We release the MRWeb tool, dataset, and evaluation framework to promote further research.
Interaction2Code: How Far Are We From Automatic Interactive Webpage Generation?
Nov 05, 2024



Converting webpage design into functional UI code is a critical step for building websites, which can be labor-intensive and time-consuming. To automate this design-to-code transformation process, various automated methods using learning-based networks and multi-modal large language models (MLLMs) have been proposed. However, these studies were merely evaluated on a narrow range of static web pages and ignored dynamic interaction elements, making them less practical for real-world website deployment. To fill in the blank, we present the first systematic investigation of MLLMs in generating interactive webpages. Specifically, we first formulate the Interaction-to-Code task and build the Interaction2Code benchmark that contains 97 unique web pages and 213 distinct interactions, spanning 15 webpage types and 30 interaction categories. We then conduct comprehensive experiments on three state-of-the-art (SOTA) MLLMs using both automatic metrics and human evaluations, thereby summarizing six findings accordingly. Our experimental results highlight the limitations of MLLMs in generating fine-grained interactive features and managing interactions with complex transformations and subtle visual modifications. We further analyze failure cases and their underlying causes, identifying 10 common failure types and assessing their severity. Additionally, our findings reveal three critical influencing factors, i.e., prompts, visual saliency, and textual descriptions, that can enhance the interaction generation performance of MLLMs. Based on these findings, we elicit implications for researchers and developers, providing a foundation for future advancements in this field. Datasets and source code are available at https://github.com/WebPAI/Interaction2Code.
Automatically Generating UI Code from Screenshot: A Divide-and-Conquer-Based Approach
Jun 24, 2024



Websites are critical in today's digital world, with over 1.11 billion currently active and approximately 252,000 new sites launched daily. Converting website layout design into functional UI code is a time-consuming yet indispensable step of website development. Manual methods of converting visual designs into functional code present significant challenges, especially for non-experts. To explore automatic design-to-code solutions, we first conduct a motivating study on GPT-4o and identify three types of issues in generating UI code: element omission, element distortion, and element misarrangement. We further reveal that a focus on smaller visual segments can help multimodal large language models (MLLMs) mitigate these failures in the generation process. In this paper, we propose DCGen, a divide-and-conquer-based approach to automate the translation of webpage design to UI code. DCGen starts by dividing screenshots into manageable segments, generating descriptions for each segment, and then reassembling them into complete UI code for the entire screenshot. We conduct extensive testing with a dataset comprised of real-world websites and various MLLMs and demonstrate that DCGen achieves up to a 14% improvement in visual similarity over competing methods. To the best of our knowledge, DCGen is the first segment-aware prompt-based approach for generating UI code directly from screenshots.
Face It Yourselves: An LLM-Based Two-Stage Strategy to Localize Configuration Errors via Logs
Apr 02, 2024Configurable software systems are prone to configuration errors, resulting in significant losses to companies. However, diagnosing these errors is challenging due to the vast and complex configuration space. These errors pose significant challenges for both experienced maintainers and new end-users, particularly those without access to the source code of the software systems. Given that logs are easily accessible to most end-users, we conduct a preliminary study to outline the challenges and opportunities of utilizing logs in localizing configuration errors. Based on the insights gained from the preliminary study, we propose an LLM-based two-stage strategy for end-users to localize the root-cause configuration properties based on logs. We further implement a tool, LogConfigLocalizer, aligned with the design of the aforementioned strategy, hoping to assist end-users in coping with configuration errors through log analysis. To the best of our knowledge, this is the first work to localize the root-cause configuration properties for end-users based on Large Language Models~(LLMs) and logs. We evaluate the proposed strategy on Hadoop by LogConfigLocalizer and prove its efficiency with an average accuracy as high as 99.91%. Additionally, we also demonstrate the effectiveness and necessity of different phases of the methodology by comparing it with two other variants and a baseline tool. Moreover, we validate the proposed methodology through a practical case study to demonstrate its effectiveness and feasibility.
Enhancing LLM-Based Coding Tools through Native Integration of IDE-Derived Static Context
Feb 06, 2024


Large Language Models (LLMs) have achieved remarkable success in code completion, as evidenced by their essential roles in developing code assistant services such as Copilot. Being trained on in-file contexts, current LLMs are quite effective in completing code for single source files. However, it is challenging for them to conduct repository-level code completion for large software projects that require cross-file information. Existing research on LLM-based repository-level code completion identifies and integrates cross-file contexts, but it suffers from low accuracy and limited context length of LLMs. In this paper, we argue that Integrated Development Environments (IDEs) can provide direct, accurate and real-time cross-file information for repository-level code completion. We propose IDECoder, a practical framework that leverages IDE native static contexts for cross-context construction and diagnosis results for self-refinement. IDECoder utilizes the rich cross-context information available in IDEs to enhance the capabilities of LLMs of repository-level code completion. We conducted preliminary experiments to validate the performance of IDECoder and observed that this synergy represents a promising trend for future exploration.