 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGrounded Satirical Generation with RAG
May 11, 2026Humor generation remains challenging task for Large Language Models (LLMs), due to their subjective nature. We focus on satire, a form of humor strongly shaped by context. In this work, we present a novel pipeline for grounded satire generation that uses Retrieval-Augmented Generation (RAG) over current news to produce satirical dictionary definitions in the Finnish context. We also introduce a new task-specific evaluation framework and annotate 100 generated definitions with six human annotators, enabling analysis across multiple experimental conditions, including cultural background, source-word type, and the presence or absence of RAG. Our results show that the generated definitions are perceived as more political than humorous. Both topic-based word selection and RAG improve the political relevance of the outputs, but neither yields clear gains in humor generation. In addition, our LLM-as-a-judge evaluation of five state-of-the-art models indicates that LLMs correlate well with human judgments on political relevance, but perform poorly on humor. We release our code and annotated dataset to support further research on grounded satire generation and evaluation.
ComBench: A Repo-level Real-world Benchmark for Compilation Error Repair
Mar 28, 2026Compilation errors pose pervasive and critical challenges in software development, significantly hindering productivity. Therefore, Automated Compilation Error Repair (ACER) techniques are proposed to mitigate these issues. Despite recent advancements in ACER, its real-world performance remains poorly evaluated. This can be largely attributed to the limitations of existing benchmarks, \ie decontextualized single-file data, lack of authentic source diversity, and biased local task modeling that ignores crucial repository-level complexities. To bridge this critical gap, we propose ComBench, the first repository-level, reproducible real-world benchmark for C/C++ compilation error repair. ComBench is constructed through a novel, automated framework that systematically mines real-world failures from the GitHub CI histories of large-scale open-source projects. Our framework contributes techniques for the high-precision identification of ground-truth repair patches from complex version histories and a high-fidelity mechanism for reproducing the original, ephemeral build environments. To ensure data quality, all samples in ComBench are execution-verified -- guaranteeing reproducible failures and build success with ground-truth patches. Using ComBench, we conduct a comprehensive evaluation of 12 modern LLMs under both direct and agent-based repair settings. Our experiments reveal a significant gap between a model's ability to achieve syntactic correctness (a 73% success rate for GPT-5) and its ability to ensure semantic correctness (only 41% of its patches are valid). We also find that different models exhibit distinct specializations for different error types. ComBench provides a robust and realistic platform to guide the future development of ACER techniques capable of addressing the complexities of modern software development.
From Laboratory to Real-World Applications: Benchmarking Agentic Code Reasoning at the Repository Level
Jan 07, 2026As large language models (LLMs) evolve into autonomous agents, evaluating repository-level reasoning, the ability to maintain logical consistency across massive, real-world, interdependent file systems, has become critical. Current benchmarks typically fluctuate between isolated code snippets and black-box evaluations. We present RepoReason, a white-box diagnostic benchmark centered on abductive assertion verification. To eliminate memorization while preserving authentic logical depth, we implement an execution-driven mutation framework that utilizes the environment as a semantic oracle to regenerate ground-truth states. Furthermore, we establish a fine-grained diagnostic system using dynamic program slicing, quantifying reasoning via three orthogonal metrics: $ESV$ (reading load), $MCL$ (simulation depth), and $DFI$ (integration width). Comprehensive evaluations of frontier models (e.g., Claude-4.5-Sonnet, DeepSeek-v3.1-Terminus) reveal a prevalent aggregation deficit, where integration width serves as the primary cognitive bottleneck. Our findings provide granular white-box insights for optimizing the next generation of agentic software engineering.
Face It Yourselves: An LLM-Based Two-Stage Strategy to Localize Configuration Errors via Logs
Apr 02, 2024Configurable software systems are prone to configuration errors, resulting in significant losses to companies. However, diagnosing these errors is challenging due to the vast and complex configuration space. These errors pose significant challenges for both experienced maintainers and new end-users, particularly those without access to the source code of the software systems. Given that logs are easily accessible to most end-users, we conduct a preliminary study to outline the challenges and opportunities of utilizing logs in localizing configuration errors. Based on the insights gained from the preliminary study, we propose an LLM-based two-stage strategy for end-users to localize the root-cause configuration properties based on logs. We further implement a tool, LogConfigLocalizer, aligned with the design of the aforementioned strategy, hoping to assist end-users in coping with configuration errors through log analysis. To the best of our knowledge, this is the first work to localize the root-cause configuration properties for end-users based on Large Language Models~(LLMs) and logs. We evaluate the proposed strategy on Hadoop by LogConfigLocalizer and prove its efficiency with an average accuracy as high as 99.91%. Additionally, we also demonstrate the effectiveness and necessity of different phases of the methodology by comparing it with two other variants and a baseline tool. Moreover, we validate the proposed methodology through a practical case study to demonstrate its effectiveness and feasibility.
Can Language Models Pretend Solvers? Logic Code Simulation with LLMs
Mar 28, 2024



Transformer-based large language models (LLMs) have demonstrated significant potential in addressing logic problems. capitalizing on the great capabilities of LLMs for code-related activities, several frameworks leveraging logical solvers for logic reasoning have been proposed recently. While existing research predominantly focuses on viewing LLMs as natural language logic solvers or translators, their roles as logic code interpreters and executors have received limited attention. This study delves into a novel aspect, namely logic code simulation, which forces LLMs to emulate logical solvers in predicting the results of logical programs. To further investigate this novel task, we formulate our three research questions: Can LLMs efficiently simulate the outputs of logic codes? What strength arises along with logic code simulation? And what pitfalls? To address these inquiries, we curate three novel datasets tailored for the logic code simulation task and undertake thorough experiments to establish the baseline performance of LLMs in code simulation. Subsequently, we introduce a pioneering LLM-based code simulation technique, Dual Chains of Logic (DCoL). This technique advocates a dual-path thinking approach for LLMs, which has demonstrated state-of-the-art performance compared to other LLM prompt strategies, achieving a notable improvement in accuracy by 7.06% with GPT-4-Turbo.
MTAD: Tools and Benchmarks for Multivariate Time Series Anomaly Detection
Jan 10, 2024Key Performance Indicators (KPIs) are essential time-series metrics for ensuring the reliability and stability of many software systems. They faithfully record runtime states to facilitate the understanding of anomalous system behaviors and provide informative clues for engineers to pinpoint the root causes. The unprecedented scale and complexity of modern software systems, however, make the volume of KPIs explode. Consequently, many traditional methods of KPI anomaly detection become impractical, which serves as a catalyst for the fast development of machine learning-based solutions in both academia and industry. However, there is currently a lack of rigorous comparison among these KPI anomaly detection methods, and re-implementation demands a non-trivial effort. Moreover, we observe that different works adopt independent evaluation processes with different metrics. Some of them may not fully reveal the capability of a model and some are creating an illusion of progress. To better understand the characteristics of different KPI anomaly detectors and address the evaluation issue, in this paper, we provide a comprehensive review and evaluation of twelve state-of-the-art methods, and propose a novel metric called salience. Particularly, the selected methods include five traditional machine learning-based methods and seven deep learning-based methods. These methods are evaluated with five multivariate KPI datasets that are publicly available. A unified toolkit with easy-to-use interfaces is also released. We report the benchmark results in terms of accuracy, salience, efficiency, and delay, which are of practical importance for industrial deployment. We believe our work can contribute as a basis for future academic research and industrial application.
Practical Anomaly Detection over Multivariate Monitoring Metrics for Online Services
Aug 19, 2023



As modern software systems continue to grow in terms of complexity and volume, anomaly detection on multivariate monitoring metrics, which profile systems' health status, becomes more and more critical and challenging. In particular, the dependency between different metrics and their historical patterns plays a critical role in pursuing prompt and accurate anomaly detection. Existing approaches fall short of industrial needs for being unable to capture such information efficiently. To fill this significant gap, in this paper, we propose CMAnomaly, an anomaly detection framework on multivariate monitoring metrics based on collaborative machine. The proposed collaborative machine is a mechanism to capture the pairwise interactions along with feature and temporal dimensions with linear time complexity. Cost-effective models can then be employed to leverage both the dependency between monitoring metrics and their historical patterns for anomaly detection. The proposed framework is extensively evaluated with both public data and industrial data collected from a large-scale online service system of Huawei Cloud. The experimental results demonstrate that compared with state-of-the-art baseline models, CMAnomaly achieves an average F1 score of 0.9494, outperforming baselines by 6.77% to 10.68%, and runs 10X to 20X faster. Furthermore, we also share our experience of deploying CMAnomaly in Huawei Cloud.
Performance Issue Identification in Cloud Systems with Relational-Temporal Anomaly Detection
Aug 01, 2023Performance issues permeate large-scale cloud service systems, which can lead to huge revenue losses. To ensure reliable performance, it's essential to accurately identify and localize these issues using service monitoring metrics. Given the complexity and scale of modern cloud systems, this task can be challenging and may require extensive expertise and resources beyond the capacity of individual humans. Some existing methods tackle this problem by analyzing each metric independently to detect anomalies. However, this could incur overwhelming alert storms that are difficult for engineers to diagnose manually. To pursue better performance, not only the temporal patterns of metrics but also the correlation between metrics (i.e., relational patterns) should be considered, which can be formulated as a multivariate metrics anomaly detection problem. However, most of the studies fall short of extracting these two types of features explicitly. Moreover, there exist some unlabeled anomalies mixed in the training data, which may hinder the detection performance. To address these limitations, we propose the Relational- Temporal Anomaly Detection Model (RTAnomaly) that combines the relational and temporal information of metrics. RTAnomaly employs a graph attention layer to learn the dependencies among metrics, which will further help pinpoint the anomalous metrics that may cause the anomaly effectively. In addition, we exploit the concept of positive unlabeled learning to address the issue of potential anomalies in the training data. To evaluate our method, we conduct experiments on a public dataset and two industrial datasets. RTAnomaly outperforms all the baseline models by achieving an average F1 score of 0.929 and Hit@3 of 0.920, demonstrating its superiority.
Improving the Transferability of Adversarial Samples by Path-Augmented Method
Mar 28, 2023

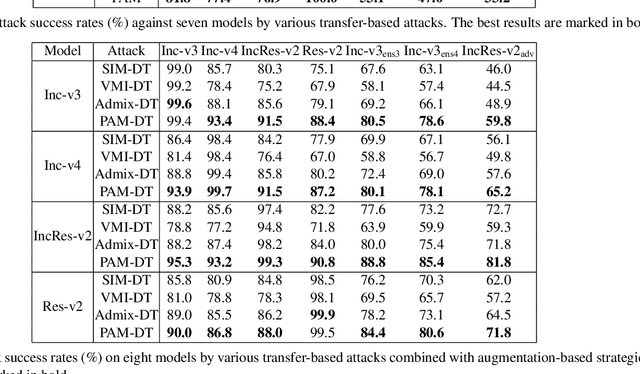

Deep neural networks have achieved unprecedented success on diverse vision tasks. However, they are vulnerable to adversarial noise that is imperceptible to humans. This phenomenon negatively affects their deployment in real-world scenarios, especially security-related ones. To evaluate the robustness of a target model in practice, transfer-based attacks craft adversarial samples with a local model and have attracted increasing attention from researchers due to their high efficiency. The state-of-the-art transfer-based attacks are generally based on data augmentation, which typically augments multiple training images from a linear path when learning adversarial samples. However, such methods selected the image augmentation path heuristically and may augment images that are semantics-inconsistent with the target images, which harms the transferability of the generated adversarial samples. To overcome the pitfall, we propose the Path-Augmented Method (PAM). Specifically, PAM first constructs a candidate augmentation path pool. It then settles the employed augmentation paths during adversarial sample generation with greedy search. Furthermore, to avoid augmenting semantics-inconsistent images, we train a Semantics Predictor (SP) to constrain the length of the augmentation path. Extensive experiments confirm that PAM can achieve an improvement of over 4.8% on average compared with the state-of-the-art baselines in terms of the attack success rates.
Heterogeneous Anomaly Detection for Software Systems via Semi-supervised Cross-modal Attention
Feb 14, 2023



Prompt and accurate detection of system anomalies is essential to ensure the reliability of software systems. Unlike manual efforts that exploit all available run-time information, existing approaches usually leverage only a single type of monitoring data (often logs or metrics) or fail to make effective use of the joint information among different types of data. Consequently, many false predictions occur. To better understand the manifestations of system anomalies, we conduct a systematical study on a large amount of heterogeneous data, i.e., logs and metrics. Our study demonstrates that logs and metrics can manifest system anomalies collaboratively and complementarily, and neither of them only is sufficient. Thus, integrating heterogeneous data can help recover the complete picture of a system's health status. In this context, we propose Hades, the first end-to-end semi-supervised approach to effectively identify system anomalies based on heterogeneous data. Our approach employs a hierarchical architecture to learn a global representation of the system status by fusing log semantics and metric patterns. It captures discriminative features and meaningful interactions from heterogeneous data via a cross-modal attention module, trained in a semi-supervised manner. We evaluate Hades extensively on large-scale simulated data and datasets from Huawei Cloud. The experimental results present the effectiveness of our model in detecting system anomalies. We also release the code and the annotated dataset for replication and future research.