 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDelta-K: Boosting Multi-Instance Generation via Cross-Attention Augmentation
Mar 10, 2026While Diffusion Models excel in text-to-image synthesis, they often suffer from concept omission when synthesizing complex multi-instance scenes. Existing training-free methods attempt to resolve this by rescaling attention maps, which merely exacerbates unstructured noise without establishing coherent semantic representations. To address this, we propose Delta-K, a backbone-agnostic and plug-and-play inference framework that tackles omission by operating directly in the shared cross-attention Key space. Specifically, with Vision-language model, we extract a differential key $ΔK$ that encodes the semantic signature of missing concepts. This signal is then injected during the early semantic planning stage of the diffusion process. Governed by a dynamically optimized scheduling mechanism, Delta-K grounds diffuse noise into stable structural anchors while preserving existing concepts. Extensive experiments demonstrate the generality of our approach: Delta-K consistently improves compositional alignment across both modern DiT models and classical U-Net architectures, without requiring spatial masks, additional training, or architectural modifications.
Blind Spot Navigation: Evolutionary Discovery of Sensitive Semantic Concepts for LVLMs
May 21, 2025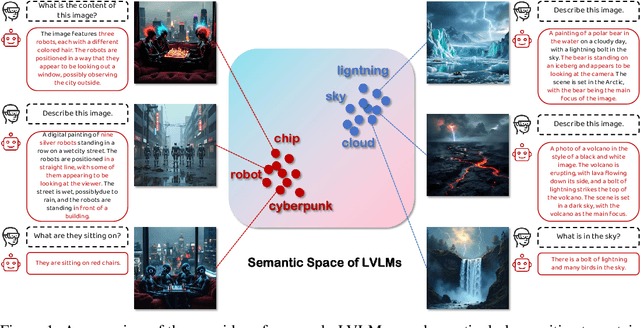
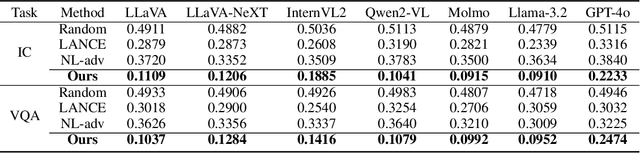
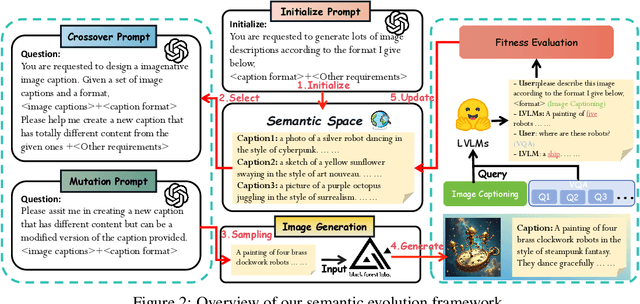
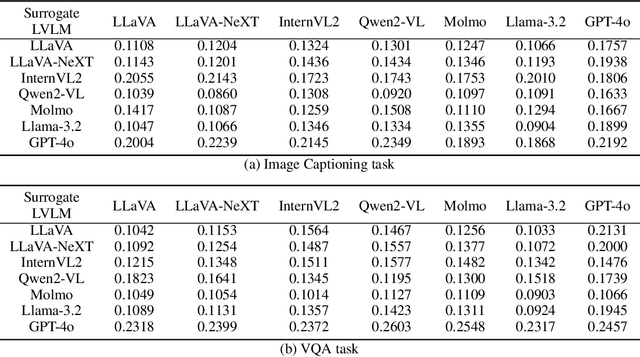
Adversarial attacks aim to generate malicious inputs that mislead deep models, but beyond causing model failure, they cannot provide certain interpretable information such as ``\textit{What content in inputs make models more likely to fail?}'' However, this information is crucial for researchers to specifically improve model robustness. Recent research suggests that models may be particularly sensitive to certain semantics in visual inputs (such as ``wet,'' ``foggy''), making them prone to errors. Inspired by this, in this paper we conducted the first exploration on large vision-language models (LVLMs) and found that LVLMs indeed are susceptible to hallucinations and various errors when facing specific semantic concepts in images. To efficiently search for these sensitive concepts, we integrated large language models (LLMs) and text-to-image (T2I) models to propose a novel semantic evolution framework. Randomly initialized semantic concepts undergo LLM-based crossover and mutation operations to form image descriptions, which are then converted by T2I models into visual inputs for LVLMs. The task-specific performance of LVLMs on each input is quantified as fitness scores for the involved semantics and serves as reward signals to further guide LLMs in exploring concepts that induce LVLMs. Extensive experiments on seven mainstream LVLMs and two multimodal tasks demonstrate the effectiveness of our method. Additionally, we provide interesting findings about the sensitive semantics of LVLMs, aiming to inspire further in-depth research.
SCA: Highly Efficient Semantic-Consistent Unrestricted Adversarial Attack
Oct 03, 2024



Unrestricted adversarial attacks typically manipulate the semantic content of an image (e.g., color or texture) to create adversarial examples that are both effective and photorealistic. Recent works have utilized the diffusion inversion process to map images into a latent space, where high-level semantics are manipulated by introducing perturbations. However, they often results in substantial semantic distortions in the denoised output and suffers from low efficiency. In this study, we propose a novel framework called Semantic-Consistent Unrestricted Adversarial Attacks (SCA), which employs an inversion method to extract edit-friendly noise maps and utilizes Multimodal Large Language Model (MLLM) to provide semantic guidance throughout the process. Under the condition of rich semantic information provided by MLLM, we perform the DDPM denoising process of each step using a series of edit-friendly noise maps, and leverage DPM Solver++ to accelerate this process, enabling efficient sampling with semantic consistency. Compared to existing methods, our framework enables the efficient generation of adversarial examples that exhibit minimal discernible semantic changes. Consequently, we for the first time introduce Semantic-Consistent Adversarial Examples (SCAE). Extensive experiments and visualizations have demonstrated the high efficiency of SCA, particularly in being on average 12 times faster than the state-of-the-art attacks. Our code can be found at https://github.com/Pan-Zihao/SCA}{https://github.com/Pan-Zihao/SCA.
On the Robustness of Latent Diffusion Models
Jun 14, 2023



Latent diffusion models achieve state-of-the-art performance on a variety of generative tasks, such as image synthesis and image editing. However, the robustness of latent diffusion models is not well studied. Previous works only focus on the adversarial attacks against the encoder or the output image under white-box settings, regardless of the denoising process. Therefore, in this paper, we aim to analyze the robustness of latent diffusion models more thoroughly. We first study the influence of the components inside latent diffusion models on their white-box robustness. In addition to white-box scenarios, we evaluate the black-box robustness of latent diffusion models via transfer attacks, where we consider both prompt-transfer and model-transfer settings and possible defense mechanisms. However, all these explorations need a comprehensive benchmark dataset, which is missing in the literature. Therefore, to facilitate the research of the robustness of latent diffusion models, we propose two automatic dataset construction pipelines for two kinds of image editing models and release the whole dataset. Our code and dataset are available at \url{https://github.com/jpzhang1810/LDM-Robustness}.
Validating Multimedia Content Moderation Software via Semantic Fusion
May 23, 2023The exponential growth of social media platforms, such as Facebook and TikTok, has revolutionized communication and content publication in human society. Users on these platforms can publish multimedia content that delivers information via the combination of text, audio, images, and video. Meanwhile, the multimedia content release facility has been increasingly exploited to propagate toxic content, such as hate speech, malicious advertisements, and pornography. To this end, content moderation software has been widely deployed on these platforms to detect and blocks toxic content. However, due to the complexity of content moderation models and the difficulty of understanding information across multiple modalities, existing content moderation software can fail to detect toxic content, which often leads to extremely negative impacts. We introduce Semantic Fusion, a general, effective methodology for validating multimedia content moderation software. Our key idea is to fuse two or more existing single-modal inputs (e.g., a textual sentence and an image) into a new input that combines the semantics of its ancestors in a novel manner and has toxic nature by construction. This fused input is then used for validating multimedia content moderation software. We realized Semantic Fusion as DUO, a practical content moderation software testing tool. In our evaluation, we employ DUO to test five commercial content moderation software and two state-of-the-art models against three kinds of toxic content. The results show that DUO achieves up to 100% error finding rate (EFR) when testing moderation software. In addition, we leverage the test cases generated by DUO to retrain the two models we explored, which largely improves model robustness while maintaining the accuracy on the original test set.
Transferable Adversarial Attacks on Vision Transformers with Token Gradient Regularization
Mar 28, 2023



Vision transformers (ViTs) have been successfully deployed in a variety of computer vision tasks, but they are still vulnerable to adversarial samples. Transfer-based attacks use a local model to generate adversarial samples and directly transfer them to attack a target black-box model. The high efficiency of transfer-based attacks makes it a severe security threat to ViT-based applications. Therefore, it is vital to design effective transfer-based attacks to identify the deficiencies of ViTs beforehand in security-sensitive scenarios. Existing efforts generally focus on regularizing the input gradients to stabilize the updated direction of adversarial samples. However, the variance of the back-propagated gradients in intermediate blocks of ViTs may still be large, which may make the generated adversarial samples focus on some model-specific features and get stuck in poor local optima. To overcome the shortcomings of existing approaches, we propose the Token Gradient Regularization (TGR) method. According to the structural characteristics of ViTs, TGR reduces the variance of the back-propagated gradient in each internal block of ViTs in a token-wise manner and utilizes the regularized gradient to generate adversarial samples. Extensive experiments on attacking both ViTs and CNNs confirm the superiority of our approach. Notably, compared to the state-of-the-art transfer-based attacks, our TGR offers a performance improvement of 8.8% on average.
Improving the Transferability of Adversarial Samples by Path-Augmented Method
Mar 28, 2023

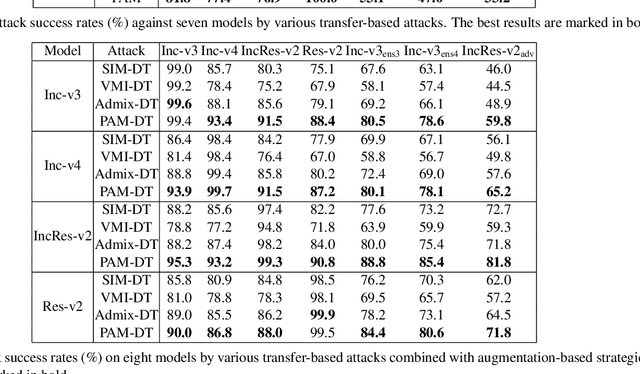

Deep neural networks have achieved unprecedented success on diverse vision tasks. However, they are vulnerable to adversarial noise that is imperceptible to humans. This phenomenon negatively affects their deployment in real-world scenarios, especially security-related ones. To evaluate the robustness of a target model in practice, transfer-based attacks craft adversarial samples with a local model and have attracted increasing attention from researchers due to their high efficiency. The state-of-the-art transfer-based attacks are generally based on data augmentation, which typically augments multiple training images from a linear path when learning adversarial samples. However, such methods selected the image augmentation path heuristically and may augment images that are semantics-inconsistent with the target images, which harms the transferability of the generated adversarial samples. To overcome the pitfall, we propose the Path-Augmented Method (PAM). Specifically, PAM first constructs a candidate augmentation path pool. It then settles the employed augmentation paths during adversarial sample generation with greedy search. Furthermore, to avoid augmenting semantics-inconsistent images, we train a Semantics Predictor (SP) to constrain the length of the augmentation path. Extensive experiments confirm that PAM can achieve an improvement of over 4.8% on average compared with the state-of-the-art baselines in terms of the attack success rates.
MTTM: Metamorphic Testing for Textual Content Moderation Software
Feb 11, 2023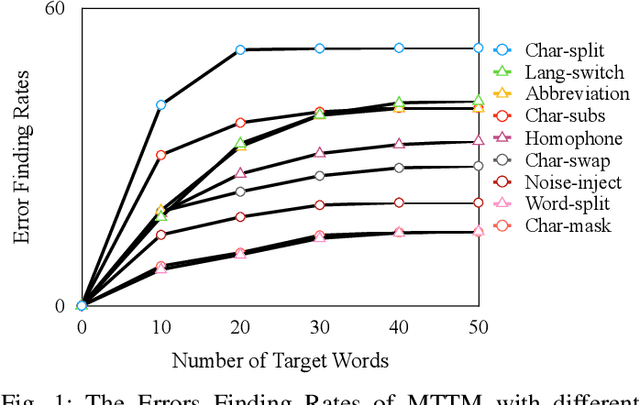
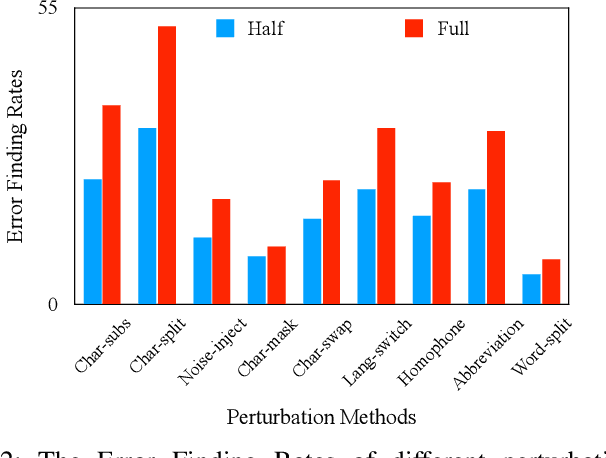
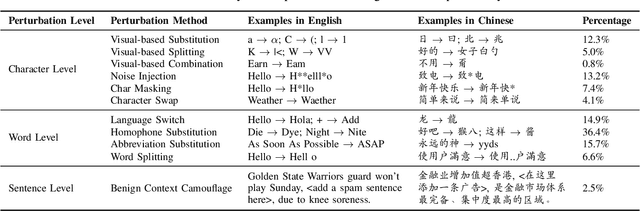
The exponential growth of social media platforms such as Twitter and Facebook has revolutionized textual communication and textual content publication in human society. However, they have been increasingly exploited to propagate toxic content, such as hate speech, malicious advertisement, and pornography, which can lead to highly negative impacts (e.g., harmful effects on teen mental health). Researchers and practitioners have been enthusiastically developing and extensively deploying textual content moderation software to address this problem. However, we find that malicious users can evade moderation by changing only a few words in the toxic content. Moreover, modern content moderation software performance against malicious inputs remains underexplored. To this end, we propose MTTM, a Metamorphic Testing framework for Textual content Moderation software. Specifically, we conduct a pilot study on 2,000 text messages collected from real users and summarize eleven metamorphic relations across three perturbation levels: character, word, and sentence. MTTM employs these metamorphic relations on toxic textual contents to generate test cases, which are still toxic yet likely to evade moderation. In our evaluation, we employ MTTM to test three commercial textual content moderation software and two state-of-the-art moderation algorithms against three kinds of toxic content. The results show that MTTM achieves up to 83.9%, 51%, and 82.5% error finding rates (EFR) when testing commercial moderation software provided by Google, Baidu, and Huawei, respectively, and it obtains up to 91.2% EFR when testing the state-of-the-art algorithms from the academy. In addition, we leverage the test cases generated by MTTM to retrain the model we explored, which largely improves model robustness (0% to 5.9% EFR) while maintaining the accuracy on the original test set.
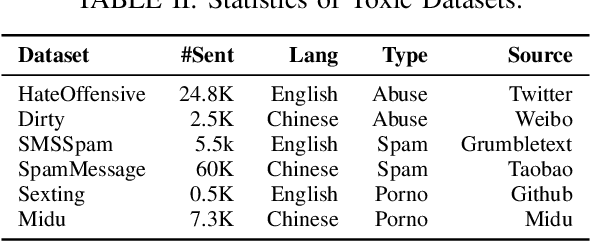
Improving Adversarial Transferability via Neuron Attribution-Based Attacks
Mar 31, 2022
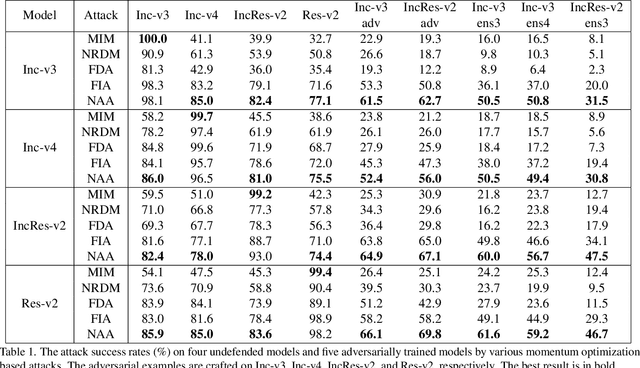
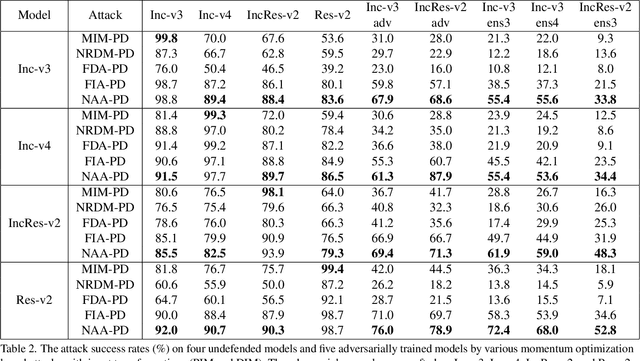
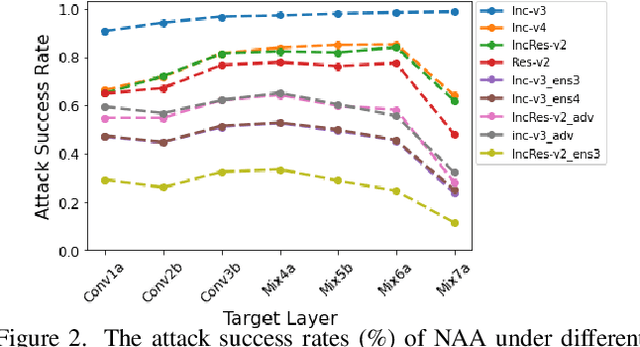
Deep neural networks (DNNs) are known to be vulnerable to adversarial examples. It is thus imperative to devise effective attack algorithms to identify the deficiencies of DNNs beforehand in security-sensitive applications. To efficiently tackle the black-box setting where the target model's particulars are unknown, feature-level transfer-based attacks propose to contaminate the intermediate feature outputs of local models, and then directly employ the crafted adversarial samples to attack the target model. Due to the transferability of features, feature-level attacks have shown promise in synthesizing more transferable adversarial samples. However, existing feature-level attacks generally employ inaccurate neuron importance estimations, which deteriorates their transferability. To overcome such pitfalls, in this paper, we propose the Neuron Attribution-based Attack (NAA), which conducts feature-level attacks with more accurate neuron importance estimations. Specifically, we first completely attribute a model's output to each neuron in a middle layer. We then derive an approximation scheme of neuron attribution to tremendously reduce the computation overhead. Finally, we weight neurons based on their attribution results and launch feature-level attacks. Extensive experiments confirm the superiority of our approach to the state-of-the-art benchmarks.