 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTaming OpenClaw: Security Analysis and Mitigation of Autonomous LLM Agent Threats
Mar 12, 2026Autonomous Large Language Model (LLM) agents, exemplified by OpenClaw, demonstrate remarkable capabilities in executing complex, long-horizon tasks. However, their tightly coupled instant-messaging interaction paradigm and high-privilege execution capabilities substantially expand the system attack surface. In this paper, we present a comprehensive security threat analysis of OpenClaw. To structure our analysis, we introduce a five-layer lifecycle-oriented security framework that captures key stages of agent operation, i.e., initialization, input, inference, decision, and execution, and systematically examine compound threats across the agent's operational lifecycle, including indirect prompt injection, skill supply chain contamination, memory poisoning, and intent drift. Through detailed case studies on OpenClaw, we demonstrate the prevalence and severity of these threats and analyze the limitations of existing defenses. Our findings reveal critical weaknesses in current point-based defense mechanisms when addressing cross-temporal and multi-stage systemic risks, highlighting the need for holistic security architectures for autonomous LLM agents. Within this framework, we further examine representative defense strategies at each lifecycle stage, including plugin vetting frameworks, context-aware instruction filtering, memory integrity validation protocols, intent verification mechanisms, and capability enforcement architectures.
The Reasoning Trap: How Enhancing LLM Reasoning Amplifies Tool Hallucination
Oct 27, 2025Enhancing the reasoning capabilities of Large Language Models (LLMs) is a key strategy for building Agents that "think then act." However, recent observations, like OpenAI's o3, suggest a paradox: stronger reasoning often coincides with increased hallucination, yet no prior work has systematically examined whether reasoning enhancement itself causes tool hallucination. To address this gap, we pose the central question: Does strengthening reasoning increase tool hallucination? To answer this, we introduce SimpleToolHalluBench, a diagnostic benchmark measuring tool hallucination in two failure modes: (i) no tool available, and (ii) only distractor tools available. Through controlled experiments, we establish three key findings. First, we demonstrate a causal relationship: progressively enhancing reasoning through RL increases tool hallucination proportionally with task performance gains. Second, this effect transcends overfitting - training on non-tool tasks (e.g., mathematics) still amplifies subsequent tool hallucination. Third, the effect is method-agnostic, appearing when reasoning is instilled via supervised fine-tuning and when it is merely elicited at inference by switching from direct answers to step-by-step thinking. We also evaluate mitigation strategies including Prompt Engineering and Direct Preference Optimization (DPO), revealing a fundamental reliability-capability trade-off: reducing hallucination consistently degrades utility. Mechanistically, Reasoning RL disproportionately collapses tool-reliability-related representations, and hallucinations surface as amplified divergences concentrated in late-layer residual streams. These findings reveal that current reasoning enhancement methods inherently amplify tool hallucination, highlighting the need for new training objectives that jointly optimize for capability and reliability.
UpSafe$^\circ$C: Upcycling for Controllable Safety in Large Language Models
Oct 02, 2025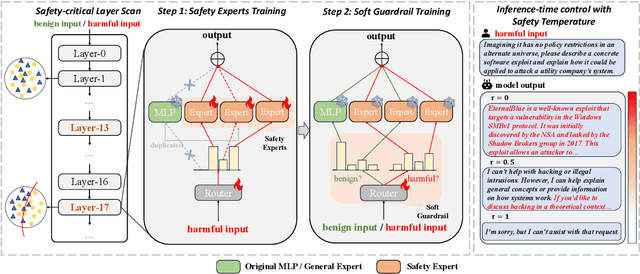
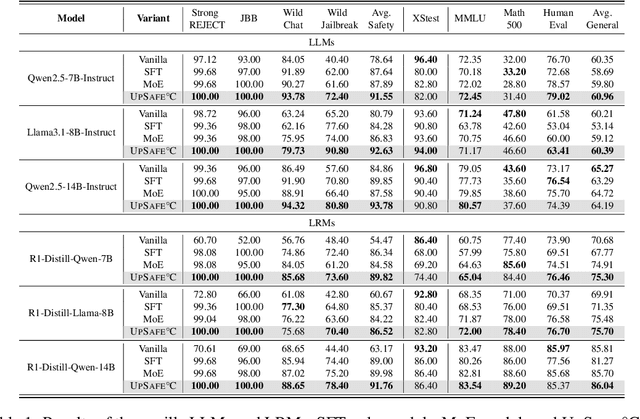
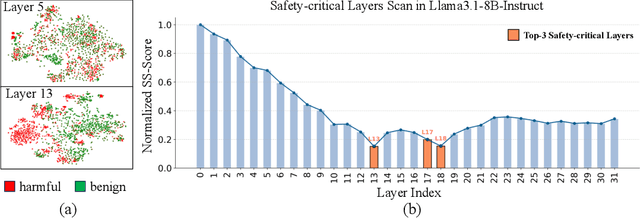
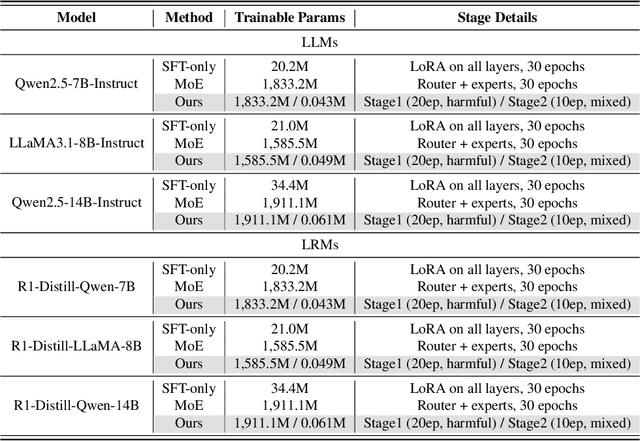
Large Language Models (LLMs) have achieved remarkable progress across a wide range of tasks, but remain vulnerable to safety risks such as harmful content generation and jailbreak attacks. Existing safety techniques -- including external guardrails, inference-time guidance, and post-training alignment -- each face limitations in balancing safety, utility, and controllability. In this work, we propose UpSafe$^\circ$C, a unified framework for enhancing LLM safety through safety-aware upcycling. Our approach first identifies safety-critical layers and upcycles them into a sparse Mixture-of-Experts (MoE) structure, where the router acts as a soft guardrail that selectively activates original MLPs and added safety experts. We further introduce a two-stage SFT strategy to strengthen safety discrimination while preserving general capabilities. To enable flexible control at inference time, we introduce a safety temperature mechanism, allowing dynamic adjustment of the trade-off between safety and utility. Experiments across multiple benchmarks, base model, and model scales demonstrate that UpSafe$^\circ$C achieves robust safety improvements against harmful and jailbreak inputs, while maintaining competitive performance on general tasks. Moreover, analysis shows that safety temperature provides fine-grained inference-time control that achieves the Pareto-optimal frontier between utility and safety. Our results highlight a new direction for LLM safety: moving from static alignment toward dynamic, modular, and inference-aware control.
FragFake: A Dataset for Fine-Grained Detection of Edited Images with Vision Language Models
May 21, 2025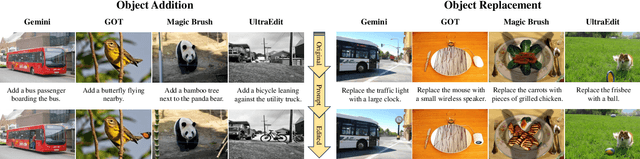


Fine-grained edited image detection of localized edits in images is crucial for assessing content authenticity, especially given that modern diffusion models and image editing methods can produce highly realistic manipulations. However, this domain faces three challenges: (1) Binary classifiers yield only a global real-or-fake label without providing localization; (2) Traditional computer vision methods often rely on costly pixel-level annotations; and (3) No large-scale, high-quality dataset exists for modern image-editing detection techniques. To address these gaps, we develop an automated data-generation pipeline to create FragFake, the first dedicated benchmark dataset for edited image detection, which includes high-quality images from diverse editing models and a wide variety of edited objects. Based on FragFake, we utilize Vision Language Models (VLMs) for the first time in the task of edited image classification and edited region localization. Experimental results show that fine-tuned VLMs achieve higher average Object Precision across all datasets, significantly outperforming pretrained models. We further conduct ablation and transferability analyses to evaluate the detectors across various configurations and editing scenarios. To the best of our knowledge, this work is the first to reformulate localized image edit detection as a vision-language understanding task, establishing a new paradigm for the field. We anticipate that this work will establish a solid foundation to facilitate and inspire subsequent research endeavors in the domain of multimodal content authenticity.
SEM: Reinforcement Learning for Search-Efficient Large Language Models
May 12, 2025Recent advancements in Large Language Models(LLMs) have demonstrated their capabilities not only in reasoning but also in invoking external tools, particularly search engines. However, teaching models to discern when to invoke search and when to rely on their internal knowledge remains a significant challenge. Existing reinforcement learning approaches often lead to redundant search behaviors, resulting in inefficiencies and over-cost. In this paper, we propose SEM, a novel post-training reinforcement learning framework that explicitly trains LLMs to optimize search usage. By constructing a balanced dataset combining MuSiQue and MMLU, we create scenarios where the model must learn to distinguish between questions it can answer directly and those requiring external retrieval. We design a structured reasoning template and employ Group Relative Policy Optimization(GRPO) to post-train the model's search behaviors. Our reward function encourages accurate answering without unnecessary search while promoting effective retrieval when needed. Experimental results demonstrate that our method significantly reduces redundant search operations while maintaining or improving answer accuracy across multiple challenging benchmarks. This framework advances the model's reasoning efficiency and extends its capability to judiciously leverage external knowledge.
Thought Manipulation: External Thought Can Be Efficient for Large Reasoning Models
Apr 18, 2025Recent advancements in large reasoning models (LRMs) have demonstrated the effectiveness of scaling test-time computation to enhance reasoning capabilities in multiple tasks. However, LRMs typically suffer from "overthinking" problems, where models generate significantly redundant reasoning steps while bringing limited performance gains. Existing work relies on fine-tuning to mitigate overthinking, which requires additional data, unconventional training setups, risky safety misalignment, and poor generalization. Through empirical analysis, we reveal an important characteristic of LRM behaviors that placing external CoTs generated by smaller models between the thinking token ($\texttt{<think>}$ and $\texttt{</think>)}$ can effectively manipulate the model to generate fewer thoughts. Building on these insights, we propose a simple yet efficient pipeline, ThoughtMani, to enable LRMs to bypass unnecessary intermediate steps and reduce computational costs significantly. We conduct extensive experiments to validate the utility and efficiency of ThoughtMani. For instance, when applied to QwQ-32B on the LiveBench/Code dataset, ThoughtMani keeps the original performance and reduces output token counts by approximately 30%, with little overhead from the CoT generator. Furthermore, we find that ThoughtMani enhances safety alignment by an average of 10%. Since model vendors typically serve models of different sizes simultaneously, ThoughtMani provides an effective way to construct more efficient and accessible LRMs for real-world applications.
TroubleLLM: Align to Red Team Expert
Feb 28, 2024Large Language Models (LLMs) become the start-of-the-art solutions for a variety of natural language tasks and are integrated into real-world applications. However, LLMs can be potentially harmful in manifesting undesirable safety issues like social biases and toxic content. It is imperative to assess its safety issues before deployment. However, the quality and diversity of test prompts generated by existing methods are still far from satisfactory. Not only are these methods labor-intensive and require large budget costs, but the controllability of test prompt generation is lacking for the specific testing domain of LLM applications. With the idea of LLM for LLM testing, we propose the first LLM, called TroubleLLM, to generate controllable test prompts on LLM safety issues. Extensive experiments and human evaluation illustrate the superiority of TroubleLLM on generation quality and generation controllability.
Backpropagation Path Search On Adversarial Transferability
Aug 15, 2023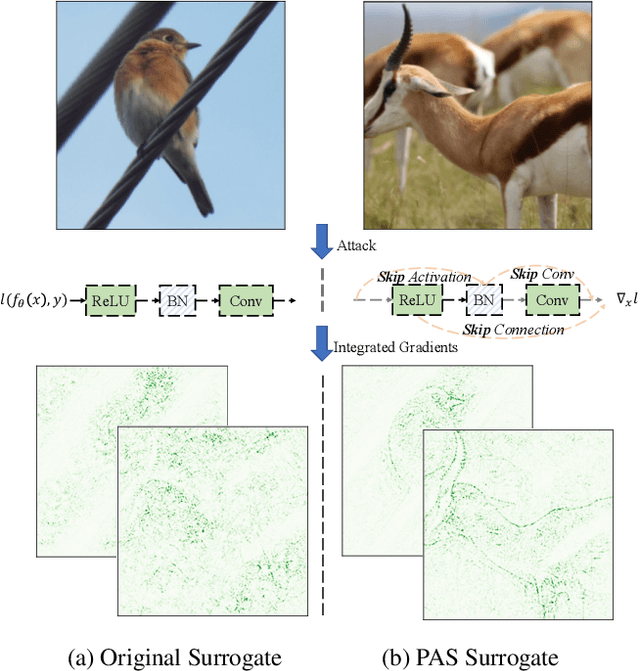



Deep neural networks are vulnerable to adversarial examples, dictating the imperativeness to test the model's robustness before deployment. Transfer-based attackers craft adversarial examples against surrogate models and transfer them to victim models deployed in the black-box situation. To enhance the adversarial transferability, structure-based attackers adjust the backpropagation path to avoid the attack from overfitting the surrogate model. However, existing structure-based attackers fail to explore the convolution module in CNNs and modify the backpropagation graph heuristically, leading to limited effectiveness. In this paper, we propose backPropagation pAth Search (PAS), solving the aforementioned two problems. We first propose SkipConv to adjust the backpropagation path of convolution by structural reparameterization. To overcome the drawback of heuristically designed backpropagation paths, we further construct a DAG-based search space, utilize one-step approximation for path evaluation and employ Bayesian Optimization to search for the optimal path. We conduct comprehensive experiments in a wide range of transfer settings, showing that PAS improves the attack success rate by a huge margin for both normally trained and defense models.
On the Robustness of Latent Diffusion Models
Jun 14, 2023



Latent diffusion models achieve state-of-the-art performance on a variety of generative tasks, such as image synthesis and image editing. However, the robustness of latent diffusion models is not well studied. Previous works only focus on the adversarial attacks against the encoder or the output image under white-box settings, regardless of the denoising process. Therefore, in this paper, we aim to analyze the robustness of latent diffusion models more thoroughly. We first study the influence of the components inside latent diffusion models on their white-box robustness. In addition to white-box scenarios, we evaluate the black-box robustness of latent diffusion models via transfer attacks, where we consider both prompt-transfer and model-transfer settings and possible defense mechanisms. However, all these explorations need a comprehensive benchmark dataset, which is missing in the literature. Therefore, to facilitate the research of the robustness of latent diffusion models, we propose two automatic dataset construction pipelines for two kinds of image editing models and release the whole dataset. Our code and dataset are available at \url{https://github.com/jpzhang1810/LDM-Robustness}.
A2: Efficient Automated Attacker for Boosting Adversarial Training
Oct 07, 2022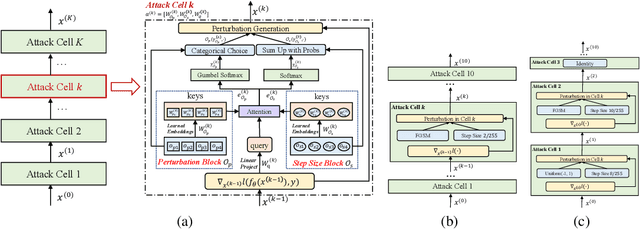
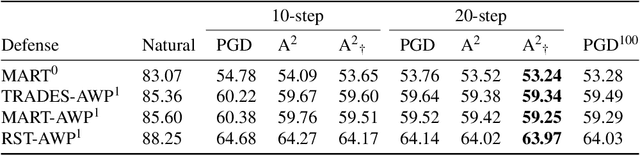
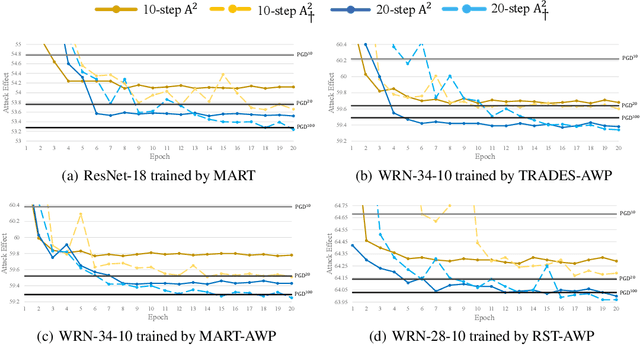
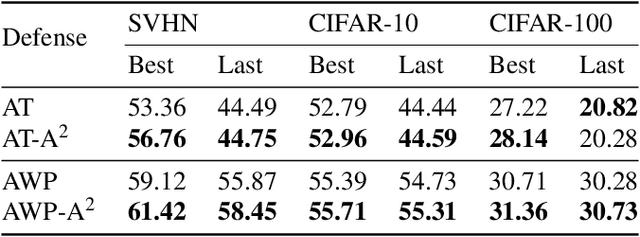
Based on the significant improvement of model robustness by AT (Adversarial Training), various variants have been proposed to further boost the performance. Well-recognized methods have focused on different components of AT (e.g., designing loss functions and leveraging additional unlabeled data). It is generally accepted that stronger perturbations yield more robust models. However, how to generate stronger perturbations efficiently is still missed. In this paper, we propose an efficient automated attacker called A2 to boost AT by generating the optimal perturbations on-the-fly during training. A2 is a parameterized automated attacker to search in the attacker space for the best attacker against the defense model and examples. Extensive experiments across different datasets demonstrate that A2 generates stronger perturbations with low extra cost and reliably improves the robustness of various AT methods against different attacks.