 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZPD-SCA: Unveiling the Blind Spots of LLMs in Assessing Students' Cognitive Abilities
Aug 20, 2025


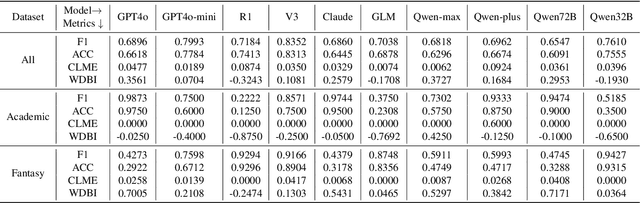
Large language models (LLMs) have demonstrated potential in educational applications, yet their capacity to accurately assess the cognitive alignment of reading materials with students' developmental stages remains insufficiently explored. This gap is particularly critical given the foundational educational principle of the Zone of Proximal Development (ZPD), which emphasizes the need to match learning resources with Students' Cognitive Abilities (SCA). Despite the importance of this alignment, there is a notable absence of comprehensive studies investigating LLMs' ability to evaluate reading comprehension difficulty across different student age groups, especially in the context of Chinese language education. To fill this gap, we introduce ZPD-SCA, a novel benchmark specifically designed to assess stage-level Chinese reading comprehension difficulty. The benchmark is annotated by 60 Special Grade teachers, a group that represents the top 0.15% of all in-service teachers nationwide. Experimental results reveal that LLMs perform poorly in zero-shot learning scenarios, with Qwen-max and GLM even falling below the probability of random guessing. When provided with in-context examples, LLMs performance improves substantially, with some models achieving nearly double the accuracy of their zero-shot baselines. These results reveal that LLMs possess emerging abilities to assess reading difficulty, while also exposing limitations in their current training for educationally aligned judgment. Notably, even the best-performing models display systematic directional biases, suggesting difficulties in accurately aligning material difficulty with SCA. Furthermore, significant variations in model performance across different genres underscore the complexity of task. We envision that ZPD-SCA can provide a foundation for evaluating and improving LLMs in cognitively aligned educational applications.
Culinary Crossroads: A RAG Framework for Enhancing Diversity in Cross-Cultural Recipe Adaptation
Jul 29, 2025In cross-cultural recipe adaptation, the goal is not only to ensure cultural appropriateness and retain the original dish's essence, but also to provide diverse options for various dietary needs and preferences. Retrieval Augmented Generation (RAG) is a promising approach, combining the retrieval of real recipes from the target cuisine for cultural adaptability with large language models (LLMs) for relevance. However, it remains unclear whether RAG can generate diverse adaptation results. Our analysis shows that RAG tends to overly rely on a limited portion of the context across generations, failing to produce diverse outputs even when provided with varied contextual inputs. This reveals a key limitation of RAG in creative tasks with multiple valid answers: it fails to leverage contextual diversity for generating varied responses. To address this issue, we propose CARRIAGE, a plug-and-play RAG framework for cross-cultural recipe adaptation that enhances diversity in both retrieval and context organization. To our knowledge, this is the first RAG framework that explicitly aims to generate highly diverse outputs to accommodate multiple user preferences. Our experiments show that CARRIAGE achieves Pareto efficiency in terms of diversity and quality of recipe adaptation compared to closed-book LLMs.
Evaluation Hallucination in Multi-Round Incomplete Information Lateral-Driven Reasoning Tasks
May 28, 2025


Multi-round incomplete information tasks are crucial for evaluating the lateral thinking capabilities of large language models (LLMs). Currently, research primarily relies on multiple benchmarks and automated evaluation metrics to assess these abilities. However, our study reveals novel insights into the limitations of existing methods, as they often yield misleading results that fail to uncover key issues, such as shortcut-taking behaviors, rigid patterns, and premature task termination. These issues obscure the true reasoning capabilities of LLMs and undermine the reliability of evaluations. To address these limitations, we propose a refined set of evaluation standards, including inspection of reasoning paths, diversified assessment metrics, and comparative analyses with human performance.
JALMBench: Benchmarking Jailbreak Vulnerabilities in Audio Language Models
May 23, 2025


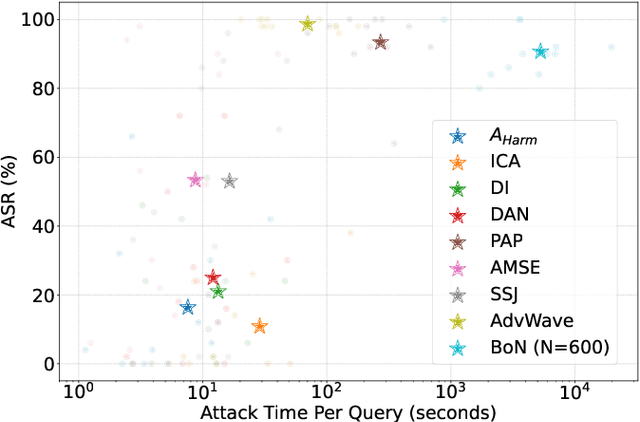
Audio Language Models (ALMs) have made significant progress recently. These models integrate the audio modality directly into the model, rather than converting speech into text and inputting text to Large Language Models (LLMs). While jailbreak attacks on LLMs have been extensively studied, the security of ALMs with audio modalities remains largely unexplored. Currently, there is a lack of an adversarial audio dataset and a unified framework specifically designed to evaluate and compare attacks and ALMs. In this paper, we present JALMBench, the \textit{first} comprehensive benchmark to assess the safety of ALMs against jailbreak attacks. JALMBench includes a dataset containing 2,200 text samples and 51,381 audio samples with over 268 hours. It supports 12 mainstream ALMs, 4 text-transferred and 4 audio-originated attack methods, and 5 defense methods. Using JALMBench, we provide an in-depth analysis of attack efficiency, topic sensitivity, voice diversity, and attack representations. Additionally, we explore mitigation strategies for the attacks at both the prompt level and the response level.
Humanizing LLMs: A Survey of Psychological Measurements with Tools, Datasets, and Human-Agent Applications
Apr 30, 2025



As large language models (LLMs) are increasingly used in human-centered tasks, assessing their psychological traits is crucial for understanding their social impact and ensuring trustworthy AI alignment. While existing reviews have covered some aspects of related research, several important areas have not been systematically discussed, including detailed discussions of diverse psychological tests, LLM-specific psychological datasets, and the applications of LLMs with psychological traits. To address this gap, we systematically review six key dimensions of applying psychological theories to LLMs: (1) assessment tools; (2) LLM-specific datasets; (3) evaluation metrics (consistency and stability); (4) empirical findings; (5) personality simulation methods; and (6) LLM-based behavior simulation. Our analysis highlights both the strengths and limitations of current methods. While some LLMs exhibit reproducible personality patterns under specific prompting schemes, significant variability remains across tasks and settings. Recognizing methodological challenges such as mismatches between psychological tools and LLMs' capabilities, as well as inconsistencies in evaluation practices, this study aims to propose future directions for developing more interpretable, robust, and generalizable psychological assessment frameworks for LLMs.
Thought Manipulation: External Thought Can Be Efficient for Large Reasoning Models
Apr 18, 2025Recent advancements in large reasoning models (LRMs) have demonstrated the effectiveness of scaling test-time computation to enhance reasoning capabilities in multiple tasks. However, LRMs typically suffer from "overthinking" problems, where models generate significantly redundant reasoning steps while bringing limited performance gains. Existing work relies on fine-tuning to mitigate overthinking, which requires additional data, unconventional training setups, risky safety misalignment, and poor generalization. Through empirical analysis, we reveal an important characteristic of LRM behaviors that placing external CoTs generated by smaller models between the thinking token ($\texttt{<think>}$ and $\texttt{</think>)}$ can effectively manipulate the model to generate fewer thoughts. Building on these insights, we propose a simple yet efficient pipeline, ThoughtMani, to enable LRMs to bypass unnecessary intermediate steps and reduce computational costs significantly. We conduct extensive experiments to validate the utility and efficiency of ThoughtMani. For instance, when applied to QwQ-32B on the LiveBench/Code dataset, ThoughtMani keeps the original performance and reduces output token counts by approximately 30%, with little overhead from the CoT generator. Furthermore, we find that ThoughtMani enhances safety alignment by an average of 10%. Since model vendors typically serve models of different sizes simultaneously, ThoughtMani provides an effective way to construct more efficient and accessible LRMs for real-world applications.
The Rising Threat to Emerging AI-Powered Search Engines
Feb 07, 2025



Recent advancements in Large Language Models (LLMs) have significantly enhanced the capabilities of AI-Powered Search Engines (AIPSEs), offering precise and efficient responses by integrating external databases with pre-existing knowledge. However, we observe that these AIPSEs raise risks such as quoting malicious content or citing malicious websites, leading to harmful or unverified information dissemination. In this study, we conduct the first safety risk quantification on seven production AIPSEs by systematically defining the threat model, risk level, and evaluating responses to various query types. With data collected from PhishTank, ThreatBook, and LevelBlue, our findings reveal that AIPSEs frequently generate harmful content that contains malicious URLs even with benign queries (e.g., with benign keywords). We also observe that directly query URL will increase the risk level while query with natural language will mitigate such risk. We further perform two case studies on online document spoofing and phishing to show the ease of deceiving AIPSEs in the real-world setting. To mitigate these risks, we develop an agent-based defense with a GPT-4o-based content refinement tool and an XGBoost-based URL detector. Our evaluation shows that our defense can effectively reduce the risk but with the cost of reducing available information. Our research highlights the urgent need for robust safety measures in AIPSEs.
CL-attack: Textual Backdoor Attacks via Cross-Lingual Triggers
Dec 26, 2024



Backdoor attacks significantly compromise the security of large language models by triggering them to output specific and controlled content. Currently, triggers for textual backdoor attacks fall into two categories: fixed-token triggers and sentence-pattern triggers. However, the former are typically easy to identify and filter, while the latter, such as syntax and style, do not apply to all original samples and may lead to semantic shifts. In this paper, inspired by cross-lingual (CL) prompts of LLMs in real-world scenarios, we propose a higher-dimensional trigger method at the paragraph level, namely CL-attack. CL-attack injects the backdoor by using texts with specific structures that incorporate multiple languages, thereby offering greater stealthiness and universality compared to existing backdoor attack techniques. Extensive experiments on different tasks and model architectures demonstrate that CL-attack can achieve nearly 100% attack success rate with a low poisoning rate in both classification and generation tasks. We also empirically show that the CL-attack is more robust against current major defense methods compared to baseline backdoor attacks. Additionally, to mitigate CL-attack, we further develop a new defense called TranslateDefense, which can partially mitigate the impact of CL-attack.
On the Generalization Ability of Machine-Generated Text Detectors
Dec 23, 2024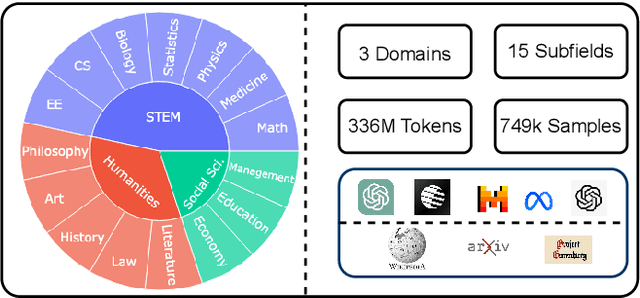
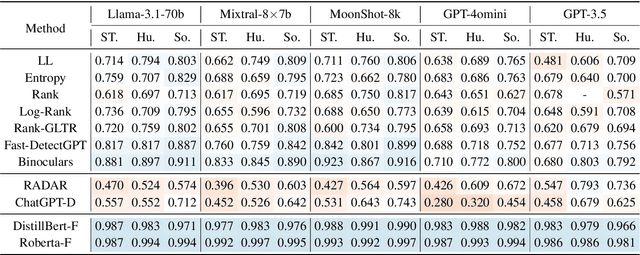

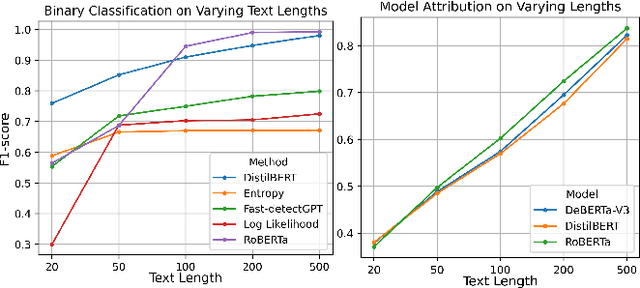
The rise of large language models (LLMs) has raised concerns about machine-generated text (MGT), including ethical and practical issues like plagiarism and misinformation. Building a robust and highly generalizable MGT detection system has become increasingly important. This work investigates the generalization capabilities of MGT detectors in three aspects: First, we construct MGTAcademic, a large-scale dataset focused on academic writing, featuring human-written texts (HWTs) and MGTs across STEM, Humanities, and Social Sciences, paired with an extensible code framework for efficient benchmarking. Second, we investigate the transferability of detectors across domains and LLMs, leveraging fine-grained datasets to reveal insights into domain transferring and implementing few-shot techniques to improve the performance by roughly 13.2%. Third, we introduce a novel attribution task where models must adapt to new classes over time without (or with very limited) access to prior training data and benchmark detectors. We implement several adapting techniques to improve the performance by roughly 10% and highlight the inherent complexity of the task. Our findings provide insights into the generalization ability of MGT detectors across diverse scenarios and lay the foundation for building robust, adaptive detection systems.
JailbreakEval: An Integrated Toolkit for Evaluating Jailbreak Attempts Against Large Language Models
Jun 13, 2024Jailbreak attacks aim to induce Large Language Models (LLMs) to generate harmful responses for forbidden instructions, presenting severe misuse threats to LLMs. Up to now, research into jailbreak attacks and defenses is emerging, however, there is (surprisingly) no consensus on how to evaluate whether a jailbreak attempt is successful. In other words, the methods to assess the harmfulness of an LLM's response are varied, such as manual annotation or prompting GPT-4 in specific ways. Each approach has its own set of strengths and weaknesses, impacting their alignment with human values, as well as the time and financial cost. This diversity in evaluation presents challenges for researchers in choosing suitable evaluation methods and conducting fair comparisons across different jailbreak attacks and defenses. In this paper, we conduct a comprehensive analysis of jailbreak evaluation methodologies, drawing from nearly ninety jailbreak research released between May 2023 and April 2024. Our study introduces a systematic taxonomy of jailbreak evaluators, offering in-depth insights into their strengths and weaknesses, along with the current status of their adaptation. Moreover, to facilitate subsequent research, we propose JailbreakEval, a user-friendly toolkit focusing on the evaluation of jailbreak attempts. It includes various well-known evaluators out-of-the-box, so that users can obtain evaluation results with only a single command. JailbreakEval also allows users to customize their own evaluation workflow in a unified framework with the ease of development and comparison. In summary, we regard JailbreakEval to be a catalyst that simplifies the evaluation process in jailbreak research and fosters an inclusive standard for jailbreak evaluation within the community.