 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatialFly: Geometry-Guided Representation Alignment for UAV Vision-and-Language Navigation in Urban Environments
Mar 22, 2026UAVs play an important role in applications such as autonomous exploration, disaster response, and infrastructure inspection. However, UAV VLN in complex 3D environments remains challenging. A key difficulty is the structural representation mismatch between 2D visual perception and the 3D trajectory decision space, which limits spatial reasoning. To this end, we propose SpatialFly, a geometry-guided spatial representation framework for UAV VLN. Operating on RGB observations without explicit 3D reconstruction, SpatialFly introduces a geometry-guided 2D representation alignment mechanism. Specifically, the geometric prior injection module injects global structural cues into 2D semantic tokens to provide scene-level geometric guidance. The geometry-aware reparameterization module then aligns 2D semantic tokens with 3D geometric tokens through cross-modal attention, followed by gated residual fusion to preserve semantic discrimination. Experimental results show that SpatialFly consistently outperforms state-of-the-art UAV VLN baselines across both seen and unseen environments, reducing NE by 4.03m and improving SR by 1.27% over the strongest baseline on the unseen Full split. Additional trajectory-level analysis shows that SpatialFly produces trajectories with better path alignment and smoother, more stable motion.
CTFS : Collaborative Teacher Framework for Forward-Looking Sonar Image Semantic Segmentation with Extremely Limited Labels
Mar 22, 2026As one of the most important underwater sensing technologies, forward-looking sonar exhibits unique imaging characteristics. Sonar images are often affected by severe speckle noise, low texture contrast, acoustic shadows, and geometric distortions. These factors make it difficult for traditional teacher-student frameworks to achieve satisfactory performance in sonar semantic segmentation tasks under extremely limited labeled data conditions. To address this issue, we propose a Collaborative Teacher Semantic Segmentation Framework for forward-looking sonar images. This framework introduces a multi-teacher collaborative mechanism composed of one general teacher and multiple sonar-specific teachers. By adopting a multi-teacher alternating guidance strategy, the student model can learn general semantic representations while simultaneously capturing the unique characteristics of sonar images, thereby achieving more comprehensive and robust feature modeling. Considering the challenges of sonar images, which can lead teachers to generate a large number of noisy pseudo-labels, we further design a cross-teacher reliability assessment mechanism. This mechanism dynamically quantifies the reliability of pseudo-labels by evaluating the consistency and stability of predictions across multiple views and multiple teachers, thereby mitigating the negative impact caused by noisy pseudo-labels. Notably, on the FLSMD dataset, when only 2% of the data is labeled, our method achieves a 5.08% improvement in mIoU compared to other state-of-the-art approaches.
UniFusion: A Unified Image Fusion Framework with Robust Representation and Source-Aware Preservation
Mar 15, 2026Image fusion aims to integrate complementary information from multiple source images to produce a more informative and visually consistent representation, benefiting both human perception and downstream vision tasks. Despite recent progress, most existing fusion methods are designed for specific tasks (i.e., multi-modal, multi-exposure, or multi-focus fusion) and struggle to effectively preserve source information during the fusion process. This limitation primarily arises from task-specific architectures and the degradation of source information caused by deep-layer propagation. To overcome these issues, we propose UniFusion, a unified image fusion framework designed to achieve cross-task generalization. First, leveraging DINOv3 for modality-consistent feature extraction, UniFusion establishes a shared semantic space for diverse inputs. Second, to preserve the understanding of each source image, we introduce a reconstruction-alignment loss to maintain consistency between fused outputs and inputs. Finally, we employ a bilevel optimization strategy to decouple and jointly optimize reconstruction and fusion objectives, effectively balancing their coupling relationship and ensuring smooth convergence. Extensive experiments across multiple fusion tasks demonstrate UniFusion's superior visual quality, generalization ability, and adaptability to real-world scenarios. Code is available at https://github.com/dusongcheng/UniFusion.
Toward Real-world Infrared Image Super-Resolution: A Unified Autoregressive Framework and Benchmark Dataset
Mar 05, 2026Infrared image super-resolution (IISR) under real-world conditions is a practically significant yet rarely addressed task. Pioneering works are often trained and evaluated on simulated datasets or neglect the intrinsic differences between infrared and visible imaging. In practice, however, real infrared images are affected by coupled optical and sensing degradations that jointly deteriorate both structural sharpness and thermal fidelity. To address these challenges, we propose Real-IISR, a unified autoregressive framework for real-world IISR that progressively reconstructs fine-grained thermal structures and clear backgrounds in a scale-by-scale manner via thermal-structural guided visual autoregression. Specifically, a Thermal-Structural Guidance module encodes thermal priors to mitigate the mismatch between thermal radiation and structural edges. Since non-uniform degradations typically induce quantization bias, Real-IISR adopts a Condition-Adaptive Codebook that dynamically modulates discrete representations based on degradation-aware thermal priors. Also, a Thermal Order Consistency Loss enforces a monotonic relation between temperature and pixel intensity, ensuring relative brightness order rather than absolute values to maintain physical consistency under spatial misalignment and thermal drift. We build FLIR-IISR, a real-world IISR dataset with paired LR-HR infrared images acquired via automated focus variation and motion-induced blur. Extensive experiments demonstrate the promising performance of Real-IISR, providing a unified foundation for real-world IISR and benchmarking. The dataset and code are available at: https://github.com/JZD151/Real-IISR.
Bridging Human Evaluation to Infrared and Visible Image Fusion
Mar 04, 2026Infrared and visible image fusion (IVIF) integrates complementary modalities to enhance scene perception. Current methods predominantly focus on optimizing handcrafted losses and objective metrics, often resulting in fusion outcomes that do not align with human visual preferences. This challenge is further exacerbated by the ill-posed nature of IVIF, which severely limits its effectiveness in human perceptual environments such as security surveillance and driver assistance systems. To address these limitations, we propose a feedback reinforcement framework that bridges human evaluation to infrared and visible image fusion. To address the lack of human-centric evaluation metrics and data, we introduce the first large-scale human feedback dataset for IVIF, containing multidimensional subjective scores and artifact annotations, and enriched by a fine-tuned large language model with expert review. Based on this dataset, we design a domain-specific reward function and train a reward model to quantify perceptual quality. Guided by this reward, we fine-tune the fusion network through Group Relative Policy Optimization, achieving state-of-the-art performance that better aligns fused images with human aesthetics. Code is available at https://github.com/ALKA-Wind/EVAFusion.
RSOD: Reliability-Guided Sonar Image Object Detection with Extremely Limited Labels
Jan 19, 2026Object detection in sonar images is a key technology in underwater detection systems. Compared to natural images, sonar images contain fewer texture details and are more susceptible to noise, making it difficult for non-experts to distinguish subtle differences between classes. This leads to their inability to provide precise annotation data for sonar images. Therefore, designing effective object detection methods for sonar images with extremely limited labels is particularly important. To address this, we propose a teacher-student framework called RSOD, which aims to fully learn the characteristics of sonar images and develop a pseudo-label strategy suitable for these images to mitigate the impact of limited labels. First, RSOD calculates a reliability score by assessing the consistency of the teacher's predictions across different views. To leverage this score, we introduce an object mixed pseudo-label method to tackle the shortage of labeled data in sonar images. Finally, we optimize the performance of the student by implementing a reliability-guided adaptive constraint. By taking full advantage of unlabeled data, the student can perform well even in situations with extremely limited labels. Notably, on the UATD dataset, our method, using only 5% of labeled data, achieves results that can compete against those of our baseline algorithm trained on 100% labeled data. We also collected a new dataset to provide more valuable data for research in the field of sonar.
HATIR: Heat-Aware Diffusion for Turbulent Infrared Video Super-Resolution
Jan 08, 2026Infrared video has been of great interest in visual tasks under challenging environments, but often suffers from severe atmospheric turbulence and compression degradation. Existing video super-resolution (VSR) methods either neglect the inherent modality gap between infrared and visible images or fail to restore turbulence-induced distortions. Directly cascading turbulence mitigation (TM) algorithms with VSR methods leads to error propagation and accumulation due to the decoupled modeling of degradation between turbulence and resolution. We introduce HATIR, a Heat-Aware Diffusion for Turbulent InfraRed Video Super-Resolution, which injects heat-aware deformation priors into the diffusion sampling path to jointly model the inverse process of turbulent degradation and structural detail loss. Specifically, HATIR constructs a Phasor-Guided Flow Estimator, rooted in the physical principle that thermally active regions exhibit consistent phasor responses over time, enabling reliable turbulence-aware flow to guide the reverse diffusion process. To ensure the fidelity of structural recovery under nonuniform distortions, a Turbulence-Aware Decoder is proposed to selectively suppress unstable temporal cues and enhance edge-aware feature aggregation via turbulence gating and structure-aware attention. We built FLIR-IVSR, the first dataset for turbulent infrared VSR, comprising paired LR-HR sequences from a FLIR T1050sc camera (1024 X 768) spanning 640 diverse scenes with varying camera and object motion conditions. This encourages future research in infrared VSR. Project page: https://github.com/JZ0606/HATIR
LongFly: Long-Horizon UAV Vision-and-Language Navigation with Spatiotemporal Context Integration
Dec 26, 2025Unmanned aerial vehicles (UAVs) are crucial tools for post-disaster search and rescue, facing challenges such as high information density, rapid changes in viewpoint, and dynamic structures, especially in long-horizon navigation. However, current UAV vision-and-language navigation(VLN) methods struggle to model long-horizon spatiotemporal context in complex environments, resulting in inaccurate semantic alignment and unstable path planning. To this end, we propose LongFly, a spatiotemporal context modeling framework for long-horizon UAV VLN. LongFly proposes a history-aware spatiotemporal modeling strategy that transforms fragmented and redundant historical data into structured, compact, and expressive representations. First, we propose the slot-based historical image compression module, which dynamically distills multi-view historical observations into fixed-length contextual representations. Then, the spatiotemporal trajectory encoding module is introduced to capture the temporal dynamics and spatial structure of UAV trajectories. Finally, to integrate existing spatiotemporal context with current observations, we design the prompt-guided multimodal integration module to support time-based reasoning and robust waypoint prediction. Experimental results demonstrate that LongFly outperforms state-of-the-art UAV VLN baselines by 7.89\% in success rate and 6.33\% in success weighted by path length, consistently across both seen and unseen environments.
FloorSAM: SAM-Guided Floorplan Reconstruction with Semantic-Geometric Fusion
Sep 19, 2025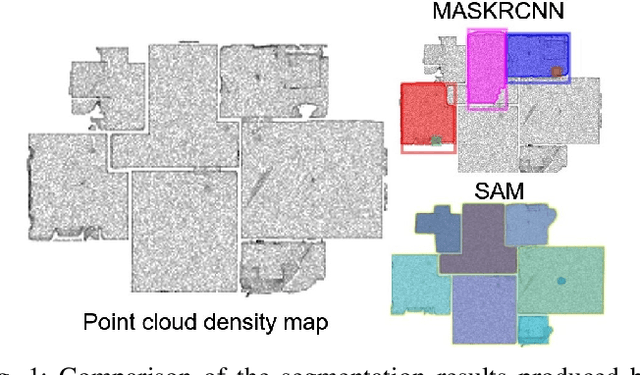

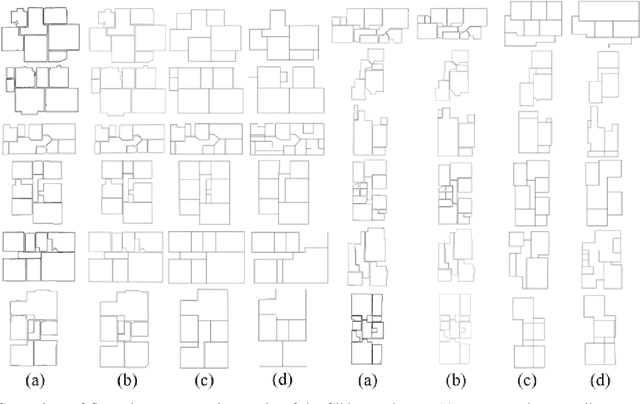
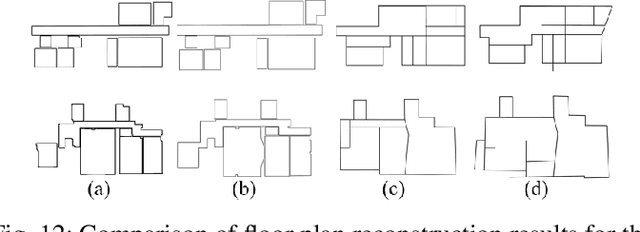
Reconstructing building floor plans from point cloud data is key for indoor navigation, BIM, and precise measurements. Traditional methods like geometric algorithms and Mask R-CNN-based deep learning often face issues with noise, limited generalization, and loss of geometric details. We propose FloorSAM, a framework that integrates point cloud density maps with the Segment Anything Model (SAM) for accurate floor plan reconstruction from LiDAR data. Using grid-based filtering, adaptive resolution projection, and image enhancement, we create robust top-down density maps. FloorSAM uses SAM's zero-shot learning for precise room segmentation, improving reconstruction across diverse layouts. Room masks are generated via adaptive prompt points and multistage filtering, followed by joint mask and point cloud analysis for contour extraction and regularization. This produces accurate floor plans and recovers room topological relationships. Tests on Giblayout and ISPRS datasets show better accuracy, recall, and robustness than traditional methods, especially in noisy and complex settings. Code and materials: github.com/Silentbarber/FloorSAM.
A Knowledge Noise Mitigation Framework for Knowledge-based Visual Question Answering
Sep 11, 2025
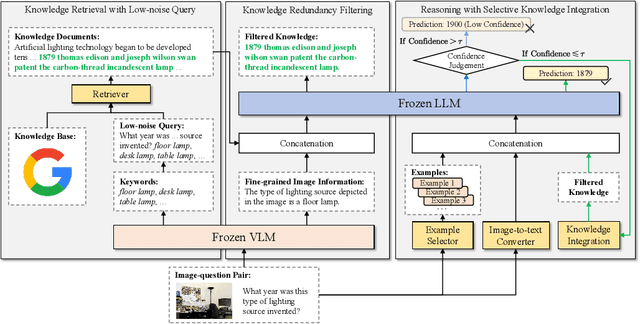
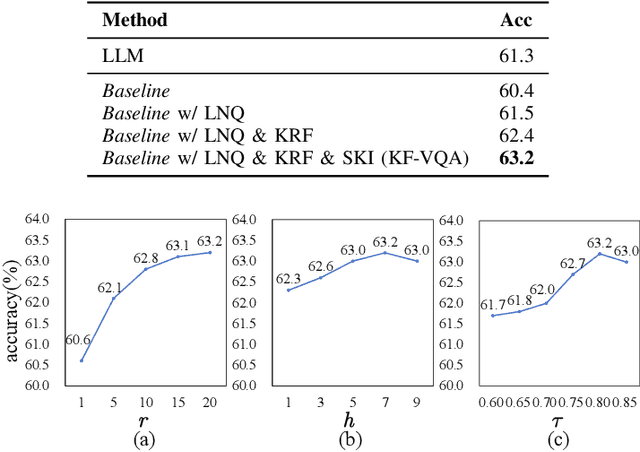

Knowledge-based visual question answering (KB-VQA) requires a model to understand images and utilize external knowledge to provide accurate answers. Existing approaches often directly augment models with retrieved information from knowledge sources while ignoring substantial knowledge redundancy, which introduces noise into the answering process. To address this, we propose a training-free framework with knowledge focusing for KB-VQA, that mitigates the impact of noise by enhancing knowledge relevance and reducing redundancy. First, for knowledge retrieval, our framework concludes essential parts from the image-question pairs, creating low-noise queries that enhance the retrieval of highly relevant knowledge. Considering that redundancy still persists in the retrieved knowledge, we then prompt large models to identify and extract answer-beneficial segments from knowledge. In addition, we introduce a selective knowledge integration strategy, allowing the model to incorporate knowledge only when it lacks confidence in answering the question, thereby mitigating the influence of redundant information. Our framework enables the acquisition of accurate and critical knowledge, and extensive experiments demonstrate that it outperforms state-of-the-art methods.