 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDifIISR: A Diffusion Model with Gradient Guidance for Infrared Image Super-Resolution
Mar 03, 2025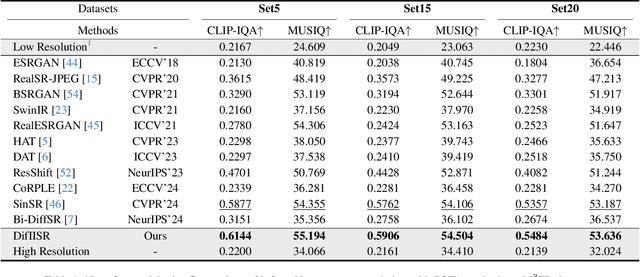
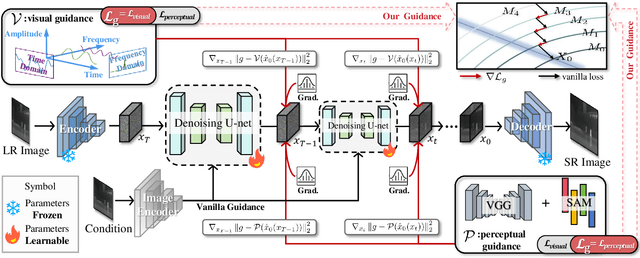


Infrared imaging is essential for autonomous driving and robotic operations as a supportive modality due to its reliable performance in challenging environments. Despite its popularity, the limitations of infrared cameras, such as low spatial resolution and complex degradations, consistently challenge imaging quality and subsequent visual tasks. Hence, infrared image super-resolution (IISR) has been developed to address this challenge. While recent developments in diffusion models have greatly advanced this field, current methods to solve it either ignore the unique modal characteristics of infrared imaging or overlook the machine perception requirements. To bridge these gaps, we propose DifIISR, an infrared image super-resolution diffusion model optimized for visual quality and perceptual performance. Our approach achieves task-based guidance for diffusion by injecting gradients derived from visual and perceptual priors into the noise during the reverse process. Specifically, we introduce an infrared thermal spectrum distribution regulation to preserve visual fidelity, ensuring that the reconstructed infrared images closely align with high-resolution images by matching their frequency components. Subsequently, we incorporate various visual foundational models as the perceptual guidance for downstream visual tasks, infusing generalizable perceptual features beneficial for detection and segmentation. As a result, our approach gains superior visual results while attaining State-Of-The-Art downstream task performance. Code is available at https://github.com/zirui0625/DifIISR
Contourlet Refinement Gate Framework for Thermal Spectrum Distribution Regularized Infrared Image Super-Resolution
Nov 19, 2024



Image super-resolution (SR) is a classical yet still active low-level vision problem that aims to reconstruct high-resolution (HR) images from their low-resolution (LR) counterparts, serving as a key technique for image enhancement. Current approaches to address SR tasks, such as transformer-based and diffusion-based methods, are either dedicated to extracting RGB image features or assuming similar degradation patterns, neglecting the inherent modal disparities between infrared and visible images. When directly applied to infrared image SR tasks, these methods inevitably distort the infrared spectral distribution, compromising the machine perception in downstream tasks. In this work, we emphasize the infrared spectral distribution fidelity and propose a Contourlet refinement gate framework to restore infrared modal-specific features while preserving spectral distribution fidelity. Our approach captures high-pass subbands from multi-scale and multi-directional infrared spectral decomposition to recover infrared-degraded information through a gate architecture. The proposed Spectral Fidelity Loss regularizes the spectral frequency distribution during reconstruction, which ensures the preservation of both high- and low-frequency components and maintains the fidelity of infrared-specific features. We propose a two-stage prompt-learning optimization to guide the model in learning infrared HR characteristics from LR degradation. Extensive experiments demonstrate that our approach outperforms existing image SR models in both visual and perceptual tasks while notably enhancing machine perception in downstream tasks. Our code is available at https://github.com/hey-it-s-me/CoRPLE.
Self-Imitation Learning in Sparse Reward Settings
Oct 30, 2020


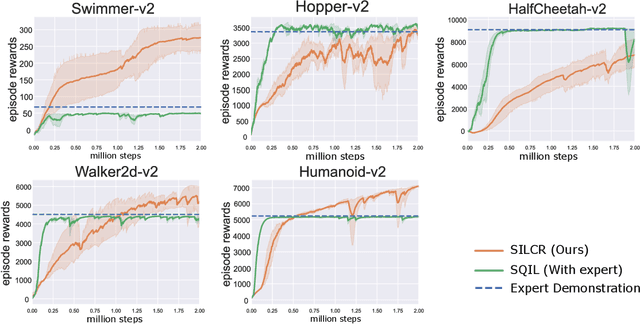
The application of reinforcement learning (RL) in real-world is still limited in the environments with sparse and delayed rewards. Self-imitation learning (SIL) is developed as an auxiliary component of RL to relieve the problem by encouraging the agents to imitate their historical best behaviors. In this paper, we propose a practical SIL algorithm named Self-Imitation Learning with Constant Reward (SILCR). Instead of requiring hand-defined immediate rewards from environments, our algorithm assigns the immediate rewards at each timestep with constant values according to their final episodic rewards. In this way, even if the dense rewards from environments are unavailable, every action taken by the agents would be guided properly. We demonstrate the effectiveness of our method in some challenging MuJoCo locomotion tasks and the results show that our method significantly outperforms the alternative methods in tasks with delayed and sparse rewards. Even compared with alternatives with dense rewards available, our method achieves competitive performance. The ablation experiments also show the stability and reproducibility of our method.
Towards Generalization and Data Efficient Learning of Deep Robotic Grasping
Jul 02, 2020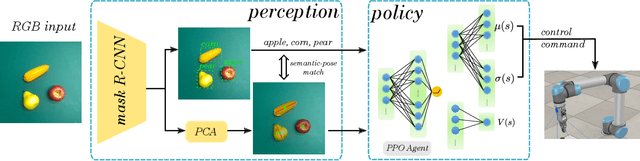


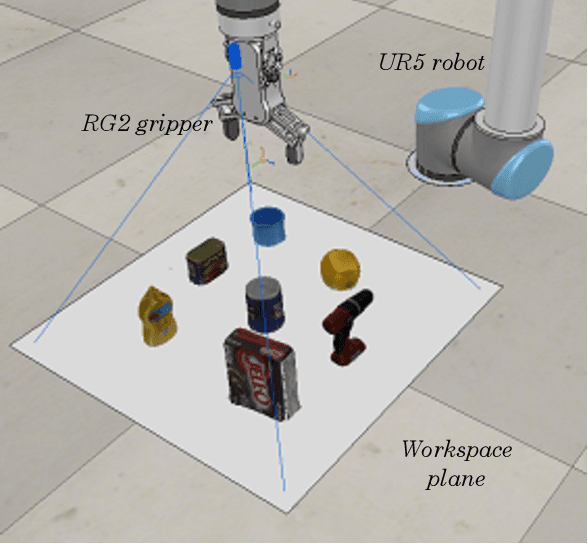
Deep reinforcement learning (DRL) has been proven to be a powerful paradigm for learning complex control policy autonomously. Numerous recent applications of DRL in robotic grasping have successfully trained DRL robotic agents end-to-end, mapping visual inputs into control instructions directly, but the amount of training data required may hinder these applications in practice. In this paper, we propose a DRL based robotic visual grasping framework, in which visual perception and control policy are trained separately rather than end-to-end. The visual perception produces physical descriptions of grasped objects and the policy takes use of them to decide optimal actions based on DRL. Benefiting from the explicit representation of objects, the policy is expected to be endowed with more generalization power over new objects and environments. In addition, the policy can be trained in simulation and transferred in real robotic system without any further training. We evaluate our framework in a real world robotic system on a number of robotic grasping tasks, such as semantic grasping, clustered object grasping, moving object grasping. The results show impressive robustness and generalization of our system.
Vision-based Robot Manipulation Learning via Human Demonstrations
Mar 01, 2020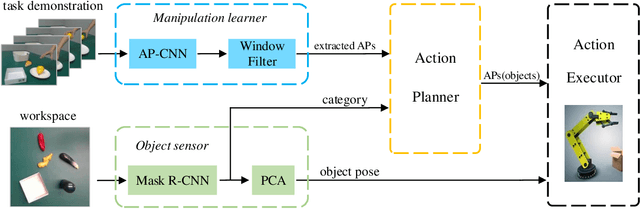
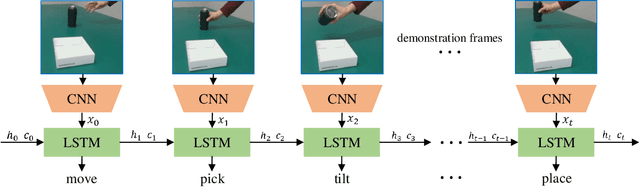
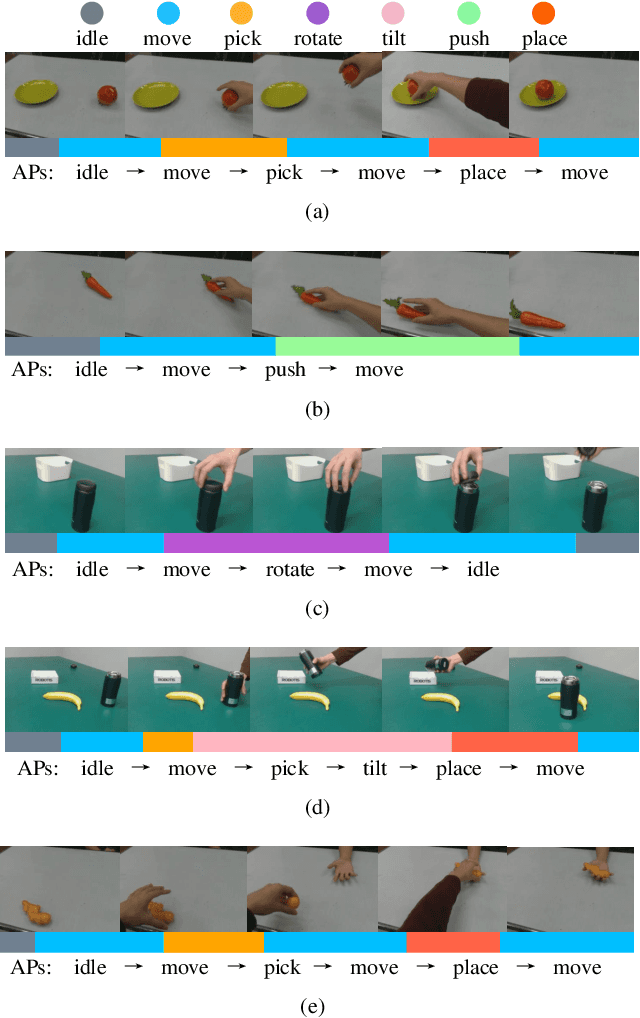

Vision-based learning methods provide promise for robots to learn complex manipulation tasks. However, how to generalize the learned manipulation skills to real-world interactions remains an open question. In this work, we study robotic manipulation skill learning from a single third-person view demonstration by using activity recognition and object detection in computer vision. To facilitate generalization across objects and environments, we propose to use a prior knowledge base in the form of a text corpus to infer the object to be interacted with in the context of a robot. We evaluate our approach in a real-world robot, using several simple and complex manipulation tasks commonly performed in daily life. The experimental results show that our approach achieves good generalization performance even from small amounts of training data.