 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Generalization and Data Efficient Learning of Deep Robotic Grasping
Jul 02, 2020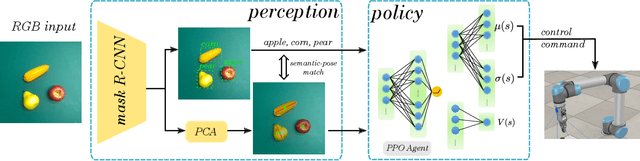


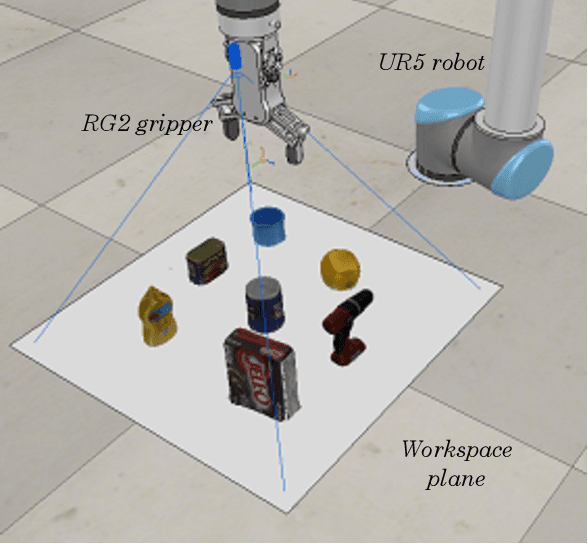
Deep reinforcement learning (DRL) has been proven to be a powerful paradigm for learning complex control policy autonomously. Numerous recent applications of DRL in robotic grasping have successfully trained DRL robotic agents end-to-end, mapping visual inputs into control instructions directly, but the amount of training data required may hinder these applications in practice. In this paper, we propose a DRL based robotic visual grasping framework, in which visual perception and control policy are trained separately rather than end-to-end. The visual perception produces physical descriptions of grasped objects and the policy takes use of them to decide optimal actions based on DRL. Benefiting from the explicit representation of objects, the policy is expected to be endowed with more generalization power over new objects and environments. In addition, the policy can be trained in simulation and transferred in real robotic system without any further training. We evaluate our framework in a real world robotic system on a number of robotic grasping tasks, such as semantic grasping, clustered object grasping, moving object grasping. The results show impressive robustness and generalization of our system.
Vision-based Robot Manipulation Learning via Human Demonstrations
Mar 01, 2020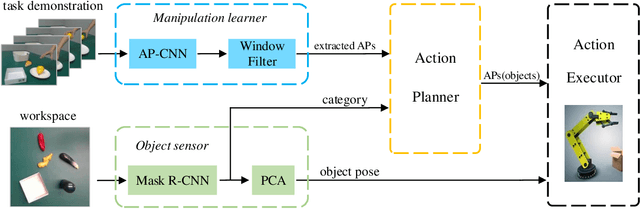
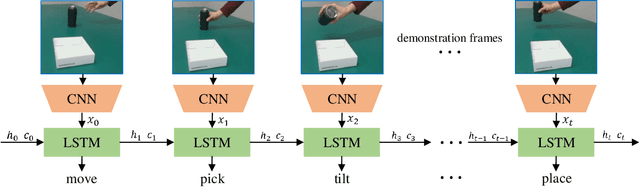
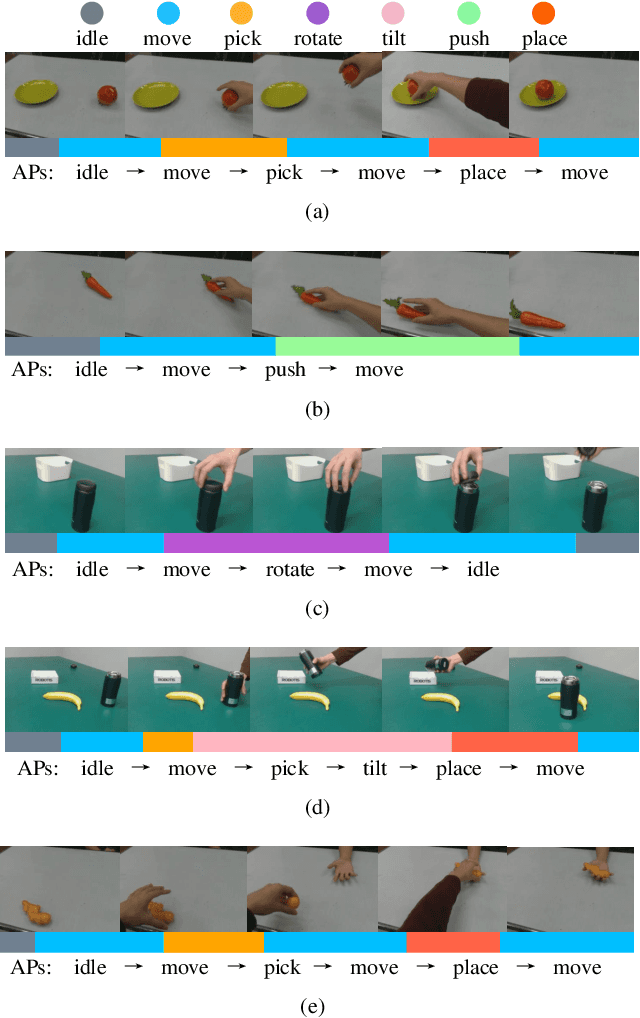

Vision-based learning methods provide promise for robots to learn complex manipulation tasks. However, how to generalize the learned manipulation skills to real-world interactions remains an open question. In this work, we study robotic manipulation skill learning from a single third-person view demonstration by using activity recognition and object detection in computer vision. To facilitate generalization across objects and environments, we propose to use a prior knowledge base in the form of a text corpus to infer the object to be interacted with in the context of a robot. We evaluate our approach in a real-world robot, using several simple and complex manipulation tasks commonly performed in daily life. The experimental results show that our approach achieves good generalization performance even from small amounts of training data.