 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3D Interacting Hand Pose Estimation by Hand De-occlusion and Removal
Jul 22, 2022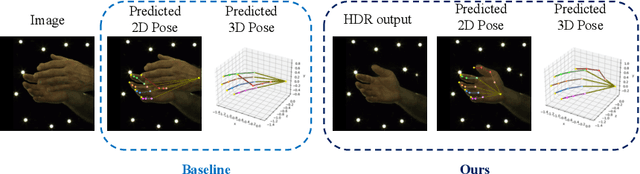
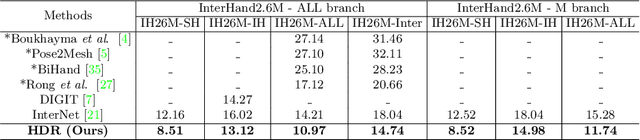
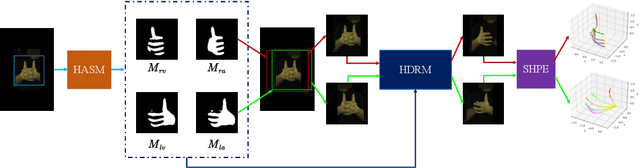
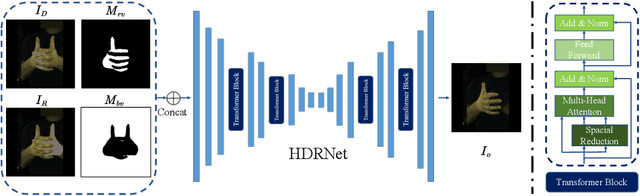
Estimating 3D interacting hand pose from a single RGB image is essential for understanding human actions. Unlike most previous works that directly predict the 3D poses of two interacting hands simultaneously, we propose to decompose the challenging interacting hand pose estimation task and estimate the pose of each hand separately. In this way, it is straightforward to take advantage of the latest research progress on the single-hand pose estimation system. However, hand pose estimation in interacting scenarios is very challenging, due to (1) severe hand-hand occlusion and (2) ambiguity caused by the homogeneous appearance of hands. To tackle these two challenges, we propose a novel Hand De-occlusion and Removal (HDR) framework to perform hand de-occlusion and distractor removal. We also propose the first large-scale synthetic amodal hand dataset, termed Amodal InterHand Dataset (AIH), to facilitate model training and promote the development of the related research. Experiments show that the proposed method significantly outperforms previous state-of-the-art interacting hand pose estimation approaches. Codes and data are available at https://github.com/MengHao666/HDR.
Self-Imitation Learning in Sparse Reward Settings
Oct 30, 2020


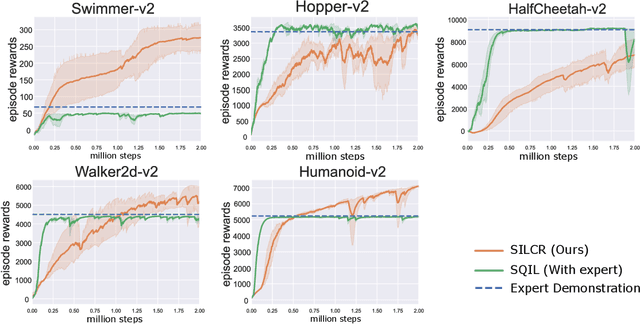
The application of reinforcement learning (RL) in real-world is still limited in the environments with sparse and delayed rewards. Self-imitation learning (SIL) is developed as an auxiliary component of RL to relieve the problem by encouraging the agents to imitate their historical best behaviors. In this paper, we propose a practical SIL algorithm named Self-Imitation Learning with Constant Reward (SILCR). Instead of requiring hand-defined immediate rewards from environments, our algorithm assigns the immediate rewards at each timestep with constant values according to their final episodic rewards. In this way, even if the dense rewards from environments are unavailable, every action taken by the agents would be guided properly. We demonstrate the effectiveness of our method in some challenging MuJoCo locomotion tasks and the results show that our method significantly outperforms the alternative methods in tasks with delayed and sparse rewards. Even compared with alternatives with dense rewards available, our method achieves competitive performance. The ablation experiments also show the stability and reproducibility of our method.
Towards Generalization and Data Efficient Learning of Deep Robotic Grasping
Jul 02, 2020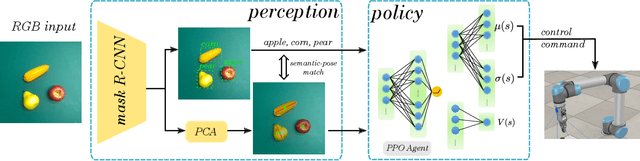


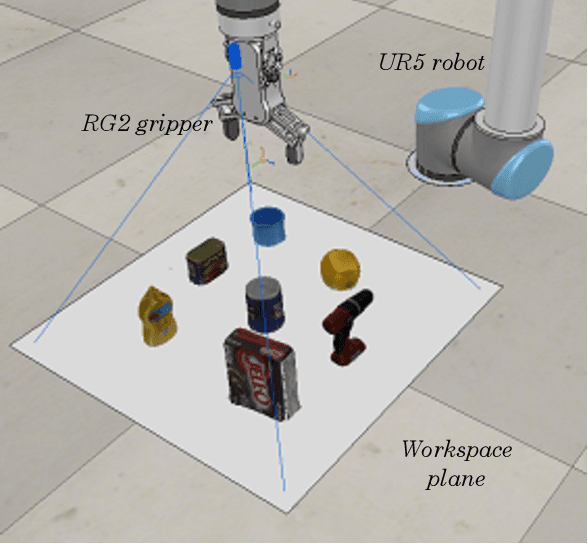
Deep reinforcement learning (DRL) has been proven to be a powerful paradigm for learning complex control policy autonomously. Numerous recent applications of DRL in robotic grasping have successfully trained DRL robotic agents end-to-end, mapping visual inputs into control instructions directly, but the amount of training data required may hinder these applications in practice. In this paper, we propose a DRL based robotic visual grasping framework, in which visual perception and control policy are trained separately rather than end-to-end. The visual perception produces physical descriptions of grasped objects and the policy takes use of them to decide optimal actions based on DRL. Benefiting from the explicit representation of objects, the policy is expected to be endowed with more generalization power over new objects and environments. In addition, the policy can be trained in simulation and transferred in real robotic system without any further training. We evaluate our framework in a real world robotic system on a number of robotic grasping tasks, such as semantic grasping, clustered object grasping, moving object grasping. The results show impressive robustness and generalization of our system.
Vision-based Robot Manipulation Learning via Human Demonstrations
Mar 01, 2020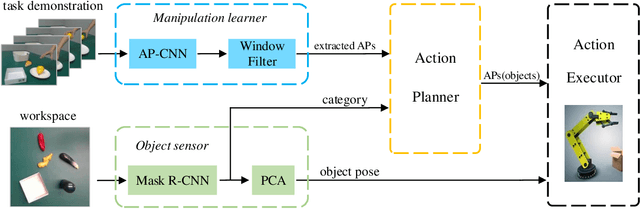
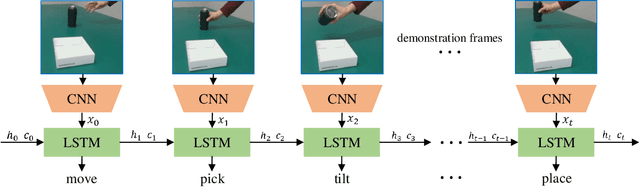
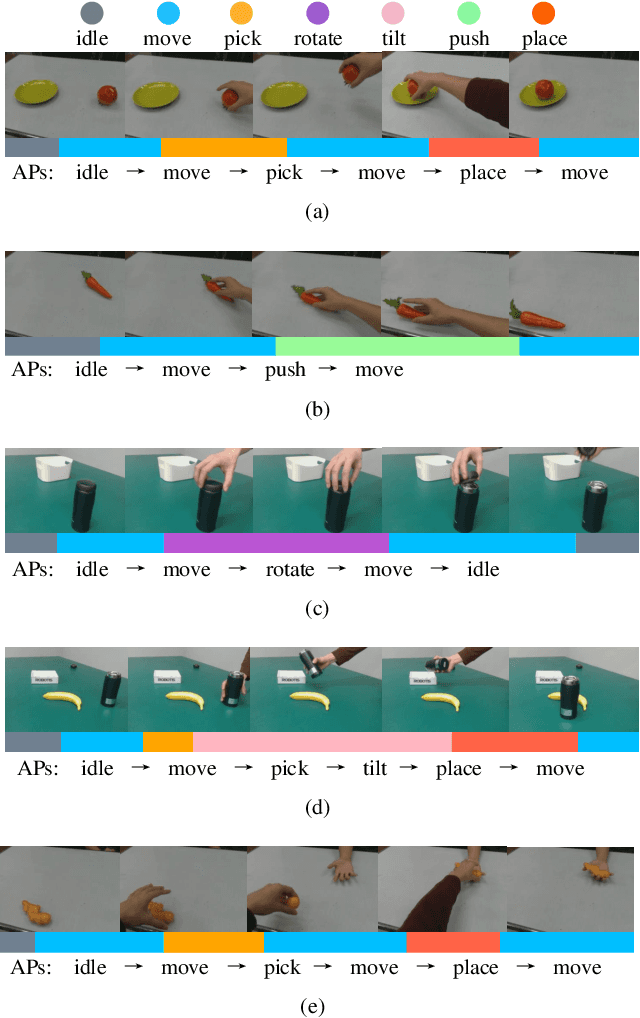

Vision-based learning methods provide promise for robots to learn complex manipulation tasks. However, how to generalize the learned manipulation skills to real-world interactions remains an open question. In this work, we study robotic manipulation skill learning from a single third-person view demonstration by using activity recognition and object detection in computer vision. To facilitate generalization across objects and environments, we propose to use a prior knowledge base in the form of a text corpus to infer the object to be interacted with in the context of a robot. We evaluate our approach in a real-world robot, using several simple and complex manipulation tasks commonly performed in daily life. The experimental results show that our approach achieves good generalization performance even from small amounts of training data.
A Collaborative Aerial-Ground Robotic System for Fast Exploration
Jun 07, 2018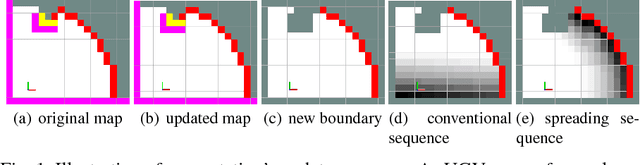
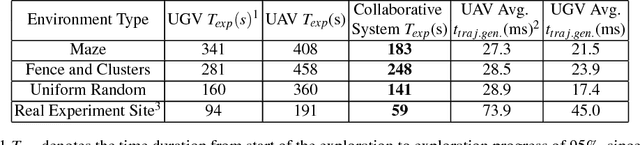


Autonomous exploration of unknown environments has been widely applied in inspection, surveillance, and search and rescue. In exploration task, the basic requirement for robots is to detect the unknown space as fast as possible. In this paper, we propose an autonomous collaborative system consists of an aerial robot and a ground vehicle to explore in unknown environments. We combine the frontier based method and the harmonic field to generate a path. Then, For the ground robot, a minimum jerk piecewise Bezier curve which can guarantee safety and dynamical feasibility is generated amid obstacles. For the aerial robot, a motion primitive method is adopted for local path planning. We implement the proposed framework on an autonomous collaborative aerial-ground system. Extensive field experiments as well as simulations are presented to validate the method and demonstrate its higher efficiency against each single vehicle.