 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTIGFlow-GRPO: Trajectory Forecasting via Interaction-Aware Flow Matching and Reward-Driven Optimization
Mar 26, 2026Human trajectory forecasting is important for intelligent multimedia systems operating in visually complex environments, such as autonomous driving and crowd surveillance. Although Conditional Flow Matching (CFM) has shown strong ability in modeling trajectory distributions from spatio-temporal observations, existing approaches still focus primarily on supervised fitting, which may leave social norms and scene constraints insufficiently reflected in generated trajectories. To address this issue, we propose TIGFlow-GRPO, a two-stage generative framework that aligns flow-based trajectory generation with behavioral rules. In the first stage, we build a CFM-based predictor with a Trajectory-Interaction-Graph (TIG) module to model fine-grained visual-spatial interactions and strengthen context encoding. This stage captures both agent-agent and agent-scene relations more effectively, providing more informative conditional features for subsequent alignment. In the second stage, we perform Flow-GRPO post-training,where deterministic flow rollout is reformulated as stochastic ODE-to-SDE sampling to enable trajectory exploration, and a composite reward combines view-aware social compliance with map-aware physical feasibility. By evaluating trajectories explored through SDE rollout, GRPO progressively steers multimodal predictions toward behaviorally plausible futures. Experiments on the ETH/UCY and SDD datasets show that TIGFlow-GRPO improves forecasting accuracy and long-horizon stability while generating trajectories that are more socially compliant and physically feasible. These results suggest that the proposed framework provides an effective way to connect flow-based trajectory modeling with behavior-aware alignment in dynamic multimedia environments.
SoulX-Duplug: Plug-and-Play Streaming State Prediction Module for Realtime Full-Duplex Speech Conversation
Mar 16, 2026Recent advances in spoken dialogue systems have brought increased attention to human-like full-duplex voice interactions. However, our comprehensive review of this field reveals several challenges, including the difficulty in obtaining training data, catastrophic forgetting, and limited scalability. In this work, we propose SoulX-Duplug, a plug-and-play streaming state prediction module for full-duplex spoken dialogue systems. By jointly performing streaming ASR, SoulX-Duplug explicitly leverages textual information to identify user intent, effectively serving as a semantic VAD. To promote fair evaluation, we introduce SoulX-Duplug-Eval, extending widely used benchmarks with improved bilingual coverage. Experimental results show that SoulX-Duplug enables low-latency streaming dialogue state control, and the system built upon it outperforms existing full-duplex models in overall turn management and latency performance. We have open-sourced SoulX-Duplug and SoulX-Duplug-Eval.
SoulX-Singer: Towards High-Quality Zero-Shot Singing Voice Synthesis
Feb 08, 2026While recent years have witnessed rapid progress in speech synthesis, open-source singing voice synthesis (SVS) systems still face significant barriers to industrial deployment, particularly in terms of robustness and zero-shot generalization. In this report, we introduce SoulX-Singer, a high-quality open-source SVS system designed with practical deployment considerations in mind. SoulX-Singer supports controllable singing generation conditioned on either symbolic musical scores (MIDI) or melodic representations, enabling flexible and expressive control in real-world production workflows. Trained on more than 42,000 hours of vocal data, the system supports Mandarin Chinese, English, and Cantonese and consistently achieves state-of-the-art synthesis quality across languages under diverse musical conditions. Furthermore, to enable reliable evaluation of zero-shot SVS performance in practical scenarios, we construct SoulX-Singer-Eval, a dedicated benchmark with strict training-test disentanglement, facilitating systematic assessment in zero-shot settings.
Video Deblurring by Sharpness Prior Detection and Edge Information
Jan 21, 2025Video deblurring is essential task for autonomous driving, facial recognition, and security surveillance. Traditional methods directly estimate motion blur kernels, often introducing artifacts and leading to poor results. Recent approaches utilize the detection of sharp frames within video sequences to enhance deblurring. However, existing datasets rely on fixed number of sharp frames, which may be too restrictive for some applications and may introduce a bias during model training. To address these limitations and enhance domain adaptability, this work first introduces GoPro Random Sharp (GoProRS), a new dataset where the the frequency of sharp frames within the sequence is customizable, allowing more diverse training and testing scenarios. Furthermore, it presents a novel video deblurring model, called SPEINet, that integrates sharp frame features into blurry frame reconstruction through an attention-based encoder-decoder architecture, a lightweight yet robust sharp frame detection and an edge extraction phase. Extensive experimental results demonstrate that SPEINet outperforms state-of-the-art methods across multiple datasets, achieving an average of +3.2% PSNR improvement over recent techniques. Given such promising results, we believe that both the proposed model and dataset pave the way for future advancements in video deblurring based on the detection of sharp frames.
3D Interacting Hand Pose Estimation by Hand De-occlusion and Removal
Jul 22, 2022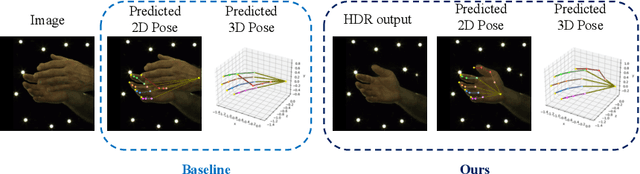
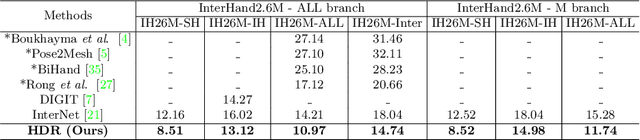
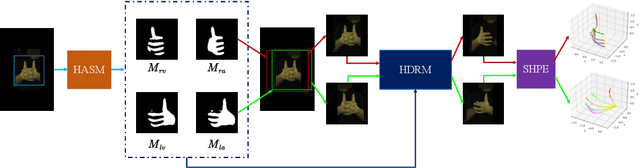
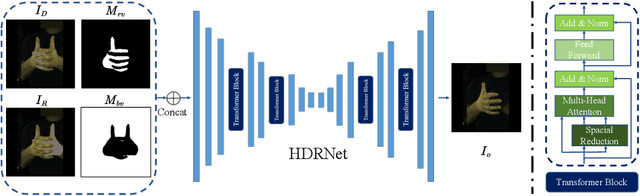
Estimating 3D interacting hand pose from a single RGB image is essential for understanding human actions. Unlike most previous works that directly predict the 3D poses of two interacting hands simultaneously, we propose to decompose the challenging interacting hand pose estimation task and estimate the pose of each hand separately. In this way, it is straightforward to take advantage of the latest research progress on the single-hand pose estimation system. However, hand pose estimation in interacting scenarios is very challenging, due to (1) severe hand-hand occlusion and (2) ambiguity caused by the homogeneous appearance of hands. To tackle these two challenges, we propose a novel Hand De-occlusion and Removal (HDR) framework to perform hand de-occlusion and distractor removal. We also propose the first large-scale synthetic amodal hand dataset, termed Amodal InterHand Dataset (AIH), to facilitate model training and promote the development of the related research. Experiments show that the proposed method significantly outperforms previous state-of-the-art interacting hand pose estimation approaches. Codes and data are available at https://github.com/MengHao666/HDR.