 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePairedGTA: Generating Driving Datasets for Controlled Photometric Shift Analysis
May 31, 2026Evaluating the performance of visual perception systems for autonomous driving is essential to ensure reliable operation across diverse environmental scenarios. Ideally, a balanced and fair analysis across different adverse conditions would require perfectly paired images of the same scene under different weather or illumination changes. This would allow evaluating the effect of photometric shifts independently of geometry and semantic changes. Unfortunately, real-world datasets rarely provide images of the same scene under different environmental conditions, because, normally, camera pose, traffic, and locations of dynamic objects (vehicles, pedestrians, etc.) vary over time, thus yielding only coarsely paired data. To address this challenge, this work introduces a data generation framework based on a high-fidelity game engine for extracting perfectly paired images. By leveraging software APIs that communicate with the GTA game engine, the framework modifies illumination and weather conditions while preserving scene geometry, camera pose, and the identity and placement of dynamic objects. For each sampled location, it procedurally instantiates dynamic entities and renders pixel-aligned images under diverse adverse conditions. The benefit of the proposed generation framework in driving scenarios is demonstrated through a systematic analysis of semantic segmentation models, whose output degradation can be attributed more directly to photometric shifts rather than to uncontrolled semantic or geometric factors.
Learning Robustness at Test-Time from a Non-Robust Teacher
Apr 13, 2026Nowadays, pretrained models are increasingly used as general-purpose backbones and adapted at test-time to downstream environments where target data are scarce and unlabeled. While this paradigm has proven effective for improving clean accuracy on the target domain, adversarial robustness has received far less attention, especially when the original pretrained model is not explicitly designed to be robust. This raises a practical question: \emph{can a pretrained, non-robust model be adapted at test-time to improve adversarial robustness on a target distribution?} To face this question, this work studies how adversarial training strategies behave when integrated into adaptation schemes for the unsupervised test-time setting, where only a small set of unlabeled target samples is available. It first analyzes how classical adversarial training formulations can be extended to this scenario, showing that straightforward distillation-based adaptations remain unstable and highly sensitive to hyperparameter tuning, particularly when the teacher itself is non-robust. To address these limitations, the work proposes a label-free framework that uses the predictions of a non-robust teacher model as a semantic anchor for both the clean and adversarial objectives during adaptation. We further provide theoretical insights showing that our formulation yields a more stable alternative to the self-consistency-based regularization commonly used in classical adversarial training. Experiments evaluate the proposed approach on CIFAR-10 and ImageNet under induced photometric transformations. The results support the theoretical insights by showing that the proposed approach achieves improved optimization stability, lower sensitivity to parameter choices, and a better robustness-accuracy trade-off than existing baselines in this post-deployment test-time setting.
How Worst-Case Are Adversarial Attacks? Linking Adversarial and Statistical Robustness
Jan 20, 2026Adversarial attacks are widely used to evaluate model robustness, yet their validity as proxies for robustness to random perturbations remains debated. We ask whether an adversarial perturbation provides a representative estimate of robustness under random noise of the same magnitude, or instead reflects an atypical worst-case event. To this end, we introduce a probabilistic metric that quantifies noisy risk with respect to directionally biased perturbation distributions, parameterized by a concentration factor $κ$ that interpolates between isotropic noise and adversarial direction. Using this framework, we study the limits of adversarial perturbations as estimators of noisy risk by proposing an attack strategy designed to operate in regimes statistically closer to uniform noise. Experiments on ImageNet and CIFAR-10 systematically benchmark widely used attacks, highlighting when adversarial success meaningfully reflects noisy risk and when it fails, thereby informing their use in safety-oriented evaluation.
On the Hidden Objective Biases of Group-based Reinforcement Learning
Jan 08, 2026Group-based reinforcement learning methods, like Group Relative Policy Optimization (GRPO), are widely used nowadays to post-train large language models. Despite their empirical success, they exhibit structural mismatches between reward optimization and the underlying training objective. In this paper, we present a theoretical analysis of GRPO style methods by studying them within a unified surrogate formulation. This perspective reveals recurring properties that affect all the methods under analysis: (i) non-uniform group weighting induces systematic gradient biases on shared prefix tokens; (ii) interactions with the AdamW optimizer make training dynamics largely insensitive to reward scaling; and (iii) optimizer momentum can push policy updates beyond the intended clipping region under repeated optimization steps. We believe that these findings highlight fundamental limitations of current approaches and provide principled guidance for the design of future formulations.
KGQuest: Template-Driven QA Generation from Knowledge Graphs with LLM-Based Refinement
Nov 14, 2025



The generation of questions and answers (QA) from knowledge graphs (KG) plays a crucial role in the development and testing of educational platforms, dissemination tools, and large language models (LLM). However, existing approaches often struggle with scalability, linguistic quality, and factual consistency. This paper presents a scalable and deterministic pipeline for generating natural language QA from KGs, with an additional refinement step using LLMs to further enhance linguistic quality. The approach first clusters KG triplets based on their relations, creating reusable templates through natural language rules derived from the entity types of objects and relations. A module then leverages LLMs to refine these templates, improving clarity and coherence while preserving factual accuracy. Finally, the instantiation of answer options is achieved through a selection strategy that introduces distractors from the KG. Our experiments demonstrate that this hybrid approach efficiently generates high-quality QA pairs, combining scalability with fluency and linguistic precision.
Exploiting Edge Features for Transferable Adversarial Attacks in Distributed Machine Learning
Jul 09, 2025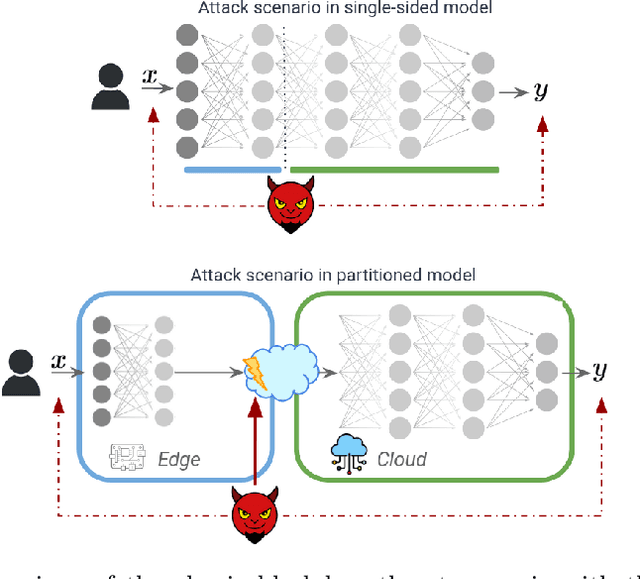
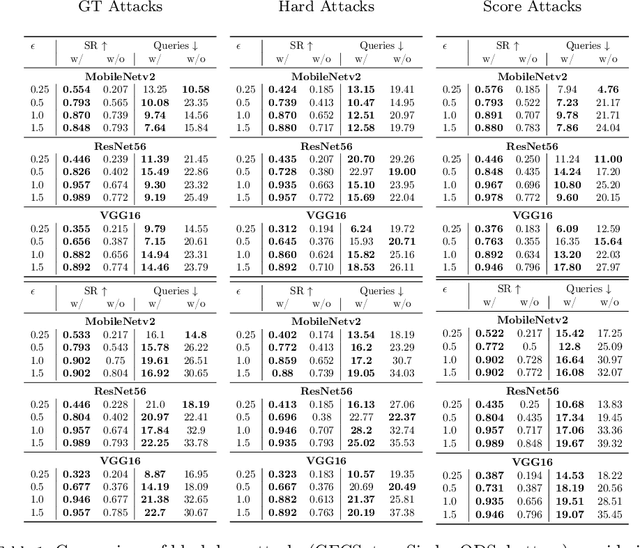
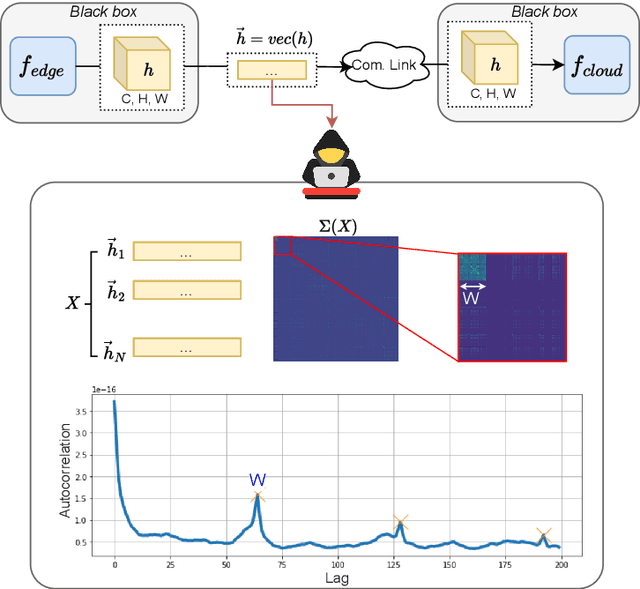
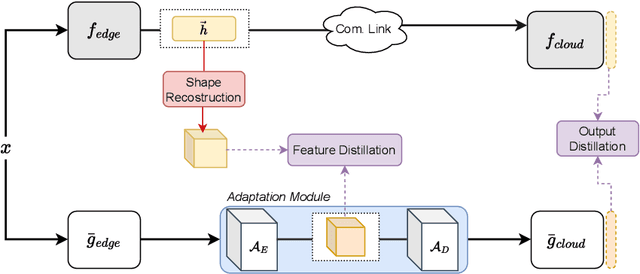
As machine learning models become increasingly deployed across the edge of internet of things environments, a partitioned deep learning paradigm in which models are split across multiple computational nodes introduces a new dimension of security risk. Unlike traditional inference setups, these distributed pipelines span the model computation across heterogeneous nodes and communication layers, thereby exposing a broader attack surface to potential adversaries. Building on these motivations, this work explores a previously overlooked vulnerability: even when both the edge and cloud components of the model are inaccessible (i.e., black-box), an adversary who intercepts the intermediate features transmitted between them can still pose a serious threat. We demonstrate that, under these mild and realistic assumptions, an attacker can craft highly transferable proxy models, making the entire deep learning system significantly more vulnerable to evasion attacks. In particular, the intercepted features can be effectively analyzed and leveraged to distill surrogate models capable of crafting highly transferable adversarial examples against the target model. To this end, we propose an exploitation strategy specifically designed for distributed settings, which involves reconstructing the original tensor shape from vectorized transmitted features using simple statistical analysis, and adapting surrogate architectures accordingly to enable effective feature distillation. A comprehensive and systematic experimental evaluation has been conducted to demonstrate that surrogate models trained with the proposed strategy, i.e., leveraging intermediate features, tremendously improve the transferability of adversarial attacks. These findings underscore the urgent need to account for intermediate feature leakage in the design of secure distributed deep learning systems.
Leveraging Knowledge Graphs and LLMs for Structured Generation of Misinformation
May 30, 2025The rapid spread of misinformation, further amplified by recent advances in generative AI, poses significant threats to society, impacting public opinion, democratic stability, and national security. Understanding and proactively assessing these threats requires exploring methodologies that enable structured and scalable misinformation generation. In this paper, we propose a novel approach that leverages knowledge graphs (KGs) as structured semantic resources to systematically generate fake triplets. By analyzing the structural properties of KGs, such as the distance between entities and their predicates, we identify plausibly false relationships. These triplets are then used to guide large language models (LLMs) in generating misinformation statements with varying degrees of credibility. By utilizing structured semantic relationships, our deterministic approach produces misinformation inherently challenging for humans to detect, drawing exclusively upon publicly available KGs (e.g., WikiGraphs). Additionally, we investigate the effectiveness of LLMs in distinguishing between genuine and artificially generated misinformation. Our analysis highlights significant limitations in current LLM-based detection methods, underscoring the necessity for enhanced detection strategies and a deeper exploration of inherent biases in generative models.
Benchmarking the Spatial Robustness of DNNs via Natural and Adversarial Localized Corruptions
Apr 02, 2025
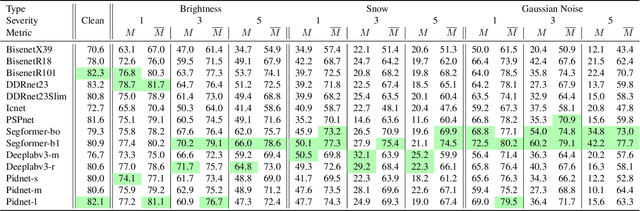
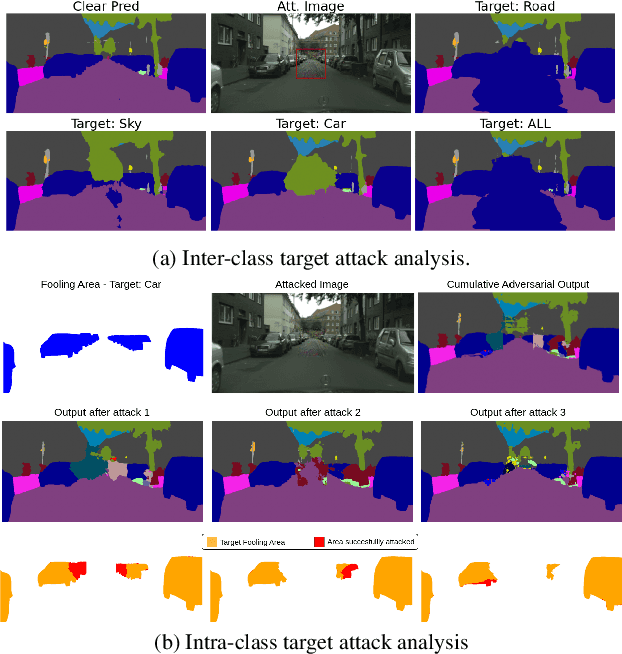

The robustness of DNNs is a crucial factor in safety-critical applications, particularly in complex and dynamic environments where localized corruptions can arise. While previous studies have evaluated the robustness of semantic segmentation (SS) models under whole-image natural or adversarial corruptions, a comprehensive investigation into the spatial robustness of dense vision models under localized corruptions remained underexplored. This paper fills this gap by introducing specialized metrics for benchmarking the spatial robustness of segmentation models, alongside with an evaluation framework to assess the impact of localized corruptions. Furthermore, we uncover the inherent complexity of characterizing worst-case robustness using a single localized adversarial perturbation. To address this, we propose region-aware multi-attack adversarial analysis, a method that enables a deeper understanding of model robustness against adversarial perturbations applied to specific regions. The proposed metrics and analysis were evaluated on 15 segmentation models in driving scenarios, uncovering key insights into the effects of localized corruption in both natural and adversarial forms. The results reveal that models respond to these two types of threats differently; for instance, transformer-based segmentation models demonstrate notable robustness to localized natural corruptions but are highly vulnerable to adversarial ones and vice-versa for CNN-based models. Consequently, we also address the challenge of balancing robustness to both natural and adversarial localized corruptions by means of ensemble models, thereby achieving a broader threat coverage and improved reliability for dense vision tasks.
Video Deblurring by Sharpness Prior Detection and Edge Information
Jan 21, 2025Video deblurring is essential task for autonomous driving, facial recognition, and security surveillance. Traditional methods directly estimate motion blur kernels, often introducing artifacts and leading to poor results. Recent approaches utilize the detection of sharp frames within video sequences to enhance deblurring. However, existing datasets rely on fixed number of sharp frames, which may be too restrictive for some applications and may introduce a bias during model training. To address these limitations and enhance domain adaptability, this work first introduces GoPro Random Sharp (GoProRS), a new dataset where the the frequency of sharp frames within the sequence is customizable, allowing more diverse training and testing scenarios. Furthermore, it presents a novel video deblurring model, called SPEINet, that integrates sharp frame features into blurry frame reconstruction through an attention-based encoder-decoder architecture, a lightweight yet robust sharp frame detection and an edge extraction phase. Extensive experimental results demonstrate that SPEINet outperforms state-of-the-art methods across multiple datasets, achieving an average of +3.2% PSNR improvement over recent techniques. Given such promising results, we believe that both the proposed model and dataset pave the way for future advancements in video deblurring based on the detection of sharp frames.
Edge-Only Universal Adversarial Attacks in Distributed Learning
Nov 15, 2024



Distributed learning frameworks, which partition neural network models across multiple computing nodes, enhance efficiency in collaborative edge-cloud systems but may also introduce new vulnerabilities. In this work, we explore the feasibility of generating universal adversarial attacks when an attacker has access to the edge part of the model only, which consists in the first network layers. Unlike traditional universal adversarial perturbations (UAPs) that require full model knowledge, our approach shows that adversaries can induce effective mispredictions in the unknown cloud part by leveraging key features on the edge side. Specifically, we train lightweight classifiers from intermediate features available at the edge, i.e., before the split point, and use them in a novel targeted optimization to craft effective UAPs. Our results on ImageNet demonstrate strong attack transferability to the unknown cloud part. Additionally, we analyze the capability of an attacker to achieve targeted adversarial effect with edge-only knowledge, revealing intriguing behaviors. By introducing the first adversarial attacks with edge-only knowledge in split inference, this work underscores the importance of addressing partial model access in adversarial robustness, encouraging further research in this area.