 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOSDaR-AR: Enhancing Railway Perception Datasets via Multi-modal Augmented Reality
Feb 26, 2026Although deep learning has significantly advanced the perception capabilities of intelligent transportation systems, railway applications continue to suffer from a scarcity of high-quality, annotated data for safety-critical tasks like obstacle detection. While photorealistic simulators offer a solution, they often struggle with the ``sim-to-real" gap; conversely, simple image-masking techniques lack the spatio-temporal coherence required to obtain augmented single- and multi-frame scenes with the correct appearance and dimensions. This paper introduces a multi-modal augmented reality framework designed to bridge this gap by integrating photorealistic virtual objects into real-world railway sequences from the OSDaR23 dataset. Utilizing Unreal Engine 5 features, our pipeline leverages LiDAR point-clouds and INS/GNSS data to ensure accurate object placement and temporal stability across RGB frames. This paper also proposes a segmentation-based refinement strategy for INS/GNSS data to significantly improve the realism of the augmented sequences, as confirmed by the comparative study presented in the paper. Carefully designed augmented sequences are collected to produce OSDaR-AR, a public dataset designed to support the development of next-generation railway perception systems. The dataset is available at the following page: https://syndra.retis.santannapisa.it/osdarar.html
Towards Railway Domain Adaptation for LiDAR-based 3D Detection: Road-to-Rail and Sim-to-Real via SynDRA-BBox
Jul 22, 2025In recent years, interest in automatic train operations has significantly increased. To enable advanced functionalities, robust vision-based algorithms are essential for perceiving and understanding the surrounding environment. However, the railway sector suffers from a lack of publicly available real-world annotated datasets, making it challenging to test and validate new perception solutions in this domain. To address this gap, we introduce SynDRA-BBox, a synthetic dataset designed to support object detection and other vision-based tasks in realistic railway scenarios. To the best of our knowledge, is the first synthetic dataset specifically tailored for 2D and 3D object detection in the railway domain, the dataset is publicly available at https://syndra.retis.santannapisa.it. In the presented evaluation, a state-of-the-art semi-supervised domain adaptation method, originally developed for automotive perception, is adapted to the railway context, enabling the transferability of synthetic data to 3D object detection. Experimental results demonstrate promising performance, highlighting the effectiveness of synthetic datasets and domain adaptation techniques in advancing perception capabilities for railway environments.
SimPRIVE: a Simulation framework for Physical Robot Interaction with Virtual Environments
Apr 30, 2025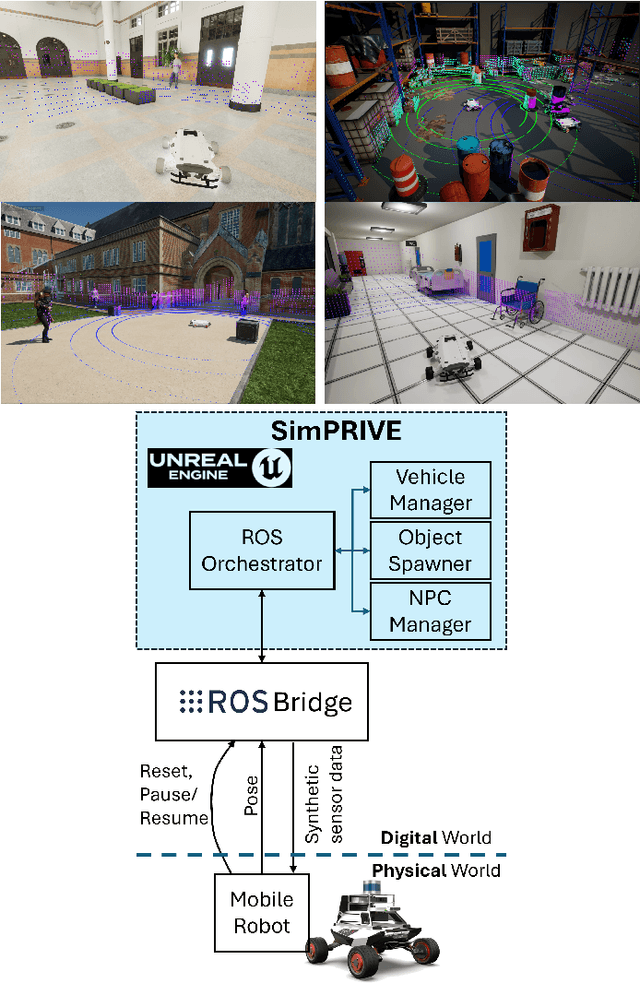
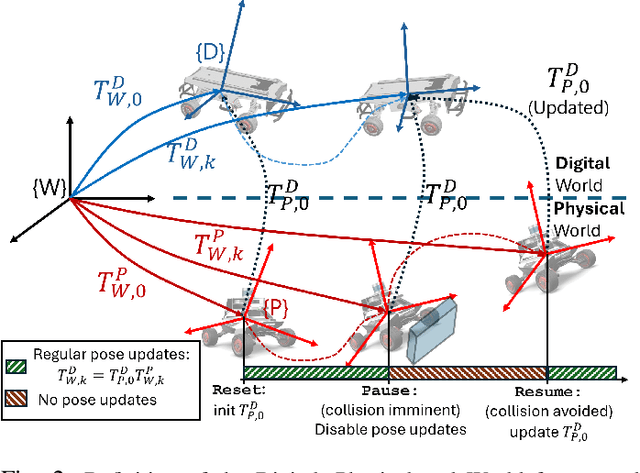
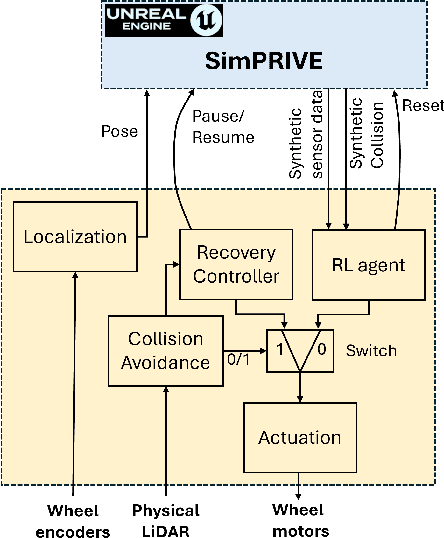
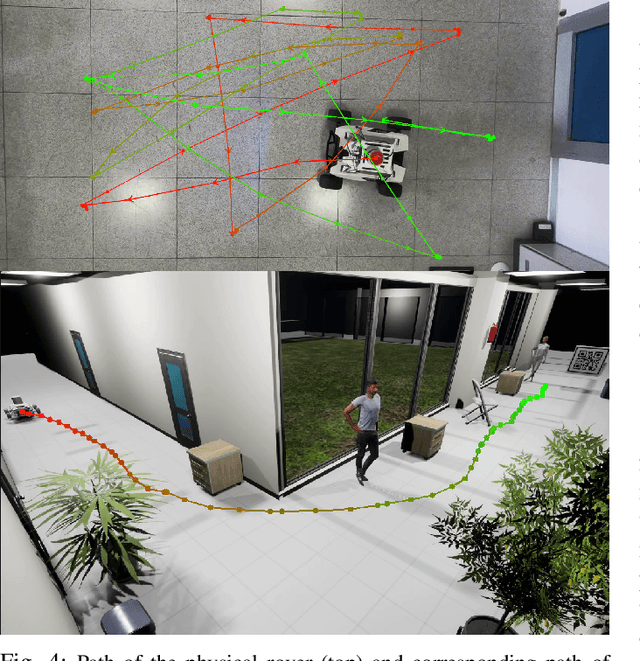
The use of machine learning in cyber-physical systems has attracted the interest of both industry and academia. However, no general solution has yet been found against the unpredictable behavior of neural networks and reinforcement learning agents. Nevertheless, the improvements of photo-realistic simulators have paved the way towards extensive testing of complex algorithms in different virtual scenarios, which would be expensive and dangerous to implement in the real world. This paper presents SimPRIVE, a simulation framework for physical robot interaction with virtual environments, which operates as a vehicle-in-the-loop platform, rendering a virtual world while operating the vehicle in the real world. Using SimPRIVE, any physical mobile robot running on ROS 2 can easily be configured to move its digital twin in a virtual world built with the Unreal Engine 5 graphic engine, which can be populated with objects, people, or other vehicles with programmable behavior. SimPRIVE has been designed to accommodate custom or pre-built virtual worlds while being light-weight to contain execution times and allow fast rendering. Its main advantage lies in the possibility of testing complex algorithms on the full software and hardware stack while minimizing the risks and costs of a test campaign. The framework has been validated by testing a reinforcement learning agent trained for obstacle avoidance on an AgileX Scout Mini rover that navigates a virtual office environment where everyday objects and people are placed as obstacles. The physical rover moves with no collision in an indoor limited space, thanks to a LiDAR-based heuristic.
Feelbert: A Feedback Linearization-based Embedded Real-Time Quadrupedal Locomotion Framework
Apr 29, 2025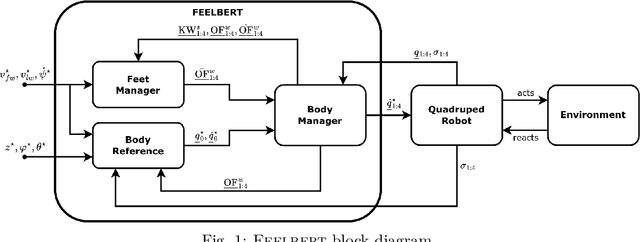
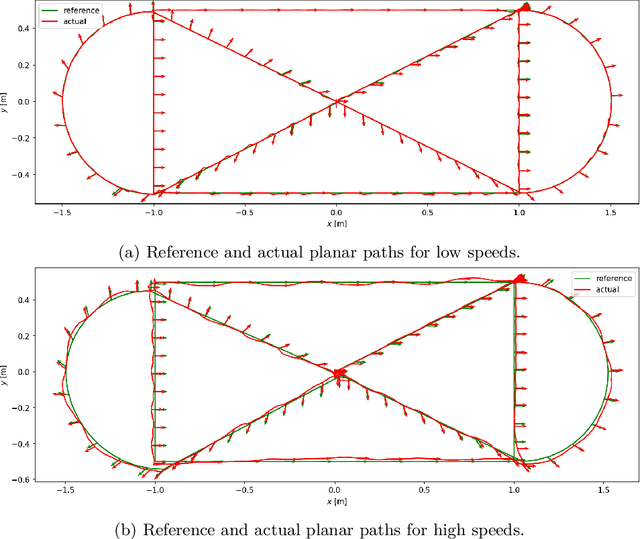
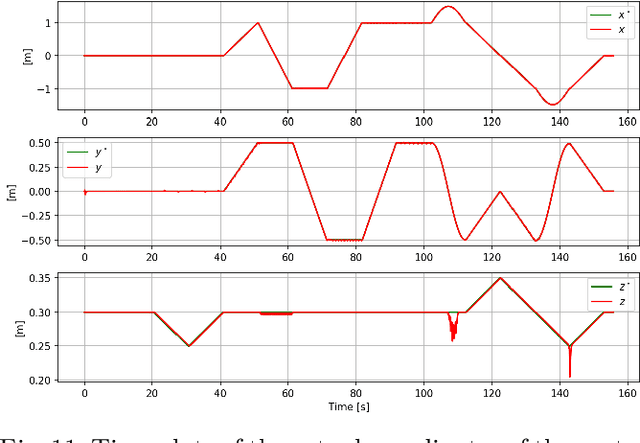
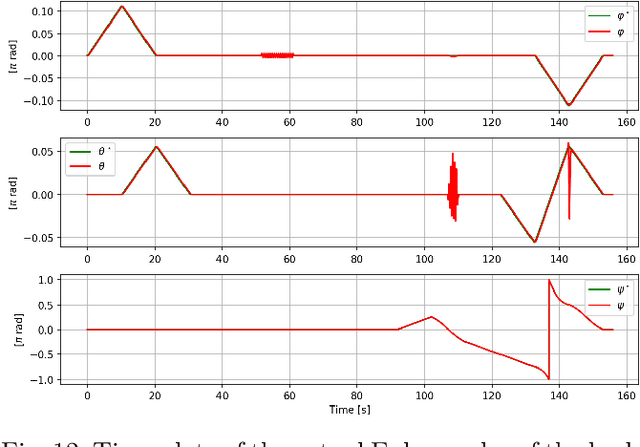
Quadruped robots have become quite popular for their ability to adapt their locomotion to generic uneven terrains. For this reason, over time, several frameworks for quadrupedal locomotion have been proposed, but with little attention to ensuring a predictable timing behavior of the controller. To address this issue, this work presents Feelbert, a modular control framework for quadrupedal locomotion suitable for execution on an embedded system under hard real-time execution constraints. It leverages the feedback linearization control technique to obtain a closed-form control law for the body, valid for all configurations of the robot. The control law was derived after defining an appropriate rigid body model that uses the accelerations of the feet as control variables, instead of the estimated contact forces. This work also provides a novel algorithm to compute footholds and gait temporal parameters using the concept of imaginary wheels, and a heuristic algorithm to select the best gait schedule for the current velocity commands. The proposed framework is developed entirely in C++, with no dependencies on third-party libraries and no dynamic memory allocation, to ensure predictability and real-time performance. Its implementation allows Feelbert to be both compiled and executed on an embedded system for critical applications, as well as integrated into larger systems such as Robot Operating System 2 (ROS 2). For this reason, Feelbert has been tested in both scenarios, demonstrating satisfactory results both in terms of reference tracking and temporal predictability, whether integrated into ROS 2 or compiled as a standalone application on a Raspberry Pi 5.
TrainSim: A Railway Simulation Framework for LiDAR and Camera Dataset Generation
Feb 28, 2023
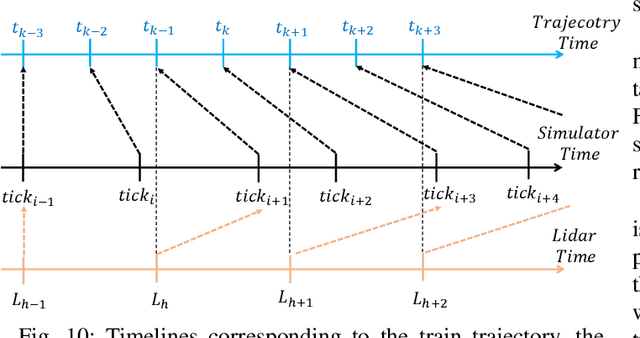

The railway industry is searching for new ways to automate a number of complex train functions, such as object detection, track discrimination, and accurate train positioning, which require the artificial perception of the railway environment through different types of sensors, including cameras, LiDARs, wheel encoders, and inertial measurement units. A promising approach for processing such sensory data is the use of deep learning models, which proved to achieve excellent performance in other application domains, as robotics and self-driving cars. However, testing new algorithms and solutions requires the availability of a large amount of labeled data, acquired in different scenarios and operating conditions, which are difficult to obtain in a real railway setting due to strict regulations and practical constraints in accessing the trackside infrastructure and equipping a train with the required sensors. To address such difficulties, this paper presents a visual simulation framework able to generate realistic railway scenarios in a virtual environment and automatically produce inertial data and labeled datasets from emulated LiDARs and cameras useful for training deep neural networks or testing innovative algorithms. A set of experimental results are reported to show the effectiveness of the proposed approach.
CARLA-GeAR: a Dataset Generator for a Systematic Evaluation of Adversarial Robustness of Vision Models
Jun 09, 2022
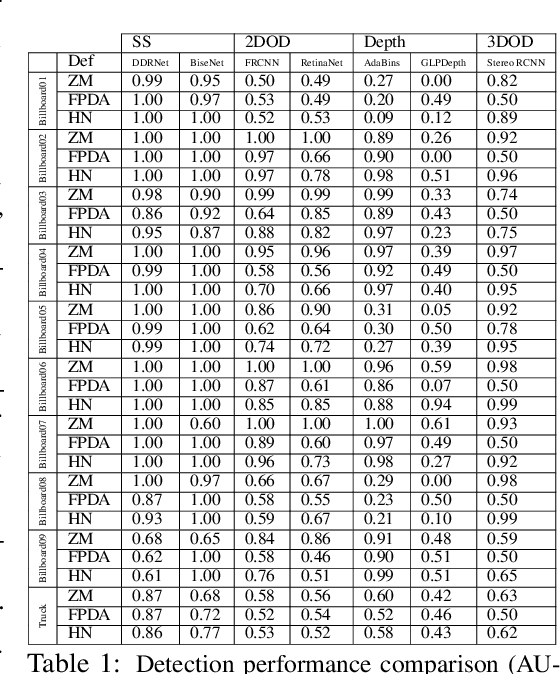
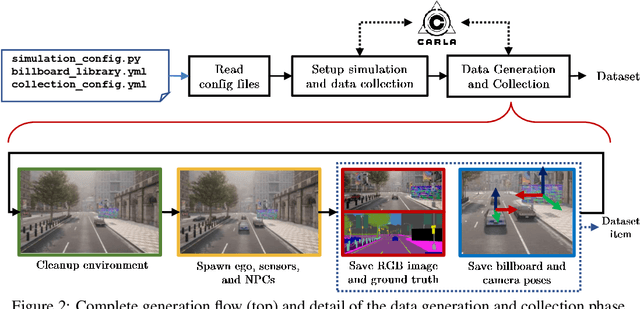
Adversarial examples represent a serious threat for deep neural networks in several application domains and a huge amount of work has been produced to investigate them and mitigate their effects. Nevertheless, no much work has been devoted to the generation of datasets specifically designed to evaluate the adversarial robustness of neural models. This paper presents CARLA-GeAR, a tool for the automatic generation of photo-realistic synthetic datasets that can be used for a systematic evaluation of the adversarial robustness of neural models against physical adversarial patches, as well as for comparing the performance of different adversarial defense/detection methods. The tool is built on the CARLA simulator, using its Python API, and allows the generation of datasets for several vision tasks in the context of autonomous driving. The adversarial patches included in the generated datasets are attached to billboards or the back of a truck and are crafted by using state-of-the-art white-box attack strategies to maximize the prediction error of the model under test. Finally, the paper presents an experimental study to evaluate the performance of some defense methods against such attacks, showing how the datasets generated with CARLA-GeAR might be used in future work as a benchmark for adversarial defense in the real world. All the code and datasets used in this paper are available at http://carlagear.retis.santannapisa.it.
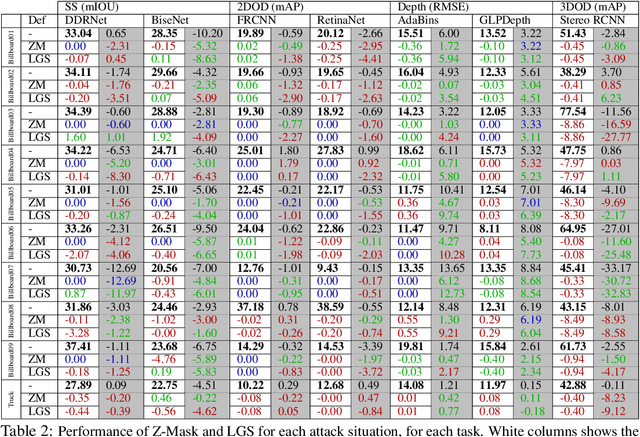
Defending From Physically-Realizable Adversarial Attacks Through Internal Over-Activation Analysis
Mar 14, 2022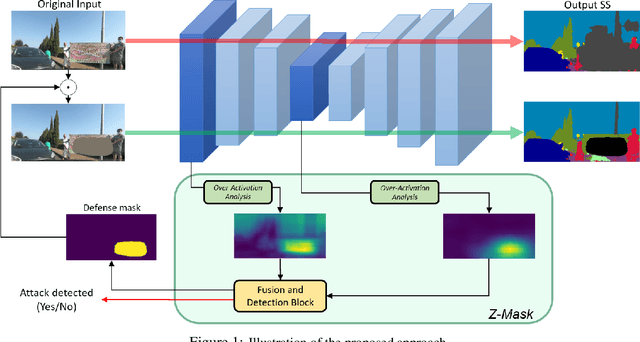

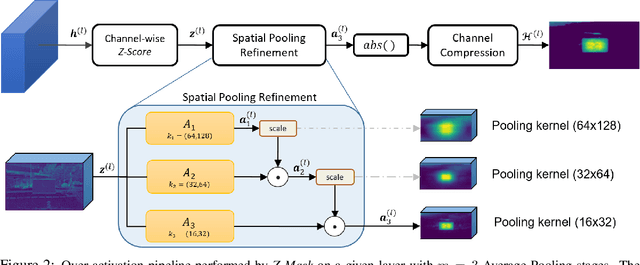
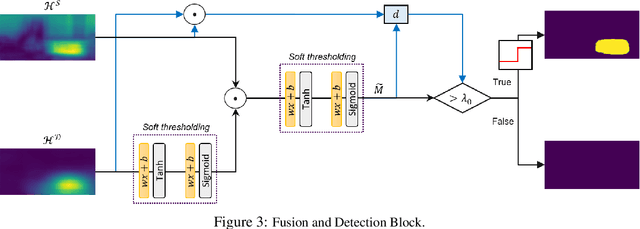
This work presents Z-Mask, a robust and effective strategy to improve the adversarial robustness of convolutional networks against physically-realizable adversarial attacks. The presented defense relies on specific Z-score analysis performed on the internal network features to detect and mask the pixels corresponding to adversarial objects in the input image. To this end, spatially contiguous activations are examined in shallow and deep layers to suggest potential adversarial regions. Such proposals are then aggregated through a multi-thresholding mechanism. The effectiveness of Z-Mask is evaluated with an extensive set of experiments carried out on models for both semantic segmentation and object detection. The evaluation is performed with both digital patches added to the input images and printed patches positioned in the real world. The obtained results confirm that Z-Mask outperforms the state-of-the-art methods in terms of both detection accuracy and overall performance of the networks under attack. Additional experiments showed that Z-Mask is also robust against possible defense-aware attacks.
On the Real-World Adversarial Robustness of Real-Time Semantic Segmentation Models for Autonomous Driving
Jan 05, 2022
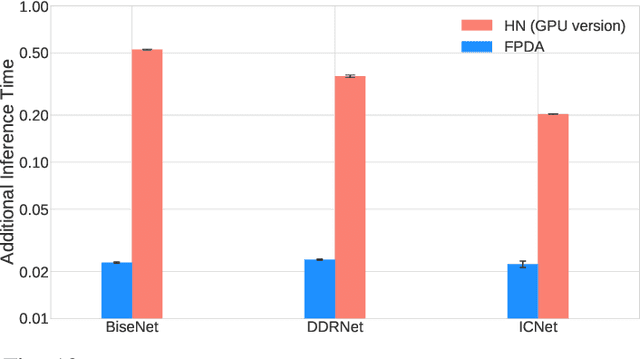
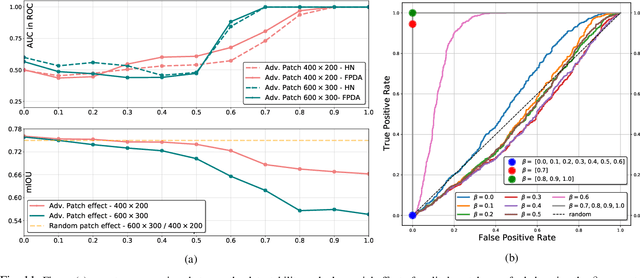
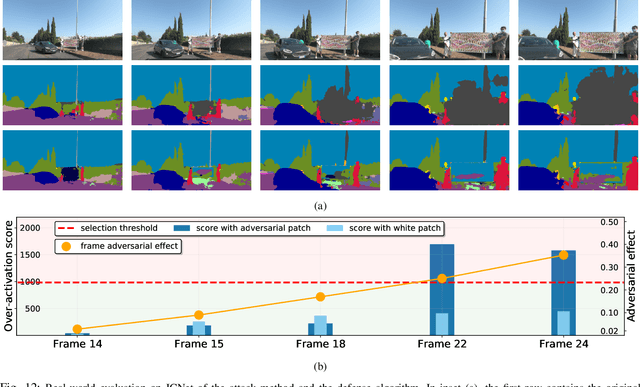
The existence of real-world adversarial examples (commonly in the form of patches) poses a serious threat for the use of deep learning models in safety-critical computer vision tasks such as visual perception in autonomous driving. This paper presents an extensive evaluation of the robustness of semantic segmentation models when attacked with different types of adversarial patches, including digital, simulated, and physical ones. A novel loss function is proposed to improve the capabilities of attackers in inducing a misclassification of pixels. Also, a novel attack strategy is presented to improve the Expectation Over Transformation method for placing a patch in the scene. Finally, a state-of-the-art method for detecting adversarial patch is first extended to cope with semantic segmentation models, then improved to obtain real-time performance, and eventually evaluated in real-world scenarios. Experimental results reveal that, even though the adversarial effect is visible with both digital and real-world attacks, its impact is often spatially confined to areas of the image around the patch. This opens to further questions about the spatial robustness of real-time semantic segmentation models.
Evaluating the Robustness of Semantic Segmentation for Autonomous Driving against Real-World Adversarial Patch Attacks
Aug 13, 2021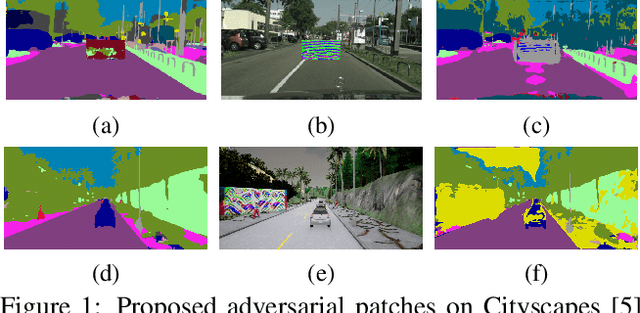
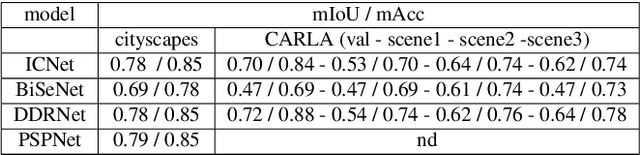
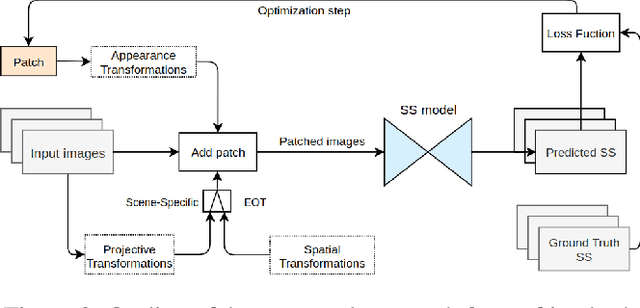

Deep learning and convolutional neural networks allow achieving impressive performance in computer vision tasks, such as object detection and semantic segmentation (SS). However, recent studies have shown evident weaknesses of such models against adversarial perturbations. In a real-world scenario instead, like autonomous driving, more attention should be devoted to real-world adversarial examples (RWAEs), which are physical objects (e.g., billboards and printable patches) optimized to be adversarial to the entire perception pipeline. This paper presents an in-depth evaluation of the robustness of popular SS models by testing the effects of both digital and real-world adversarial patches. These patches are crafted with powerful attacks enriched with a novel loss function. Firstly, an investigation on the Cityscapes dataset is conducted by extending the Expectation Over Transformation (EOT) paradigm to cope with SS. Then, a novel attack optimization, called scene-specific attack, is proposed. Such an attack leverages the CARLA driving simulator to improve the transferability of the proposed EOT-based attack to a real 3D environment. Finally, a printed physical billboard containing an adversarial patch was tested in an outdoor driving scenario to assess the feasibility of the studied attacks in the real world. Exhaustive experiments revealed that the proposed attack formulations outperform previous work to craft both digital and real-world adversarial patches for SS. At the same time, the experimental results showed how these attacks are notably less effective in the real world, hence questioning the practical relevance of adversarial attacks to SS models for autonomous/assisted driving.
Detecting Adversarial Examples by Input Transformations, Defense Perturbations, and Voting
Jan 27, 2021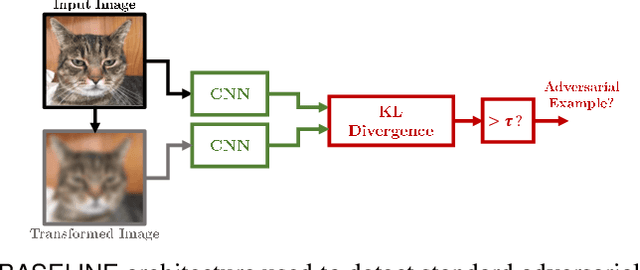
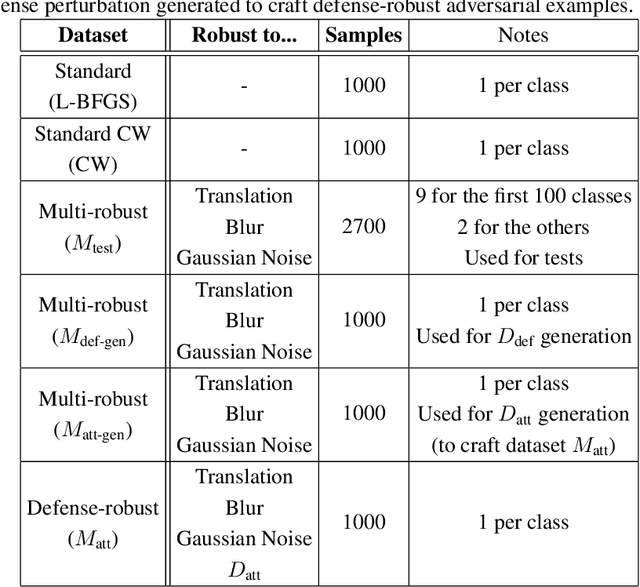
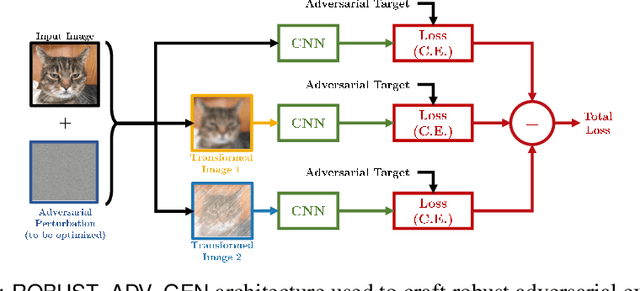
Over the last few years, convolutional neural networks (CNNs) have proved to reach super-human performance in visual recognition tasks. However, CNNs can easily be fooled by adversarial examples, i.e., maliciously-crafted images that force the networks to predict an incorrect output while being extremely similar to those for which a correct output is predicted. Regular adversarial examples are not robust to input image transformations, which can then be used to detect whether an adversarial example is presented to the network. Nevertheless, it is still possible to generate adversarial examples that are robust to such transformations. This paper extensively explores the detection of adversarial examples via image transformations and proposes a novel methodology, called \textit{defense perturbation}, to detect robust adversarial examples with the same input transformations the adversarial examples are robust to. Such a \textit{defense perturbation} is shown to be an effective counter-measure to robust adversarial examples. Furthermore, multi-network adversarial examples are introduced. This kind of adversarial examples can be used to simultaneously fool multiple networks, which is critical in systems that use network redundancy, such as those based on architectures with majority voting over multiple CNNs. An extensive set of experiments based on state-of-the-art CNNs trained on the Imagenet dataset is finally reported.