 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Real-World Adversarial Robustness of Real-Time Semantic Segmentation Models for Autonomous Driving
Jan 05, 2022
The existence of real-world adversarial examples (commonly in the form of patches) poses a serious threat for the use of deep learning models in safety-critical computer vision tasks such as visual perception in autonomous driving. This paper presents an extensive evaluation of the robustness of semantic segmentation models when attacked with different types of adversarial patches, including digital, simulated, and physical ones. A novel loss function is proposed to improve the capabilities of attackers in inducing a misclassification of pixels. Also, a novel attack strategy is presented to improve the Expectation Over Transformation method for placing a patch in the scene. Finally, a state-of-the-art method for detecting adversarial patch is first extended to cope with semantic segmentation models, then improved to obtain real-time performance, and eventually evaluated in real-world scenarios. Experimental results reveal that, even though the adversarial effect is visible with both digital and real-world attacks, its impact is often spatially confined to areas of the image around the patch. This opens to further questions about the spatial robustness of real-time semantic segmentation models.
Evaluating the Robustness of Semantic Segmentation for Autonomous Driving against Real-World Adversarial Patch Attacks
Aug 13, 2021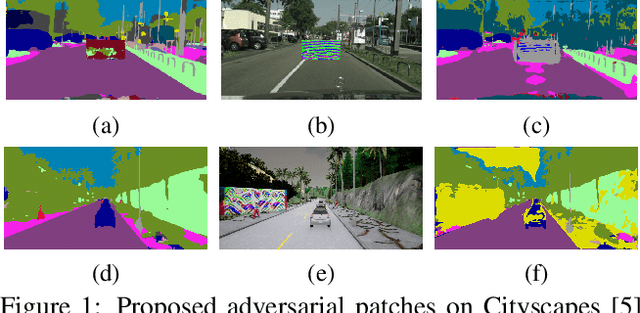
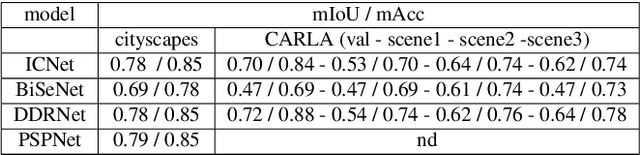
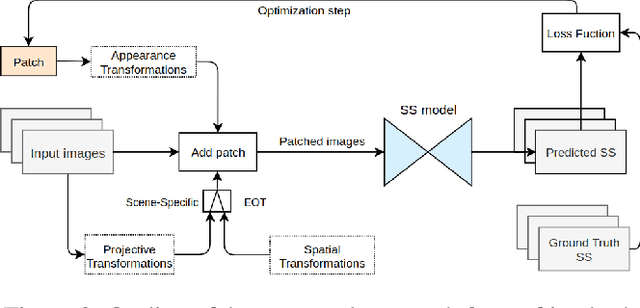

Deep learning and convolutional neural networks allow achieving impressive performance in computer vision tasks, such as object detection and semantic segmentation (SS). However, recent studies have shown evident weaknesses of such models against adversarial perturbations. In a real-world scenario instead, like autonomous driving, more attention should be devoted to real-world adversarial examples (RWAEs), which are physical objects (e.g., billboards and printable patches) optimized to be adversarial to the entire perception pipeline. This paper presents an in-depth evaluation of the robustness of popular SS models by testing the effects of both digital and real-world adversarial patches. These patches are crafted with powerful attacks enriched with a novel loss function. Firstly, an investigation on the Cityscapes dataset is conducted by extending the Expectation Over Transformation (EOT) paradigm to cope with SS. Then, a novel attack optimization, called scene-specific attack, is proposed. Such an attack leverages the CARLA driving simulator to improve the transferability of the proposed EOT-based attack to a real 3D environment. Finally, a printed physical billboard containing an adversarial patch was tested in an outdoor driving scenario to assess the feasibility of the studied attacks in the real world. Exhaustive experiments revealed that the proposed attack formulations outperform previous work to craft both digital and real-world adversarial patches for SS. At the same time, the experimental results showed how these attacks are notably less effective in the real world, hence questioning the practical relevance of adversarial attacks to SS models for autonomous/assisted driving.
Falsification-Based Robust Adversarial Reinforcement Learning
Jul 17, 2020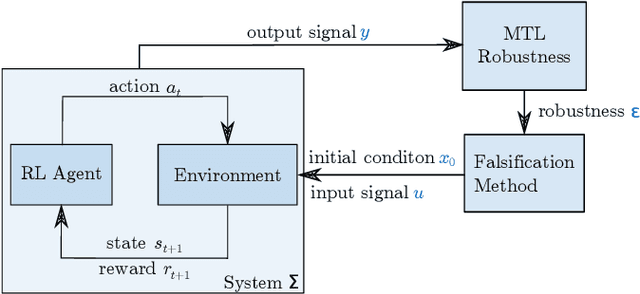

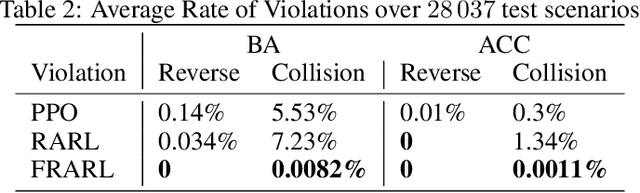
Reinforcement learning (RL) has achieved tremendous progress in solving various sequential decision-making problems, e.g., control tasks in robotics. However, RL methods often fail to generalize to safety-critical scenarios since policies are overfitted to training environments. Previously, robust adversarial reinforcement learning (RARL) was proposed to train an adversarial network that applies disturbances to a system, which improves robustness in test scenarios. A drawback of neural-network-based adversaries is that integrating system requirements without handcrafting sophisticated reward signals is difficult. Safety falsification methods allow one to find a set of initial conditions as well as an input sequence, such that the system violates a given property formulated in temporal logic. In this paper, we propose falsification-based RARL (FRARL), the first generic framework for integrating temporal-logic falsification in adversarial learning to improve policy robustness. With falsification method, we do not need to construct an extra reward function for the adversary. We evaluate our approach on a braking assistance system and an adaptive cruise control system of autonomous vehicles. Experiments show that policies trained with a falsification-based adversary generalize better and show less violation of the safety specification in test scenarios than the ones trained without an adversary or with an adversarial network.