 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Variable Conformal Prediction: Optimizing Prediction Sets without Data Splitting
May 12, 2026Conformal prediction constructs prediction sets with finite-sample coverage guarantees, but its calibration stage is structurally constrained to a scalar score function and a single threshold variable - forcing shapes of prediction sets to be fixed before calibration, typically through data splitting. We introduce multi-variable conformal prediction (MCP), a framework that extends conformal prediction to vector-valued score functions with multiple simultaneous calibration variables. Building on scenario theory as a principled framework for certifying data-driven decisions, MCP unifies prediction set design and calibration into a single optimization problem, eliminating data splitting without sacrificing coverage guarantees. We propose two computationally efficient variants: RemMCP, grounded in constrained optimization with constraint removal, which admits a clean generalization of split conformal prediction; and RelMCP, based on iterative optimization with constraint relaxation, which supports non-convex score functions at the cost of possibly greater conservatism. Through numerical experiments on ellipsoidal and multi-modal prediction sets, we demonstrate that RemMCP and RelMCP consistently meet the target coverage with prediction set sizes smaller than or comparable to those of baselines with data split, while considerably reducing variance across calibration runs - a direct consequence of using all available data for shape optimization and calibration simultaneously.
Formally Verifying Analog Neural Networks Under Process Variations Using Polynomial Zonotopes
May 11, 2026Analog neural networks are gaining attention due to their efficiency in terms of power consumption and processing speed. However, since analog neural networks are implemented as physical circuits, they are highly sensitive to manufacturing process variations, which can cause large deviations from the nominal model. We present a polynomial-based model that resembles the performance of the neuron circuit under process variations. Then, we formally verify the behavior of the circuit-level model using reachability analysis with polynomial zonotopes, thus, avoiding conventional, time-consuming Monte Carlo simulations. We evaluate our proposed verification approach on three different datasets, verifying both fully-connected and convolutional analog neural networks. Our experimental results confirm the effectiveness of our verification approach by reducing the verification time from days to seconds while enclosing 99% of the variation samples.
Set-Based Training of Neural Barrier Certificates for Safety Verification of Dynamical Systems
May 04, 2026Barrier certificates are scalar functions over the state space of dynamical systems that separate all unsafe states from all reachable states. The existence of a barrier certificate formally verifies the safety of the dynamical system. Recent approaches synthesize barrier certificates by iteratively training a neural network. In each iteration, the candidate is formally verified - if successful, the barrier certificate is found. Instead, we propose a set-based training approach that tightly integrates verification into training via a set-based loss function that soundly encodes all barrier certificate properties. A loss of zero formally proves the validity of the barrier certificate, collapsing the iterative training and verification into a single training procedure. Our experiments demonstrate that our set-based training approach scales well with the system dimension and naturally handles complex nonlinear dynamics.
Lexicographic Minimum-Violation Motion Planning using Signal Temporal Logic
Apr 22, 2026Motion planning for autonomous vehicles often requires satisfying multiple conditionally conflicting specifications. In situations where not all specifications can be met simultaneously, minimum-violation motion planning maintains system operation by minimizing violations of specifications in accordance with their priorities. Signal temporal logic (STL) provides a formal language for rigorously defining these specifications and enables the quantitative evaluation of their violations. However, a total ordering of specifications yields a lexicographic optimization problem, which is typically computationally expensive to solve using standard methods. We address this problem by transforming the multi-objective lexicographic optimization problem into a single-objective scalar optimization problem using non-uniform quantization and bit-shifting. Specifically, we extend a deterministic model predictive path integral (MPPI) solver to efficiently solve optimization problems without quadratic input cost. Additionally, a novel predicate-robustness measure that combines spatial and temporal violations is introduced. Our results show that the proposed method offers an interpretable and scalable solution for lexicographic STL minimum-violation motion planning within a single-objective solver framework.
Vision-Based Safe Human-Robot Collaboration with Uncertainty Guarantees
Apr 16, 2026We propose a framework for vision-based human pose estimation and motion prediction that gives conformal prediction guarantees for certifiably safe human-robot collaboration. Our framework combines aleatoric uncertainty estimation with OOD detection for high probabilistic confidence. To integrate our pipeline in certifiable safety frameworks, we propose conformal prediction sets for human motion predictions with high, valid confidence. We evaluate our pipeline on recorded human motion data and a real-world human-robot collaboration setting.
Provably Explaining Neural Additive Models
Feb 19, 2026Despite significant progress in post-hoc explanation methods for neural networks, many remain heuristic and lack provable guarantees. A key approach for obtaining explanations with provable guarantees is by identifying a cardinally-minimal subset of input features which by itself is provably sufficient to determine the prediction. However, for standard neural networks, this task is often computationally infeasible, as it demands a worst-case exponential number of verification queries in the number of input features, each of which is NP-hard. In this work, we show that for Neural Additive Models (NAMs), a recent and more interpretable neural network family, we can efficiently generate explanations with such guarantees. We present a new model-specific algorithm for NAMs that generates provably cardinally-minimal explanations using only a logarithmic number of verification queries in the number of input features, after a parallelized preprocessing step with logarithmic runtime in the required precision is applied to each small univariate NAM component. Our algorithm not only makes the task of obtaining cardinally-minimal explanations feasible, but even outperforms existing algorithms designed to find the relaxed variant of subset-minimal explanations - which may be larger and less informative but easier to compute - despite our algorithm solving a much more difficult task. Our experiments demonstrate that, compared to previous algorithms, our approach provides provably smaller explanations than existing works and substantially reduces the computation time. Moreover, we show that our generated provable explanations offer benefits that are unattainable by standard sampling-based techniques typically used to interpret NAMs.
Perception with Guarantees: Certified Pose Estimation via Reachability Analysis
Feb 10, 2026Agents in cyber-physical systems are increasingly entrusted with safety-critical tasks. Ensuring safety of these agents often requires localizing the pose for subsequent actions. Pose estimates can, e.g., be obtained from various combinations of lidar sensors, cameras, and external services such as GPS. Crucially, in safety-critical domains, a rough estimate is insufficient to formally determine safety, i.e., guaranteeing safety even in the worst-case scenario, and external services might additionally not be trustworthy. We address this problem by presenting a certified pose estimation in 3D solely from a camera image and a well-known target geometry. This is realized by formally bounding the pose, which is computed by leveraging recent results from reachability analysis and formal neural network verification. Our experiments demonstrate that our approach efficiently and accurately localizes agents in both synthetic and real-world experiments.
BSAT: B-Spline Adaptive Tokenizer for Long-Term Time Series Forecasting
Jan 02, 2026Long-term time series forecasting using transformers is hampered by the quadratic complexity of self-attention and the rigidity of uniform patching, which may be misaligned with the data's semantic structure. In this paper, we introduce the \textit{B-Spline Adaptive Tokenizer (BSAT)}, a novel, parameter-free method that adaptively segments a time series by fitting it with B-splines. BSAT algorithmically places tokens in high-curvature regions and represents each variable-length basis function as a fixed-size token, composed of its coefficient and position. Further, we propose a hybrid positional encoding that combines a additive learnable positional encoding with Rotary Positional Embedding featuring a layer-wise learnable base: L-RoPE. This allows each layer to attend to different temporal dependencies. Our experiments on several public benchmarks show that our model is competitive with strong performance at high compression rates. This makes it particularly well-suited for use cases with strong memory constraints.
Results of the 2024 CommonRoad Motion Planning Competition for Autonomous Vehicles
Dec 22, 2025


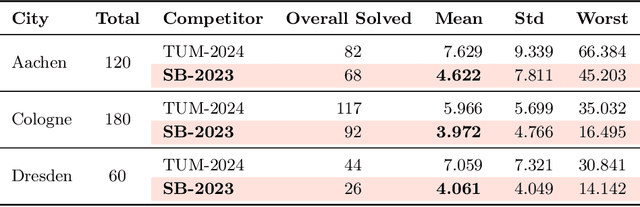
Over the past decade, a wide range of motion planning approaches for autonomous vehicles has been developed to handle increasingly complex traffic scenarios. However, these approaches are rarely compared on standardized benchmarks, limiting the assessment of relative strengths and weaknesses. To address this gap, we present the setup and results of the 4th CommonRoad Motion Planning Competition held in 2024, conducted using the CommonRoad benchmark suite. This annual competition provides an open-source and reproducible framework for benchmarking motion planning algorithms. The benchmark scenarios span highway and urban environments with diverse traffic participants, including passenger cars, buses, and bicycles. Planner performance is evaluated along four dimensions: efficiency, safety, comfort, and compliance with selected traffic rules. This report introduces the competition format and provides a comparison of representative high-performing planners from the 2023 and 2024 editions.
From Demonstrations to Safe Deployment: Path-Consistent Safety Filtering for Diffusion Policies
Nov 09, 2025Diffusion policies (DPs) achieve state-of-the-art performance on complex manipulation tasks by learning from large-scale demonstration datasets, often spanning multiple embodiments and environments. However, they cannot guarantee safe behavior, so external safety mechanisms are needed. These, however, alter actions in ways unseen during training, causing unpredictable behavior and performance degradation. To address these problems, we propose path-consistent safety filtering (PACS) for DPs. Our approach performs path-consistent braking on a trajectory computed from the sequence of generated actions. In this way, we keep execution consistent with the policy's training distribution, maintaining the learned, task-completing behavior. To enable a real-time deployment and handle uncertainties, we verify safety using set-based reachability analysis. Our experimental evaluation in simulation and on three challenging real-world human-robot interaction tasks shows that PACS (a) provides formal safety guarantees in dynamic environments, (b) preserves task success rates, and (c) outperforms reactive safety approaches, such as control barrier functions, by up to 68% in terms of task success. Videos are available at our project website: https://tum-lsy.github.io/pacs/.