 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFinite-Step Invariant Sets for Hybrid Systems with Probabilistic Guarantees
Apr 06, 2026Poincare return maps are a fundamental tool for analyzing periodic orbits in hybrid dynamical systems, including legged locomotion, power electronics, and other cyber-physical systems with switching behavior. The Poincare return map captures the evolution of the hybrid system on a guard surface, reducing the stability analysis of a periodic orbit to that of a discrete-time system. While linearization provides local stability information, assessing robustness to disturbances requires identifying invariant sets of the state space under the return dynamics. However, computing such invariant sets is computationally difficult, especially when system dynamics are only available through forward simulation. In this work, we propose an algorithmic framework leveraging sampling-based optimization to compute a finite-step invariant ellipsoid around a nominal periodic orbit using sampled evaluations of the return map. The resulting solution is accompanied by probabilistic guarantees on finite-step invariance satisfying a user-defined accuracy threshold. We demonstrate the approach on two low-dimensional systems and a compass-gait walking model.
Falsification-Driven Reinforcement Learning for Maritime Motion Planning
Oct 08, 2025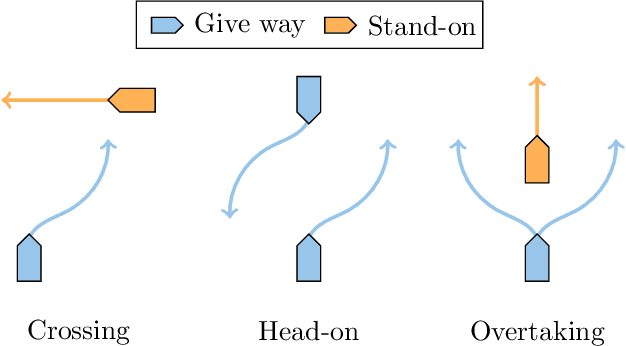



Compliance with maritime traffic rules is essential for the safe operation of autonomous vessels, yet training reinforcement learning (RL) agents to adhere to them is challenging. The behavior of RL agents is shaped by the training scenarios they encounter, but creating scenarios that capture the complexity of maritime navigation is non-trivial, and real-world data alone is insufficient. To address this, we propose a falsification-driven RL approach that generates adversarial training scenarios in which the vessel under test violates maritime traffic rules, which are expressed as signal temporal logic specifications. Our experiments on open-sea navigation with two vessels demonstrate that the proposed approach provides more relevant training scenarios and achieves more consistent rule compliance.
Safe Reinforcement Learning using Action Projection: Safeguard the Policy or the Environment?
Sep 16, 2025Projection-based safety filters, which modify unsafe actions by mapping them to the closest safe alternative, are widely used to enforce safety constraints in reinforcement learning (RL). Two integration strategies are commonly considered: Safe environment RL (SE-RL), where the safeguard is treated as part of the environment, and safe policy RL (SP-RL), where it is embedded within the policy through differentiable optimization layers. Despite their practical relevance in safety-critical settings, a formal understanding of their differences is lacking. In this work, we present a theoretical comparison of SE-RL and SP-RL. We identify a key distinction in how each approach is affected by action aliasing, a phenomenon in which multiple unsafe actions are projected to the same safe action, causing information loss in the policy gradients. In SE-RL, this effect is implicitly approximated by the critic, while in SP-RL, it manifests directly as rank-deficient Jacobians during backpropagation through the safeguard. Our contributions are threefold: (i) a unified formalization of SE-RL and SP-RL in the context of actor-critic algorithms, (ii) a theoretical analysis of their respective policy gradient estimates, highlighting the role of action aliasing, and (iii) a comparative study of mitigation strategies, including a novel penalty-based improvement for SP-RL that aligns with established SE-RL practices. Empirical results support our theoretical predictions, showing that action aliasing is more detrimental for SP-RL than for SE-RL. However, with appropriate improvement strategies, SP-RL can match or outperform improved SE-RL across a range of environments. These findings provide actionable insights for choosing and refining projection-based safe RL methods based on task characteristics.
Learning to Drive by Imitating Surrounding Vehicles
Mar 08, 2025



Imitation learning is a promising approach for training autonomous vehicles (AV) to navigate complex traffic environments by mimicking expert driver behaviors. However, a major challenge in this paradigm lies in effectively utilizing available driving data, as collecting new data is resource-intensive and often limited in its ability to cover diverse driving scenarios. While existing imitation learning frameworks focus on leveraging expert demonstrations, they often overlook the potential of additional complex driving data from surrounding traffic participants. In this paper, we propose a data augmentation strategy that enhances imitation learning by leveraging the observed trajectories of nearby vehicles, captured through the AV's sensors, as additional expert demonstrations. We introduce a vehicle selection sampling strategy that prioritizes informative and diverse driving behaviors, contributing to a richer and more diverse dataset for training. We evaluate our approach using the state-of-the-art learning-based planning method PLUTO on the nuPlan dataset and demonstrate that our augmentation method leads to improved performance in complex driving scenarios. Specifically, our method reduces collision rates and improves safety metrics compared to the baseline. Notably, even when using only 10% of the original dataset, our method achieves performance comparable to that of the full dataset, with improved collision rates. Our findings highlight the importance of leveraging diverse real-world trajectory data in imitation learning and provide insights into data augmentation strategies for autonomous driving.
Intelligent Sailing Model for Open Sea Navigation
Jan 09, 2025



Autonomous vessels potentially enhance safety and reliability of seaborne trade. To facilitate the development of autonomous vessels, high-fidelity simulations are required to model realistic interactions with other vessels. However, modeling realistic interactive maritime traffic is challenging due to the unstructured environment, coarsely specified traffic rules, and largely varying vessel types. Currently, there is no standard for simulating interactive maritime environments in order to rigorously benchmark autonomous vessel algorithms. In this paper, we introduce the first intelligent sailing model (ISM), which simulates rule-compliant vessels for navigation on the open sea. An ISM vessel reacts to other traffic participants according to maritime traffic rules while at the same time solving a motion planning task characterized by waypoints. In particular, the ISM monitors the applicable rules, generates rule-compliant waypoints accordingly, and utilizes a model predictive control for tracking the waypoints. We evaluate the ISM in two environments: interactive traffic with only ISM vessels and mixed traffic where some vessel trajectories are from recorded real-world maritime traffic data or handcrafted for criticality. Our results show that simulations with many ISM vessels of different vessel types are rule-compliant and scalable. We tested 4,049 critical traffic scenarios. For interactive traffic with ISM vessels, no collisions occurred while goal-reaching rates of about 97 percent were achieved. We believe that our ISM can serve as a standard for challenging and realistic maritime traffic simulation to accelerate autonomous vessel development.
Excluding the Irrelevant: Focusing Reinforcement Learning through Continuous Action Masking
Jun 06, 2024



Continuous action spaces in reinforcement learning (RL) are commonly defined as interval sets. While intervals usually reflect the action boundaries for tasks well, they can be challenging for learning because the typically large global action space leads to frequent exploration of irrelevant actions. Yet, little task knowledge can be sufficient to identify significantly smaller state-specific sets of relevant actions. Focusing learning on these relevant actions can significantly improve training efficiency and effectiveness. In this paper, we propose to focus learning on the set of relevant actions and introduce three continuous action masking methods for exactly mapping the action space to the state-dependent set of relevant actions. Thus, our methods ensure that only relevant actions are executed, enhancing the predictability of the RL agent and enabling its use in safety-critical applications. We further derive the implications of the proposed methods on the policy gradient. Using Proximal Policy Optimization (PPO), we evaluate our methods on three control tasks, where the relevant action set is computed based on the system dynamics and a relevant state set. Our experiments show that the three action masking methods achieve higher final rewards and converge faster than the baseline without action masking.
Provable Traffic Rule Compliance in Safe Reinforcement Learning on the Open Sea
Feb 13, 2024



Autonomous vehicles have to obey traffic rules. These rules are often formalized using temporal logic, resulting in constraints that are hard to solve using optimization-based motion planners. Reinforcement Learning (RL) is a promising method to find motion plans adhering to temporal logic specifications. However, vanilla RL algorithms are based on random exploration, which is inherently unsafe. To address this issue, we propose a provably safe RL approach that always complies with traffic rules. As a specific application area, we consider vessels on the open sea, which must adhere to the Convention on the International Regulations for Preventing Collisions at Sea (COLREGS). We introduce an efficient verification approach that determines the compliance of actions with respect to the COLREGS formalized using temporal logic. Our action verification is integrated into the RL process so that the agent only selects verified actions. In contrast to agents that only integrate the traffic rule information in the reward function, our provably safe agent always complies with the formalized rules in critical maritime traffic situations and, thus, never causes a collision.
Maximizing Seaweed Growth on Autonomous Farms: A Dynamic Programming Approach for Underactuated Systems Navigating on Uncertain Ocean Currents
Jul 04, 2023Seaweed biomass offers significant potential for climate mitigation, but large-scale, autonomous open-ocean farms are required to fully exploit it. Such farms typically have low propulsion and are heavily influenced by ocean currents. We want to design a controller that maximizes seaweed growth over months by taking advantage of the non-linear time-varying ocean currents for reaching high-growth regions. The complex dynamics and underactuation make this challenging even when the currents are known. This is even harder when only short-term imperfect forecasts with increasing uncertainty are available. We propose a dynamic programming-based method to efficiently solve for the optimal growth value function when true currents are known. We additionally present three extensions when as in reality only forecasts are known: (1) our methods resulting value function can be used as feedback policy to obtain the growth-optimal control for all states and times, allowing closed-loop control equivalent to re-planning at every time step hence mitigating forecast errors, (2) a feedback policy for long-term optimal growth beyond forecast horizons using seasonal average current data as terminal reward, and (3) a discounted finite-time Dynamic Programming (DP) formulation to account for increasing ocean current estimate uncertainty. We evaluate our approach through 30-day simulations of floating seaweed farms in realistic Pacific Ocean current scenarios. Our method demonstrates an achievement of 95.8% of the best possible growth using only 5-day forecasts. This confirms the feasibility of using low-power propulsion and optimal control for enhanced seaweed growth on floating farms under real-world conditions.
Stranding Risk for Underactuated Vessels in Complex Ocean Currents: Analysis and Controllers
Jul 04, 2023Low-propulsion vessels can take advantage of powerful ocean currents to navigate towards a destination. Recent results demonstrated that vessels can reach their destination with high probability despite forecast errors. However, these results do not consider the critical aspect of safety of such vessels: because of their low propulsion which is much smaller than the magnitude of currents, they might end up in currents that inevitably push them into unsafe areas such as shallow areas, garbage patches, and shipping lanes. In this work, we first investigate the risk of stranding for free-floating vessels in the Northeast Pacific. We find that at least 5.04% would strand within 90 days. Next, we encode the unsafe sets as hard constraints into Hamilton-Jacobi Multi-Time Reachability (HJ-MTR) to synthesize a feedback policy that is equivalent to re-planning at each time step at low computational cost. While applying this policy closed-loop guarantees safe operation when the currents are known, in realistic situations only imperfect forecasts are available. We demonstrate the safety of our approach in such realistic situations empirically with large-scale simulations of a vessel navigating in high-risk regions in the Northeast Pacific. We find that applying our policy closed-loop with daily re-planning on new forecasts can ensure safety with high probability even under forecast errors that exceed the maximal propulsion. Our method significantly improves safety over the baselines and still achieves a timely arrival of the vessel at the destination.
Verifiably Safe Reinforcement Learning with Probabilistic Guarantees via Temporal Logic
Dec 12, 2022Reinforcement Learning (RL) can solve complex tasks but does not intrinsically provide any guarantees on system behavior. For real-world systems that fulfill safety-critical tasks, such guarantees on safety specifications are necessary. To bridge this gap, we propose a verifiably safe RL procedure with probabilistic guarantees. First, our approach probabilistically verifies a candidate controller with respect to a temporal logic specification, while randomizing the controller's inputs within a bounded set. Then, we use RL to improve the performance of this probabilistically verified, i.e. safe, controller and explore in the same bounded set around the controller's input as was randomized over in the verification step. Finally, we calculate probabilistic safety guarantees with respect to temporal logic specifications for the learned agent. Our approach is efficient for continuous action and state spaces and separates safety verification and performance improvement into two independent steps. We evaluate our approach on a safe evasion task where a robot has to evade a dynamic obstacle in a specific manner while trying to reach a goal. The results show that our verifiably safe RL approach leads to efficient learning and performance improvements while maintaining safety specifications.