 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCongestion Reduction in EV Charger Placement Using Traffic Equilibrium Models
Dec 12, 2025



Growing EV adoption can worsen traffic conditions if chargers are sited without regard to their impact on congestion. We study how to strategically place EV chargers to reduce congestion using two equilibrium models: one based on congestion games and one based on an atomic queueing simulation. We apply both models within a scalable greedy station-placement algorithm. Experiments show that this greedy scheme yields optimal or near-optimal congestion outcomes in realistic networks, even though global optimality is not guaranteed as we show with a counterexample. We also show that the queueing-based approach yields more realistic results than the congestion-game model, and we present a unified methodology that calibrates congestion delays from queue simulation and solves equilibrium in link-space.
Learning to Drive by Imitating Surrounding Vehicles
Mar 08, 2025



Imitation learning is a promising approach for training autonomous vehicles (AV) to navigate complex traffic environments by mimicking expert driver behaviors. However, a major challenge in this paradigm lies in effectively utilizing available driving data, as collecting new data is resource-intensive and often limited in its ability to cover diverse driving scenarios. While existing imitation learning frameworks focus on leveraging expert demonstrations, they often overlook the potential of additional complex driving data from surrounding traffic participants. In this paper, we propose a data augmentation strategy that enhances imitation learning by leveraging the observed trajectories of nearby vehicles, captured through the AV's sensors, as additional expert demonstrations. We introduce a vehicle selection sampling strategy that prioritizes informative and diverse driving behaviors, contributing to a richer and more diverse dataset for training. We evaluate our approach using the state-of-the-art learning-based planning method PLUTO on the nuPlan dataset and demonstrate that our augmentation method leads to improved performance in complex driving scenarios. Specifically, our method reduces collision rates and improves safety metrics compared to the baseline. Notably, even when using only 10% of the original dataset, our method achieves performance comparable to that of the full dataset, with improved collision rates. Our findings highlight the importance of leveraging diverse real-world trajectory data in imitation learning and provide insights into data augmentation strategies for autonomous driving.
Exploiting Symmetry in Dynamics for Model-Based Reinforcement Learning with Asymmetric Rewards
Mar 27, 2024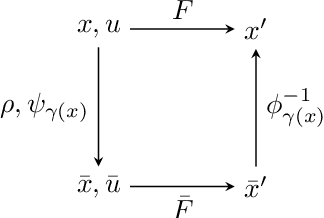

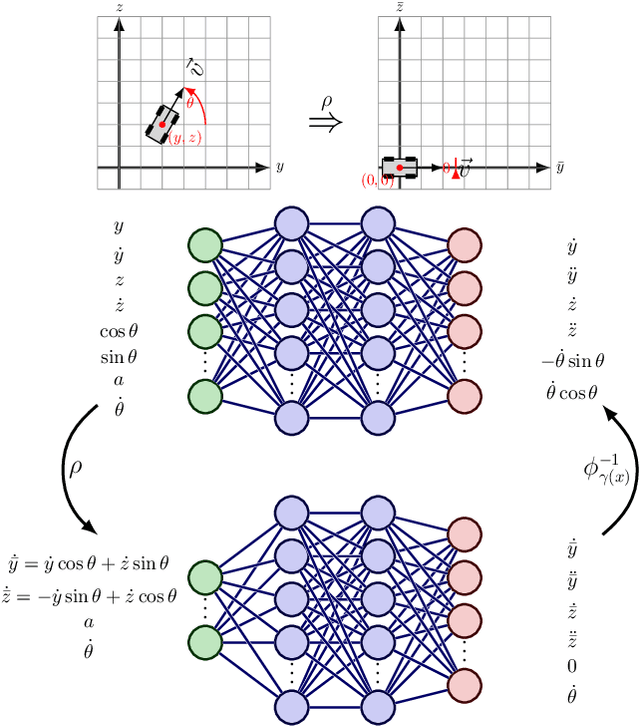
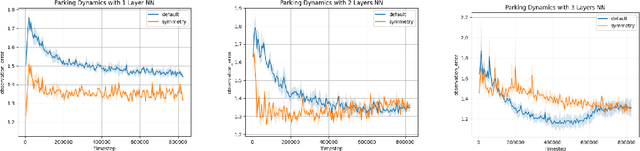
Recent work in reinforcement learning has leveraged symmetries in the model to improve sample efficiency in training a policy. A commonly used simplifying assumption is that the dynamics and reward both exhibit the same symmetry. However, in many real-world environments, the dynamical model exhibits symmetry independent of the reward model: the reward may not satisfy the same symmetries as the dynamics. In this paper, we investigate scenarios where only the dynamics are assumed to exhibit symmetry, extending the scope of problems in reinforcement learning and learning in control theory where symmetry techniques can be applied. We use Cartan's moving frame method to introduce a technique for learning dynamics which, by construction, exhibit specified symmetries. We demonstrate through numerical experiments that the proposed method learns a more accurate dynamical model.