 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStranding Risk for Underactuated Vessels in Complex Ocean Currents: Analysis and Controllers
Jul 04, 2023Low-propulsion vessels can take advantage of powerful ocean currents to navigate towards a destination. Recent results demonstrated that vessels can reach their destination with high probability despite forecast errors. However, these results do not consider the critical aspect of safety of such vessels: because of their low propulsion which is much smaller than the magnitude of currents, they might end up in currents that inevitably push them into unsafe areas such as shallow areas, garbage patches, and shipping lanes. In this work, we first investigate the risk of stranding for free-floating vessels in the Northeast Pacific. We find that at least 5.04% would strand within 90 days. Next, we encode the unsafe sets as hard constraints into Hamilton-Jacobi Multi-Time Reachability (HJ-MTR) to synthesize a feedback policy that is equivalent to re-planning at each time step at low computational cost. While applying this policy closed-loop guarantees safe operation when the currents are known, in realistic situations only imperfect forecasts are available. We demonstrate the safety of our approach in such realistic situations empirically with large-scale simulations of a vessel navigating in high-risk regions in the Northeast Pacific. We find that applying our policy closed-loop with daily re-planning on new forecasts can ensure safety with high probability even under forecast errors that exceed the maximal propulsion. Our method significantly improves safety over the baselines and still achieves a timely arrival of the vessel at the destination.
Maximizing Seaweed Growth on Autonomous Farms: A Dynamic Programming Approach for Underactuated Systems Navigating on Uncertain Ocean Currents
Jul 04, 2023Seaweed biomass offers significant potential for climate mitigation, but large-scale, autonomous open-ocean farms are required to fully exploit it. Such farms typically have low propulsion and are heavily influenced by ocean currents. We want to design a controller that maximizes seaweed growth over months by taking advantage of the non-linear time-varying ocean currents for reaching high-growth regions. The complex dynamics and underactuation make this challenging even when the currents are known. This is even harder when only short-term imperfect forecasts with increasing uncertainty are available. We propose a dynamic programming-based method to efficiently solve for the optimal growth value function when true currents are known. We additionally present three extensions when as in reality only forecasts are known: (1) our methods resulting value function can be used as feedback policy to obtain the growth-optimal control for all states and times, allowing closed-loop control equivalent to re-planning at every time step hence mitigating forecast errors, (2) a feedback policy for long-term optimal growth beyond forecast horizons using seasonal average current data as terminal reward, and (3) a discounted finite-time Dynamic Programming (DP) formulation to account for increasing ocean current estimate uncertainty. We evaluate our approach through 30-day simulations of floating seaweed farms in realistic Pacific Ocean current scenarios. Our method demonstrates an achievement of 95.8% of the best possible growth using only 5-day forecasts. This confirms the feasibility of using low-power propulsion and optimal control for enhanced seaweed growth on floating farms under real-world conditions.
Inducing Structure in Reward Learning by Learning Features
Jan 18, 2022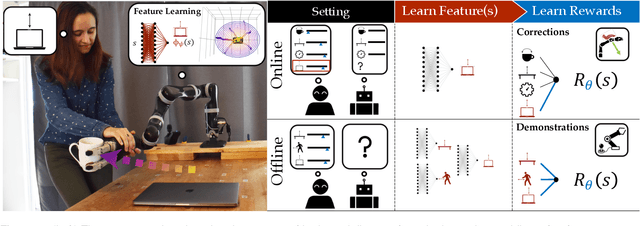


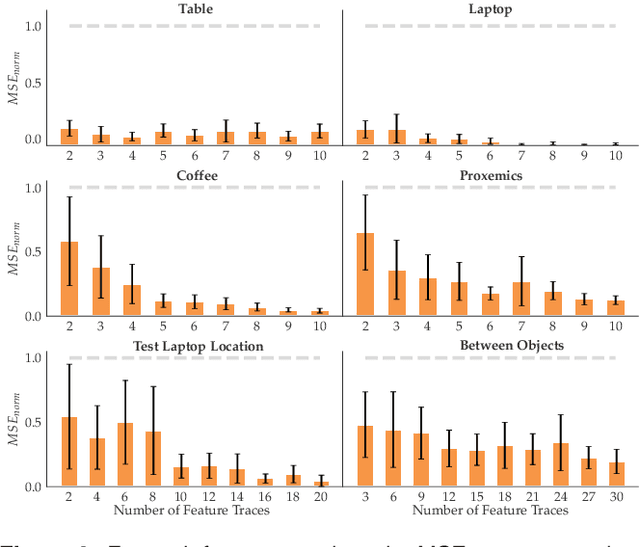
Reward learning enables robots to learn adaptable behaviors from human input. Traditional methods model the reward as a linear function of hand-crafted features, but that requires specifying all the relevant features a priori, which is impossible for real-world tasks. To get around this issue, recent deep Inverse Reinforcement Learning (IRL) methods learn rewards directly from the raw state but this is challenging because the robot has to implicitly learn the features that are important and how to combine them, simultaneously. Instead, we propose a divide and conquer approach: focus human input specifically on learning the features separately, and only then learn how to combine them into a reward. We introduce a novel type of human input for teaching features and an algorithm that utilizes it to learn complex features from the raw state space. The robot can then learn how to combine them into a reward using demonstrations, corrections, or other reward learning frameworks. We demonstrate our method in settings where all features have to be learned from scratch, as well as where some of the features are known. By first focusing human input specifically on the feature(s), our method decreases sample complexity and improves generalization of the learned reward over a deepIRL baseline. We show this in experiments with a physical 7DOF robot manipulator, as well as in a user study conducted in a simulated environment.
Feature Expansive Reward Learning: Rethinking Human Input
Jun 23, 2020

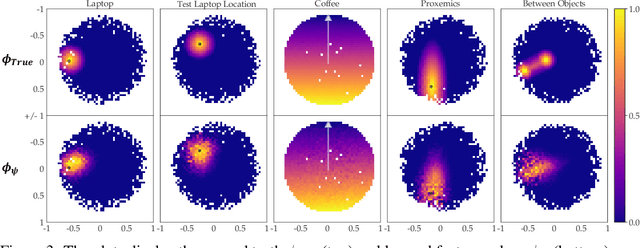
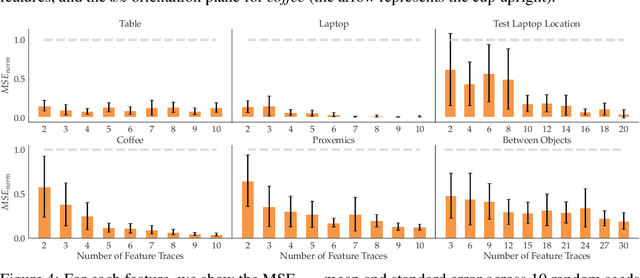
In collaborative human-robot scenarios, when a person is not satisfied with how a robot performs a task, they can intervene to correct it. Reward learning methods enable the robot to adapt its reward function online based on such human input. However, this online adaptation requires low sample complexity algorithms which rely on simple functions of handcrafted features. In practice, pre-specifying an exhaustive set of features the person might care about is impossible; what should the robot do when the human correction cannot be explained by the features it already has access to? Recent progress in deep Inverse Reinforcement Learning (IRL) suggests that the robot could fall back on demonstrations: ask the human for demonstrations of the task, and recover a reward defined over not just the known features, but also the raw state space. Our insight is that rather than implicitly learning about the missing feature(s) from task demonstrations, the robot should instead ask for data that explicitly teaches it about what it is missing. We introduce a new type of human input, in which the person guides the robot from areas of the state space where the feature she is teaching is highly expressed to states where it is not. We propose an algorithm for learning the feature from the raw state space and integrating it into the reward function. By focusing the human input on the missing feature, our method decreases sample complexity and improves generalization of the learned reward over the above deep IRL baseline. We show this in experiments with a 7DOF robot manipulator. Finally, we discuss our method's potential implications for deep reward learning more broadly: taking a divide-and-conquer approach that focuses on important features separately before learning from demonstrations can improve generalization in tasks where such features are easy for the human to teach.