 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplaining Low Perception Model Competency with High-Competency Counterfactuals
Apr 07, 2025There exist many methods to explain how an image classification model generates its decision, but very little work has explored methods to explain why a classifier might lack confidence in its prediction. As there are various reasons the classifier might lose confidence, it would be valuable for this model to not only indicate its level of uncertainty but also explain why it is uncertain. Counterfactual images have been used to visualize changes that could be made to an image to generate a different classification decision. In this work, we explore the use of counterfactuals to offer an explanation for low model competency--a generalized form of predictive uncertainty that measures confidence. Toward this end, we develop five novel methods to generate high-competency counterfactual images, namely Image Gradient Descent (IGD), Feature Gradient Descent (FGD), Autoencoder Reconstruction (Reco), Latent Gradient Descent (LGD), and Latent Nearest Neighbors (LNN). We evaluate these methods across two unique datasets containing images with six known causes for low model competency and find Reco, LGD, and LNN to be the most promising methods for counterfactual generation. We further evaluate how these three methods can be utilized by pre-trained Multimodal Large Language Models (MLLMs) to generate language explanations for low model competency. We find that the inclusion of a counterfactual image in the language model query greatly increases the ability of the model to generate an accurate explanation for the cause of low model competency, thus demonstrating the utility of counterfactual images in explaining low perception model competency.
What Do Learning Dynamics Reveal About Generalization in LLM Reasoning?
Nov 12, 2024



Despite the remarkable capabilities of modern large language models (LLMs), the mechanisms behind their problem-solving abilities remain elusive. In this work, we aim to better understand how the learning dynamics of LLM finetuning shapes downstream generalization. Our analysis focuses on reasoning tasks, whose problem structure allows us to distinguish between memorization (the exact replication of reasoning steps from the training data) and performance (the correctness of the final solution). We find that a model's generalization behavior can be effectively characterized by a training metric we call pre-memorization train accuracy: the accuracy of model samples on training queries before they begin to copy the exact reasoning steps from the training set. On the dataset level, this metric is able to reliably predict test accuracy, achieving $R^2$ of around or exceeding 0.9 across various models (Llama3 8, Gemma2 9B), datasets (GSM8k, MATH), and training configurations. On a per-example level, this metric is also indicative of whether individual model predictions are robust to perturbations in the training query. By connecting a model's learning behavior to its generalization, pre-memorization train accuracy can guide targeted improvements to training strategies. We focus on data curation as an example, and show that prioritizing examples with low pre-memorization accuracy leads to 1.5-2x improvements in data efficiency compared to i.i.d. data scaling, and outperforms other standard data curation techniques.
PaRCE: Probabilistic and Reconstruction-Based Competency Estimation for Safe Navigation Under Perception Uncertainty
Sep 09, 2024



Perception-based navigation systems are useful for unmanned ground vehicle (UGV) navigation in complex terrains, where traditional depth-based navigation schemes are insufficient. However, these data-driven methods are highly dependent on their training data and can fail in surprising and dramatic ways with little warning. To ensure the safety of the vehicle and the surrounding environment, it is imperative that the navigation system is able to recognize the predictive uncertainty of the perception model and respond safely and effectively in the face of uncertainty. In an effort to enable safe navigation under perception uncertainty, we develop a probabilistic and reconstruction-based competency estimation (PaRCE) method to estimate the model's level of familiarity with an input image as a whole and with specific regions in the image. We find that the overall competency score can correctly predict correctly classified, misclassified, and out-of-distribution (OOD) samples. We also confirm that the regional competency maps can accurately distinguish between familiar and unfamiliar regions across images. We then use this competency information to develop a planning and control scheme that enables effective navigation while maintaining a low probability of error. We find that the competency-aware scheme greatly reduces the number of collisions with unfamiliar obstacles, compared to a baseline controller with no competency awareness. Furthermore, the regional competency information is very valuable in enabling efficient navigation.
Understanding the Dependence of Perception Model Competency on Regions in an Image
Jul 15, 2024While deep neural network (DNN)-based perception models are useful for many applications, these models are black boxes and their outputs are not yet well understood. To confidently enable a real-world, decision-making system to utilize such a perception model without human intervention, we must enable the system to reason about the perception model's level of competency and respond appropriately when the model is incompetent. In order for the system to make an intelligent decision about the appropriate action when the model is incompetent, it would be useful for the system to understand why the model is incompetent. We explore five novel methods for identifying regions in the input image contributing to low model competency, which we refer to as image cropping, segment masking, pixel perturbation, competency gradients, and reconstruction loss. We assess the ability of these five methods to identify unfamiliar objects, recognize regions associated with unseen classes, and identify unexplored areas in an environment. We find that the competency gradients and reconstruction loss methods show great promise in identifying regions associated with low model competency, particularly when aspects of the image that are unfamiliar to the perception model are causing this reduction in competency. Both of these methods boast low computation times and high levels of accuracy in detecting image regions that are unfamiliar to the model, allowing them to provide potential utility in decision-making pipelines. The code for reproducing our methods and results is available on GitHub: https://github.com/sarapohland/explainable-competency.
Stranger Danger! Identifying and Avoiding Unpredictable Pedestrians in RL-based Social Robot Navigation
Jul 08, 2024
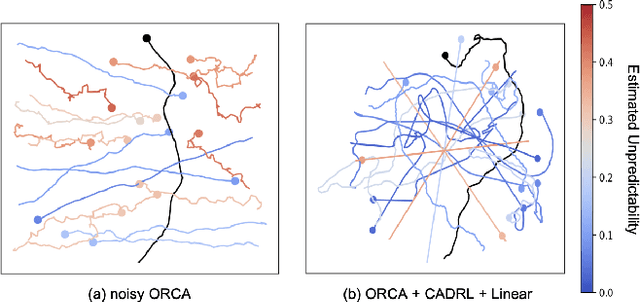


Reinforcement learning (RL) methods for social robot navigation show great success navigating robots through large crowds of people, but the performance of these learning-based methods tends to degrade in particularly challenging or unfamiliar situations due to the models' dependency on representative training data. To ensure human safety and comfort, it is critical that these algorithms handle uncommon cases appropriately, but the low frequency and wide diversity of such situations present a significant challenge for these data-driven methods. To overcome this challenge, we propose modifications to the learning process that encourage these RL policies to maintain additional caution in unfamiliar situations. Specifically, we improve the Socially Attentive Reinforcement Learning (SARL) policy by (1) modifying the training process to systematically introduce deviations into a pedestrian model, (2) updating the value network to estimate and utilize pedestrian-unpredictability features, and (3) implementing a reward function to learn an effective response to pedestrian unpredictability. Compared to the original SARL policy, our modified policy maintains similar navigation times and path lengths, while reducing the number of collisions by 82% and reducing the proportion of time spent in the pedestrians' personal space by up to 19 percentage points for the most difficult cases. We also describe how to apply these modifications to other RL policies and demonstrate that some key high-level behaviors of our approach transfer to a physical robot.
Unfamiliar Finetuning Examples Control How Language Models Hallucinate
Mar 08, 2024

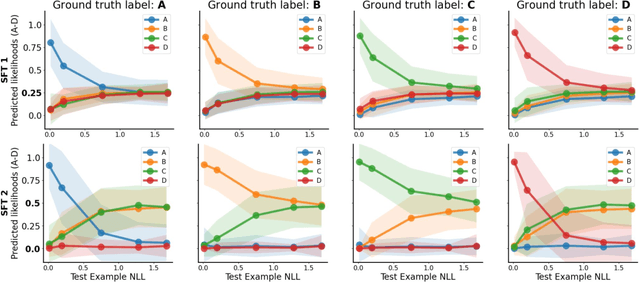

Large language models (LLMs) have a tendency to generate plausible-sounding yet factually incorrect responses, especially when queried on unfamiliar concepts. In this work, we explore the underlying mechanisms that govern how finetuned LLMs hallucinate. Our investigation reveals an interesting pattern: as inputs become more unfamiliar, LLM outputs tend to default towards a ``hedged'' prediction, whose form is determined by how the unfamiliar examples in the finetuning data are supervised. Thus, by strategically modifying these examples' supervision, we can control LLM predictions for unfamiliar inputs (e.g., teach them to say ``I don't know''). Based on these principles, we develop an RL approach that more reliably mitigates hallucinations for long-form generation tasks, by tackling the challenges presented by reward model hallucinations. We validate our findings with a series of controlled experiments in multiple-choice QA on MMLU, as well as long-form biography and book/movie plot generation tasks.
Hacking Predictors Means Hacking Cars: Using Sensitivity Analysis to Identify Trajectory Prediction Vulnerabilities for Autonomous Driving Security
Jan 18, 2024Adversarial attacks on learning-based trajectory predictors have already been demonstrated. However, there are still open questions about the effects of perturbations on trajectory predictor inputs other than state histories, and how these attacks impact downstream planning and control. In this paper, we conduct a sensitivity analysis on two trajectory prediction models, Trajectron++ and AgentFormer. We observe that between all inputs, almost all of the perturbation sensitivities for Trajectron++ lie only within the most recent state history time point, while perturbation sensitivities for AgentFormer are spread across state histories over time. We additionally demonstrate that, despite dominant sensitivity on state history perturbations, an undetectable image map perturbation made with the Fast Gradient Sign Method can induce large prediction error increases in both models. Even though image maps may contribute slightly to the prediction output of both models, this result reveals that rather than being robust to adversarial image perturbations, trajectory predictors are susceptible to image attacks. Using an optimization-based planner and example perturbations crafted from sensitivity results, we show how this vulnerability can cause a vehicle to come to a sudden stop from moderate driving speeds.
Deep Neural Networks Tend To Extrapolate Predictably
Oct 02, 2023



Conventional wisdom suggests that neural network predictions tend to be unpredictable and overconfident when faced with out-of-distribution (OOD) inputs. Our work reassesses this assumption for neural networks with high-dimensional inputs. Rather than extrapolating in arbitrary ways, we observe that neural network predictions often tend towards a constant value as input data becomes increasingly OOD. Moreover, we find that this value often closely approximates the optimal constant solution (OCS), i.e., the prediction that minimizes the average loss over the training data without observing the input. We present results showing this phenomenon across 8 datasets with different distributional shifts (including CIFAR10-C and ImageNet-R, S), different loss functions (cross entropy, MSE, and Gaussian NLL), and different architectures (CNNs and transformers). Furthermore, we present an explanation for this behavior, which we first validate empirically and then study theoretically in a simplified setting involving deep homogeneous networks with ReLU activations. Finally, we show how one can leverage our insights in practice to enable risk-sensitive decision-making in the presence of OOD inputs.
Linking vision and motion for self-supervised object-centric perception
Jul 14, 2023Object-centric representations enable autonomous driving algorithms to reason about interactions between many independent agents and scene features. Traditionally these representations have been obtained via supervised learning, but this decouples perception from the downstream driving task and could harm generalization. In this work we adapt a self-supervised object-centric vision model to perform object decomposition using only RGB video and the pose of the vehicle as inputs. We demonstrate that our method obtains promising results on the Waymo Open perception dataset. While object mask quality lags behind supervised methods or alternatives that use more privileged information, we find that our model is capable of learning a representation that fuses multiple camera viewpoints over time and successfully tracks many vehicles and pedestrians in the dataset. Code for our model is available at https://github.com/wayveai/SOCS.
Cost Inference for Feedback Dynamic Games from Noisy Partial State Observations and Incomplete Trajectories
Jan 04, 2023



In multi-agent dynamic games, the Nash equilibrium state trajectory of each agent is determined by its cost function and the information pattern of the game. However, the cost and trajectory of each agent may be unavailable to the other agents. Prior work on using partial observations to infer the costs in dynamic games assumes an open-loop information pattern. In this work, we demonstrate that the feedback Nash equilibrium concept is more expressive and encodes more complex behavior. It is desirable to develop specific tools for inferring players' objectives in feedback games. Therefore, we consider the dynamic game cost inference problem under the feedback information pattern, using only partial state observations and incomplete trajectory data. To this end, we first propose an inverse feedback game loss function, whose minimizer yields a feedback Nash equilibrium state trajectory closest to the observation data. We characterize the landscape and differentiability of the loss function. Given the difficulty of obtaining the exact gradient, our main contribution is an efficient gradient approximator, which enables a novel inverse feedback game solver that minimizes the loss using first-order optimization. In thorough empirical evaluations, we demonstrate that our algorithm converges reliably and has better robustness and generalization performance than the open-loop baseline method when the observation data reflects a group of players acting in a feedback Nash game.