 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGAIA-1: A Generative World Model for Autonomous Driving
Sep 29, 2023Autonomous driving promises transformative improvements to transportation, but building systems capable of safely navigating the unstructured complexity of real-world scenarios remains challenging. A critical problem lies in effectively predicting the various potential outcomes that may emerge in response to the vehicle's actions as the world evolves. To address this challenge, we introduce GAIA-1 ('Generative AI for Autonomy'), a generative world model that leverages video, text, and action inputs to generate realistic driving scenarios while offering fine-grained control over ego-vehicle behavior and scene features. Our approach casts world modeling as an unsupervised sequence modeling problem by mapping the inputs to discrete tokens, and predicting the next token in the sequence. Emerging properties from our model include learning high-level structures and scene dynamics, contextual awareness, generalization, and understanding of geometry. The power of GAIA-1's learned representation that captures expectations of future events, combined with its ability to generate realistic samples, provides new possibilities for innovation in the field of autonomy, enabling enhanced and accelerated training of autonomous driving technology.
Linking vision and motion for self-supervised object-centric perception
Jul 14, 2023Object-centric representations enable autonomous driving algorithms to reason about interactions between many independent agents and scene features. Traditionally these representations have been obtained via supervised learning, but this decouples perception from the downstream driving task and could harm generalization. In this work we adapt a self-supervised object-centric vision model to perform object decomposition using only RGB video and the pose of the vehicle as inputs. We demonstrate that our method obtains promising results on the Waymo Open perception dataset. While object mask quality lags behind supervised methods or alternatives that use more privileged information, we find that our model is capable of learning a representation that fuses multiple camera viewpoints over time and successfully tracks many vehicles and pedestrians in the dataset. Code for our model is available at https://github.com/wayveai/SOCS.
Model-Based Imitation Learning for Urban Driving
Oct 14, 2022
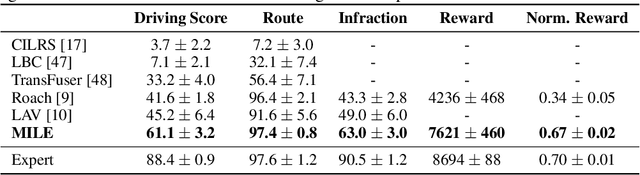
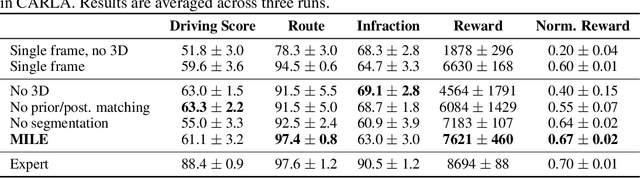
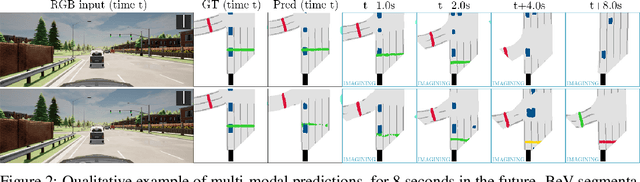
An accurate model of the environment and the dynamic agents acting in it offers great potential for improving motion planning. We present MILE: a Model-based Imitation LEarning approach to jointly learn a model of the world and a policy for autonomous driving. Our method leverages 3D geometry as an inductive bias and learns a highly compact latent space directly from high-resolution videos of expert demonstrations. Our model is trained on an offline corpus of urban driving data, without any online interaction with the environment. MILE improves upon prior state-of-the-art by 35% in driving score on the CARLA simulator when deployed in a completely new town and new weather conditions. Our model can predict diverse and plausible states and actions, that can be interpretably decoded to bird's-eye view semantic segmentation. Further, we demonstrate that it can execute complex driving manoeuvres from plans entirely predicted in imagination. Our approach is the first camera-only method that models static scene, dynamic scene, and ego-behaviour in an urban driving environment. The code and model weights are available at https://github.com/wayveai/mile.
FIERY: Future Instance Prediction in Bird's-Eye View from Surround Monocular Cameras
Apr 21, 2021
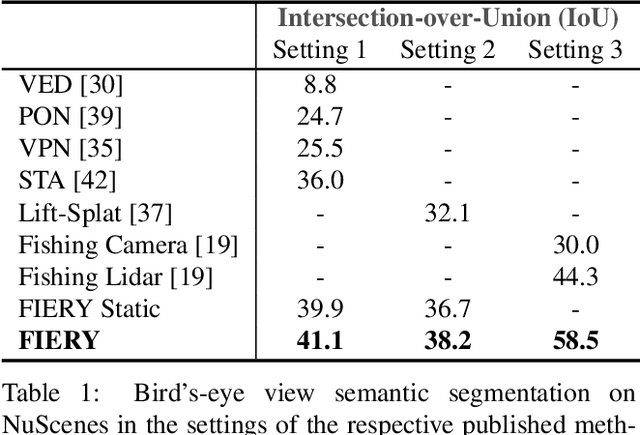
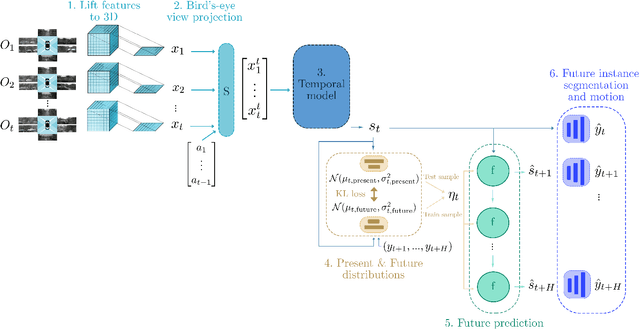
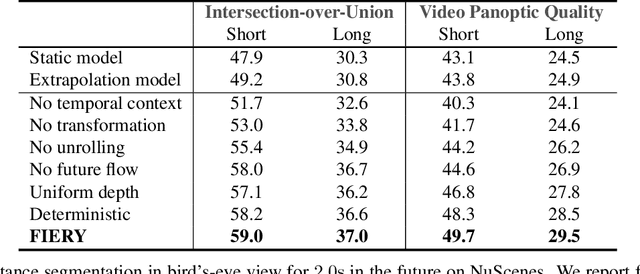
Driving requires interacting with road agents and predicting their future behaviour in order to navigate safely. We present FIERY: a probabilistic future prediction model in bird's-eye view from monocular cameras. Our model predicts future instance segmentation and motion of dynamic agents that can be transformed into non-parametric future trajectories. Our approach combines the perception, sensor fusion and prediction components of a traditional autonomous driving stack by estimating bird's-eye-view prediction directly from surround RGB monocular camera inputs. FIERY learns to model the inherent stochastic nature of the future directly from camera driving data in an end-to-end manner, without relying on HD maps, and predicts multimodal future trajectories. We show that our model outperforms previous prediction baselines on the NuScenes and Lyft datasets. Code is available at https://github.com/wayveai/fiery
Atlas: End-to-End 3D Scene Reconstruction from Posed Images
Mar 23, 2020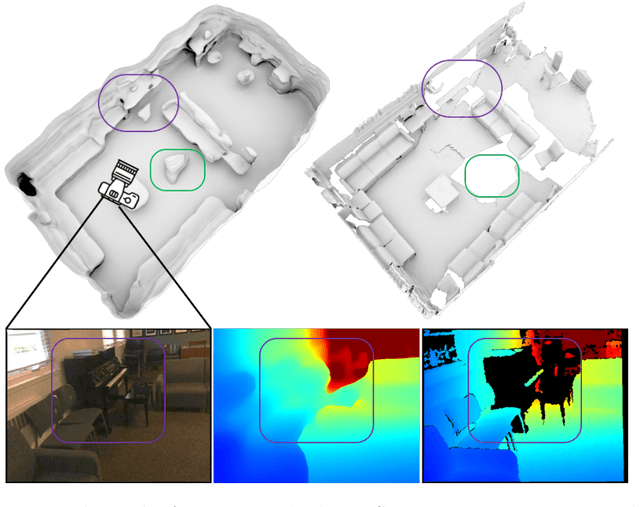
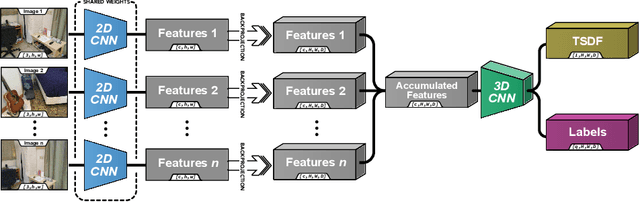
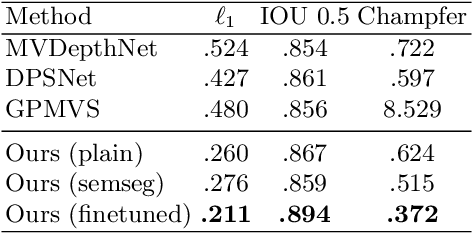
We present an end-to-end 3D reconstruction method for a scene by directly regressing a truncated signed distance function (TSDF) from a set of posed RGB images. Traditional approaches to 3D reconstruction rely on an intermediate representation of depth maps prior to estimating a full 3D model of a scene. We hypothesize that a direct regression to 3D is more effective. A 2D CNN extracts features from each image independently which are then back-projected and accumulated into a voxel volume using the camera intrinsics and extrinsics. After accumulation, a 3D CNN refines the accumulated features and predicts the TSDF values. Additionally, semantic segmentation of the 3D model is obtained without significant computation. This approach is evaluated on the Scannet dataset where we significantly outperform state-of-the-art baselines (deep multiview stereo followed by traditional TSDF fusion) both quantitatively and qualitatively. We compare our 3D semantic segmentation to prior methods that use a depth sensor since no previous work attempts the problem with only RGB input.
Depth Estimation by Learning Triangulation and Densification of Sparse Points for Multi-view Stereo
Mar 19, 2020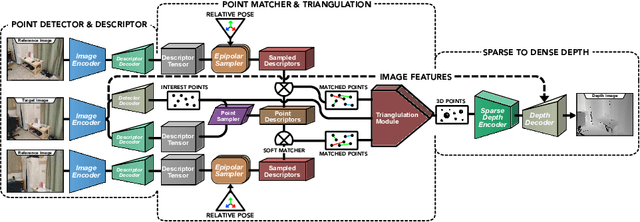
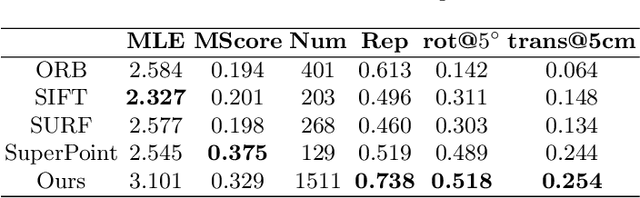
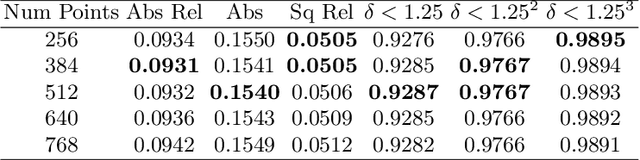

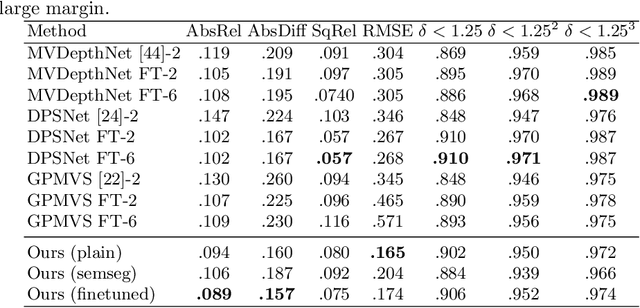
Multi-view stereo (MVS) is the golden mean between the accuracy of active depth sensing and the practicality of monocular depth estimation. Cost volume based approaches employing 3D convolutional neural networks (CNNs) have considerably improved the accuracy of MVS systems. However, this accuracy comes at a high computational cost which impedes practical adoption. Distinct from cost volume approaches, we propose an efficient depth estimation approach by first (a) detecting and evaluating descriptors for interest points, then (b) learning to match and triangulate a small set of interest points, and finally (c) densifying this sparse set of 3D points using CNNs. An end-to-end network efficiently performs all three steps within a deep learning framework and trained with intermediate 2D image and 3D geometric supervision, along with depth supervision. Crucially, our first step complements pose estimation using interest point detection and descriptor learning. We demonstrate that state-of-the-art results on depth estimation with lower compute for different scene lengths. Furthermore, our method generalizes to newer environments and the descriptors output by our network compare favorably to strong baselines.
Zero-Shot Image Classification Using Coupled Dictionary Embedding
Jun 10, 2019
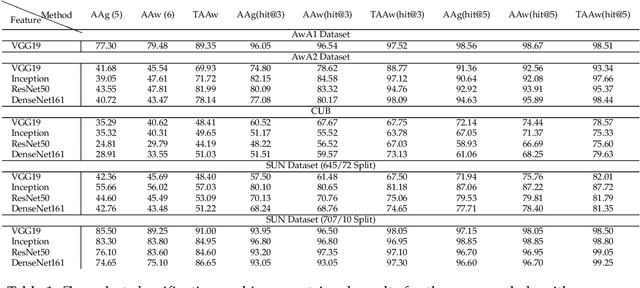
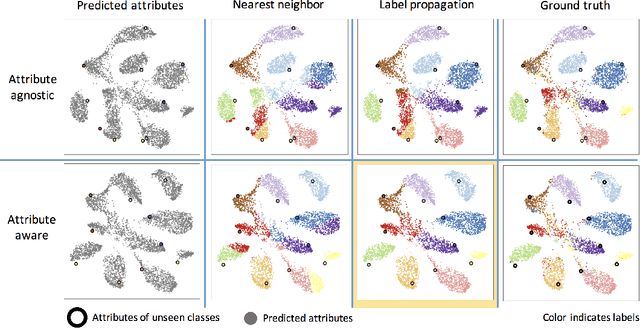
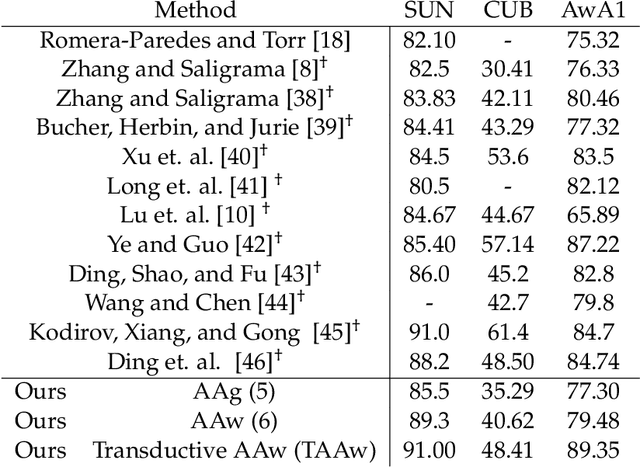
Zero-shot learning (ZSL) is a framework to classify images belonging to unseen classes based on solely semantic information about these unseen classes. In this paper, we propose a new ZSL algorithm using coupled dictionary learning. The core idea is that the visual features and the semantic attributes of an image can share the same sparse representation in an intermediate space. We use images from seen classes and semantic attributes from seen and unseen classes to learn two dictionaries that can represent sparsely the visual and semantic feature vectors of an image. In the ZSL testing stage and in the absence of labeled data, images from unseen classes can be mapped into the attribute space by finding the joint sparse representation using solely the visual data. The image is then classified in the attribute space given semantic descriptions of unseen classes. We also provide an attribute-aware formulation to tackle domain shift and hubness problems in ZSL. Extensive experiments are provided to demonstrate the superior performance of our approach against the state of the art ZSL algorithms on benchmark ZSL datasets.
Image to Image Translation for Domain Adaptation
Dec 01, 2017

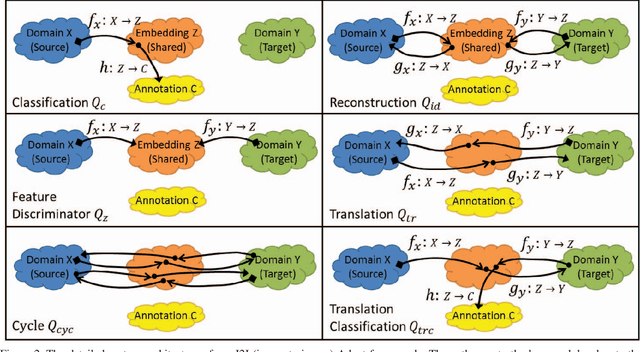
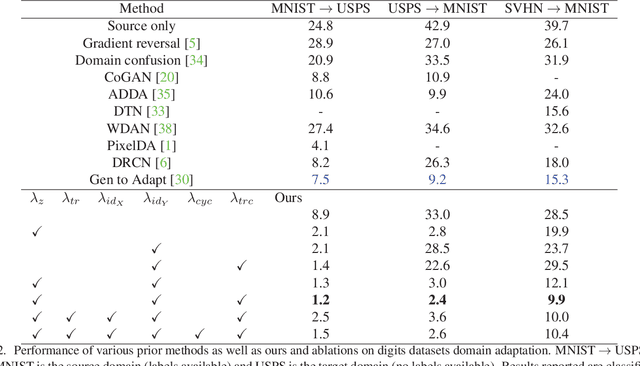
We propose a general framework for unsupervised domain adaptation, which allows deep neural networks trained on a source domain to be tested on a different target domain without requiring any training annotations in the target domain. This is achieved by adding extra networks and losses that help regularize the features extracted by the backbone encoder network. To this end we propose the novel use of the recently proposed unpaired image-toimage translation framework to constrain the features extracted by the encoder network. Specifically, we require that the features extracted are able to reconstruct the images in both domains. In addition we require that the distribution of features extracted from images in the two domains are indistinguishable. Many recent works can be seen as specific cases of our general framework. We apply our method for domain adaptation between MNIST, USPS, and SVHN datasets, and Amazon, Webcam and DSLR Office datasets in classification tasks, and also between GTA5 and Cityscapes datasets for a segmentation task. We demonstrate state of the art performance on each of these datasets.