 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWayveScenes101: A Dataset and Benchmark for Novel View Synthesis in Autonomous Driving
Jul 11, 2024



We present WayveScenes101, a dataset designed to help the community advance the state of the art in novel view synthesis that focuses on challenging driving scenes containing many dynamic and deformable elements with changing geometry and texture. The dataset comprises 101 driving scenes across a wide range of environmental conditions and driving scenarios. The dataset is designed for benchmarking reconstructions on in-the-wild driving scenes, with many inherent challenges for scene reconstruction methods including image glare, rapid exposure changes, and highly dynamic scenes with significant occlusion. Along with the raw images, we include COLMAP-derived camera poses in standard data formats. We propose an evaluation protocol for evaluating models on held-out camera views that are off-axis from the training views, specifically testing the generalisation capabilities of methods. Finally, we provide detailed metadata for all scenes, including weather, time of day, and traffic conditions, to allow for a detailed model performance breakdown across scene characteristics. Dataset and code are available at https://github.com/wayveai/wayve_scenes.
FIERY: Future Instance Prediction in Bird's-Eye View from Surround Monocular Cameras
Apr 21, 2021
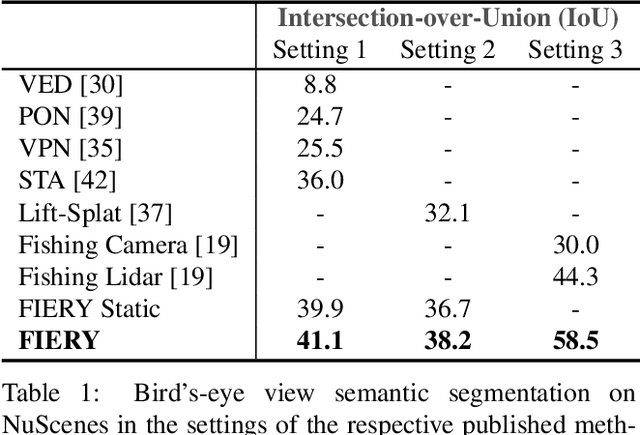
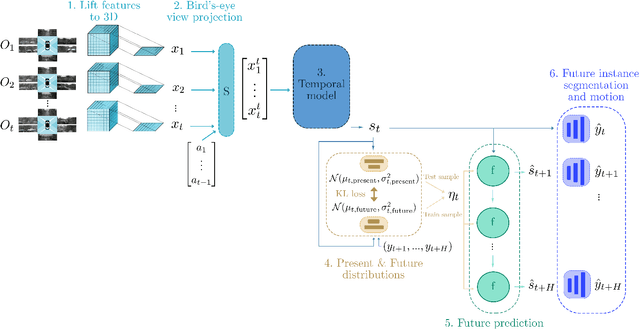
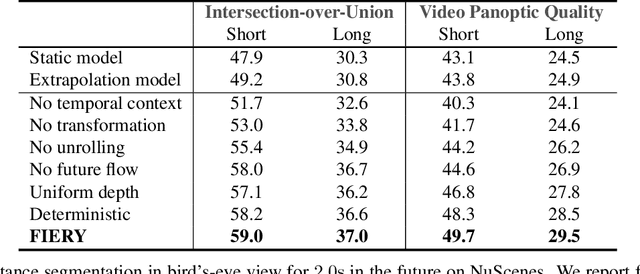
Driving requires interacting with road agents and predicting their future behaviour in order to navigate safely. We present FIERY: a probabilistic future prediction model in bird's-eye view from monocular cameras. Our model predicts future instance segmentation and motion of dynamic agents that can be transformed into non-parametric future trajectories. Our approach combines the perception, sensor fusion and prediction components of a traditional autonomous driving stack by estimating bird's-eye-view prediction directly from surround RGB monocular camera inputs. FIERY learns to model the inherent stochastic nature of the future directly from camera driving data in an end-to-end manner, without relying on HD maps, and predicts multimodal future trajectories. We show that our model outperforms previous prediction baselines on the NuScenes and Lyft datasets. Code is available at https://github.com/wayveai/fiery
Probabilistic Future Prediction for Video Scene Understanding
Mar 13, 2020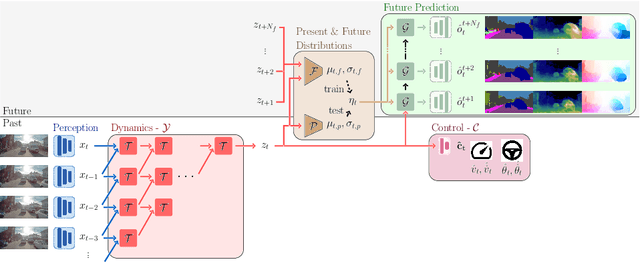
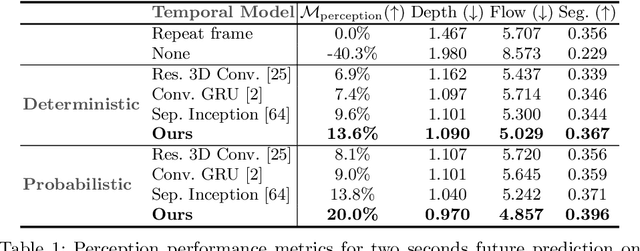

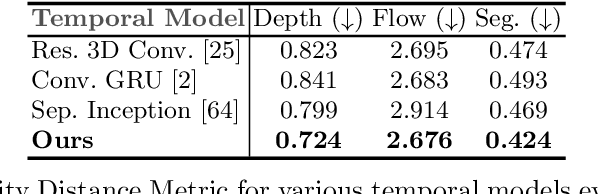
We present a novel deep learning architecture for probabilistic future prediction from video. We predict the future semantics, geometry and motion of complex real-world urban scenes and use this representation to control an autonomous vehicle. This work is the first to jointly predict ego-motion, static scene, and the motion of dynamic agents in a probabilistic manner, which allows sampling consistent, highly probable futures from a compact latent space. Our model learns a representation from RGB video with a spatio-temporal convolutional module. The learned representation can be explicitly decoded to future semantic segmentation, depth, and optical flow, in addition to being an input to a learnt driving policy. To model the stochasticity of the future, we introduce a conditional variational approach which minimises the divergence between the present distribution (what could happen given what we have seen) and the future distribution (what we observe actually happens). During inference, diverse futures are generated by sampling from the present distribution.