 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLingoQA: Video Question Answering for Autonomous Driving
Dec 21, 2023Autonomous driving has long faced a challenge with public acceptance due to the lack of explainability in the decision-making process. Video question-answering (QA) in natural language provides the opportunity for bridging this gap. Nonetheless, evaluating the performance of Video QA models has proved particularly tough due to the absence of comprehensive benchmarks. To fill this gap, we introduce LingoQA, a benchmark specifically for autonomous driving Video QA. The LingoQA trainable metric demonstrates a 0.95 Spearman correlation coefficient with human evaluations. We introduce a Video QA dataset of central London consisting of 419k samples that we release with the paper. We establish a baseline vision-language model and run extensive ablation studies to understand its performance.
GAIA-1: A Generative World Model for Autonomous Driving
Sep 29, 2023Autonomous driving promises transformative improvements to transportation, but building systems capable of safely navigating the unstructured complexity of real-world scenarios remains challenging. A critical problem lies in effectively predicting the various potential outcomes that may emerge in response to the vehicle's actions as the world evolves. To address this challenge, we introduce GAIA-1 ('Generative AI for Autonomy'), a generative world model that leverages video, text, and action inputs to generate realistic driving scenarios while offering fine-grained control over ego-vehicle behavior and scene features. Our approach casts world modeling as an unsupervised sequence modeling problem by mapping the inputs to discrete tokens, and predicting the next token in the sequence. Emerging properties from our model include learning high-level structures and scene dynamics, contextual awareness, generalization, and understanding of geometry. The power of GAIA-1's learned representation that captures expectations of future events, combined with its ability to generate realistic samples, provides new possibilities for innovation in the field of autonomy, enabling enhanced and accelerated training of autonomous driving technology.
Linking vision and motion for self-supervised object-centric perception
Jul 14, 2023Object-centric representations enable autonomous driving algorithms to reason about interactions between many independent agents and scene features. Traditionally these representations have been obtained via supervised learning, but this decouples perception from the downstream driving task and could harm generalization. In this work we adapt a self-supervised object-centric vision model to perform object decomposition using only RGB video and the pose of the vehicle as inputs. We demonstrate that our method obtains promising results on the Waymo Open perception dataset. While object mask quality lags behind supervised methods or alternatives that use more privileged information, we find that our model is capable of learning a representation that fuses multiple camera viewpoints over time and successfully tracks many vehicles and pedestrians in the dataset. Code for our model is available at https://github.com/wayveai/SOCS.
Model-Based Imitation Learning for Urban Driving
Oct 14, 2022
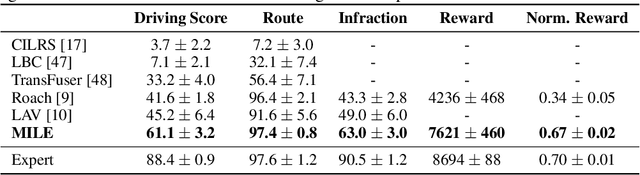
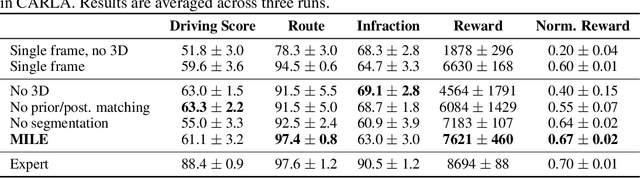
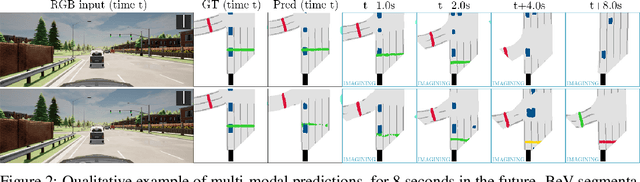
An accurate model of the environment and the dynamic agents acting in it offers great potential for improving motion planning. We present MILE: a Model-based Imitation LEarning approach to jointly learn a model of the world and a policy for autonomous driving. Our method leverages 3D geometry as an inductive bias and learns a highly compact latent space directly from high-resolution videos of expert demonstrations. Our model is trained on an offline corpus of urban driving data, without any online interaction with the environment. MILE improves upon prior state-of-the-art by 35% in driving score on the CARLA simulator when deployed in a completely new town and new weather conditions. Our model can predict diverse and plausible states and actions, that can be interpretably decoded to bird's-eye view semantic segmentation. Further, we demonstrate that it can execute complex driving manoeuvres from plans entirely predicted in imagination. Our approach is the first camera-only method that models static scene, dynamic scene, and ego-behaviour in an urban driving environment. The code and model weights are available at https://github.com/wayveai/mile.
Reimagining an autonomous vehicle
Aug 12, 2021
The self driving challenge in 2021 is this century's technological equivalent of the space race, and is now entering the second major decade of development. Solving the technology will create social change which parallels the invention of the automobile itself. Today's autonomous driving technology is laudable, though rooted in decisions made a decade ago. We argue that a rethink is required, reconsidering the autonomous vehicle (AV) problem in the light of the body of knowledge that has been gained since the DARPA challenges which seeded the industry. What does AV2.0 look like? We present an alternative vision: a recipe for driving with machine learning, and grand challenges for research in driving.
Video Class Agnostic Segmentation with Contrastive Learning for Autonomous Driving
May 11, 2021
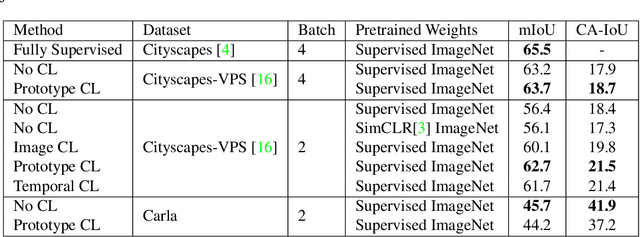


Semantic segmentation in autonomous driving predominantly focuses on learning from large-scale data with a closed set of known classes without considering unknown objects. Motivated by safety reasons, we address the video class agnostic segmentation task, which considers unknown objects outside the closed set of known classes in our training data. We propose a novel auxiliary contrastive loss to learn the segmentation of known classes and unknown objects. Unlike previous work in contrastive learning that samples the anchor, positive and negative examples on an image level, our contrastive learning method leverages pixel-wise semantic and temporal guidance. We conduct experiments on Cityscapes-VPS by withholding four classes from training and show an improvement gain for both known and unknown objects segmentation with the auxiliary contrastive loss. We further release a large-scale synthetic dataset for different autonomous driving scenarios that includes distinct and rare unknown objects. We conduct experiments on the full synthetic dataset and a reduced small-scale version, and show how contrastive learning is more effective in small scale datasets. Our proposed models, dataset, and code will be released at https://github.com/MSiam/video_class_agnostic_segmentation.
FIERY: Future Instance Prediction in Bird's-Eye View from Surround Monocular Cameras
Apr 21, 2021
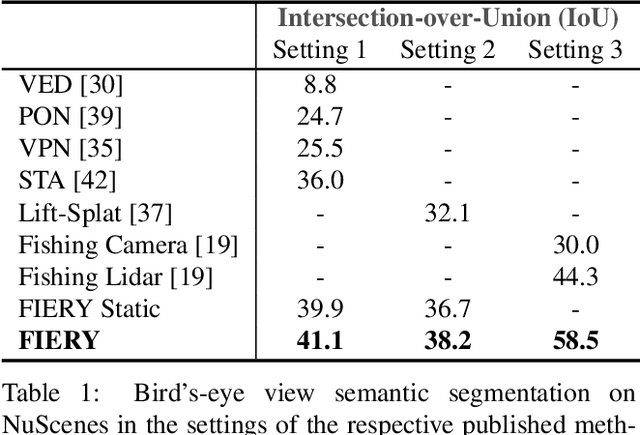
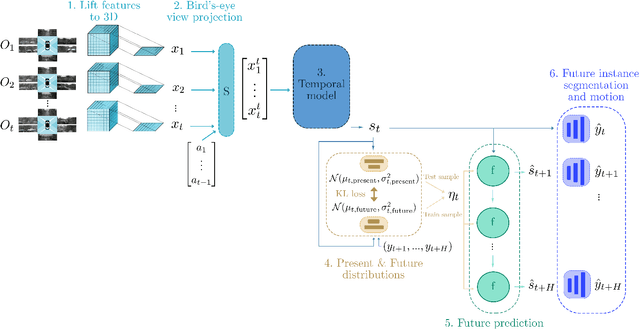
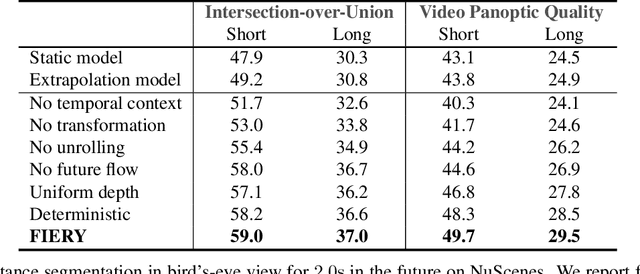
Driving requires interacting with road agents and predicting their future behaviour in order to navigate safely. We present FIERY: a probabilistic future prediction model in bird's-eye view from monocular cameras. Our model predicts future instance segmentation and motion of dynamic agents that can be transformed into non-parametric future trajectories. Our approach combines the perception, sensor fusion and prediction components of a traditional autonomous driving stack by estimating bird's-eye-view prediction directly from surround RGB monocular camera inputs. FIERY learns to model the inherent stochastic nature of the future directly from camera driving data in an end-to-end manner, without relying on HD maps, and predicts multimodal future trajectories. We show that our model outperforms previous prediction baselines on the NuScenes and Lyft datasets. Code is available at https://github.com/wayveai/fiery
Video Class Agnostic Segmentation Benchmark for Autonomous Driving
Mar 19, 2021
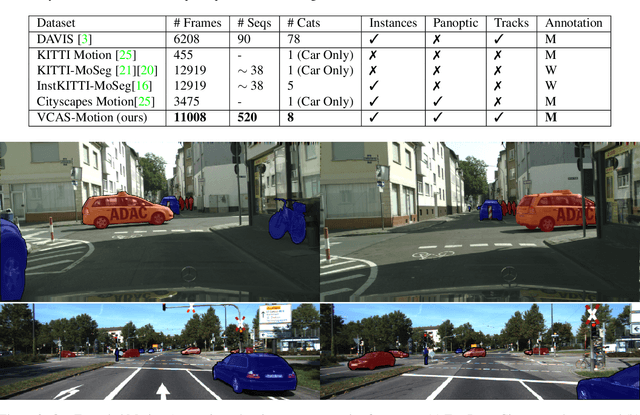


Semantic segmentation approaches are typically trained on large-scale data with a closed finite set of known classes without considering unknown objects. In certain safety-critical robotics applications, especially autonomous driving, it is important to segment all objects, including those unknown at training time. We formalize the task of video class agnostic segmentation from monocular video sequences in autonomous driving to account for unknown objects. Video class agnostic segmentation can be formulated as an open-set or a motion segmentation problem. We discuss both formulations and provide datasets and benchmark different baseline approaches for both tracks. In the motion-segmentation track we benchmark real-time joint panoptic and motion instance segmentation, and evaluate the effect of ego-flow suppression. In the open-set segmentation track we evaluate baseline methods that combine appearance, and geometry to learn prototypes per semantic class. We then compare it to a model that uses an auxiliary contrastive loss to improve the discrimination between known and unknown objects. All datasets and models are publicly released at https://msiam.github.io/vca/.
Probabilistic Future Prediction for Video Scene Understanding
Mar 13, 2020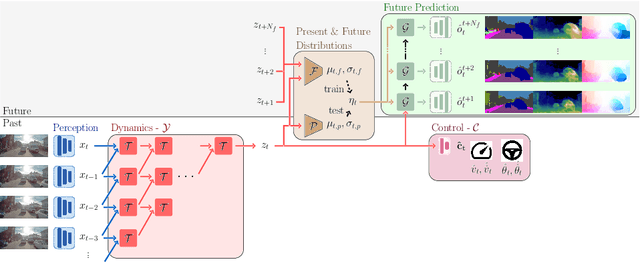
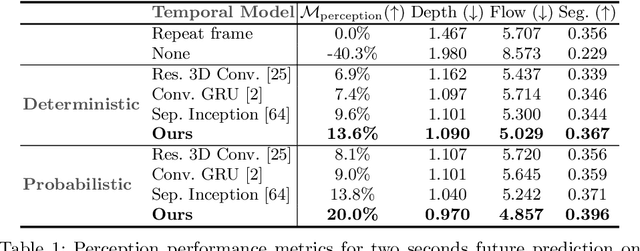

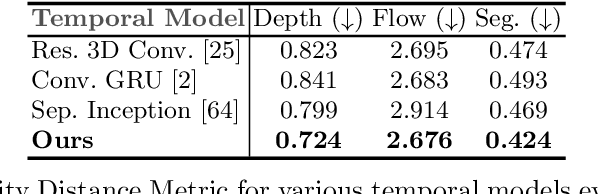
We present a novel deep learning architecture for probabilistic future prediction from video. We predict the future semantics, geometry and motion of complex real-world urban scenes and use this representation to control an autonomous vehicle. This work is the first to jointly predict ego-motion, static scene, and the motion of dynamic agents in a probabilistic manner, which allows sampling consistent, highly probable futures from a compact latent space. Our model learns a representation from RGB video with a spatio-temporal convolutional module. The learned representation can be explicitly decoded to future semantic segmentation, depth, and optical flow, in addition to being an input to a learnt driving policy. To model the stochasticity of the future, we introduce a conditional variational approach which minimises the divergence between the present distribution (what could happen given what we have seen) and the future distribution (what we observe actually happens). During inference, diverse futures are generated by sampling from the present distribution.
Learning a Spatio-Temporal Embedding for Video Instance Segmentation
Dec 19, 2019

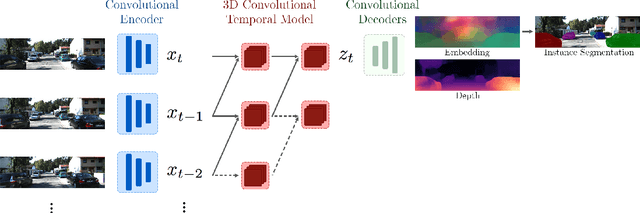

We present a novel embedding approach for video instance segmentation. Our method learns a spatio-temporal embedding integrating cues from appearance, motion, and geometry; a 3D causal convolutional network models motion, and a monocular self-supervised depth loss models geometry. In this embedding space, video-pixels of the same instance are clustered together while being separated from other instances, to naturally track instances over time without any complex post-processing. Our network runs in real-time as our architecture is entirely causal - we do not incorporate information from future frames, contrary to previous methods. We show that our model can accurately track and segment instances, even with occlusions and missed detections, advancing the state-of-the-art on the KITTI Multi-Object and Tracking Dataset.