 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLingoQA: Video Question Answering for Autonomous Driving
Dec 21, 2023Autonomous driving has long faced a challenge with public acceptance due to the lack of explainability in the decision-making process. Video question-answering (QA) in natural language provides the opportunity for bridging this gap. Nonetheless, evaluating the performance of Video QA models has proved particularly tough due to the absence of comprehensive benchmarks. To fill this gap, we introduce LingoQA, a benchmark specifically for autonomous driving Video QA. The LingoQA trainable metric demonstrates a 0.95 Spearman correlation coefficient with human evaluations. We introduce a Video QA dataset of central London consisting of 419k samples that we release with the paper. We establish a baseline vision-language model and run extensive ablation studies to understand its performance.
PixTrack: Precise 6DoF Object Pose Tracking using NeRF Templates and Feature-metric Alignment
Sep 08, 2022We present PixTrack, a vision based object pose tracking framework using novel view synthesis and deep feature-metric alignment. Our evaluations demonstrate that our method produces highly accurate, robust, and jitter-free 6DoF pose estimates of objects in RGB images without the need of any data annotation or trajectory smoothing. Our method is also computationally efficient making it easy to have multi-object tracking with no alteration to our method and just using CPU multiprocessing.
Efficient 2.5D Hand Pose Estimation via Auxiliary Multi-Task Training for Embedded Devices
Sep 12, 2019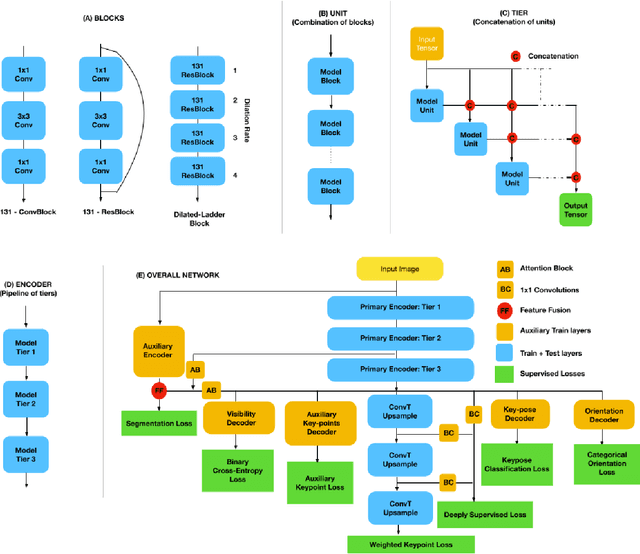
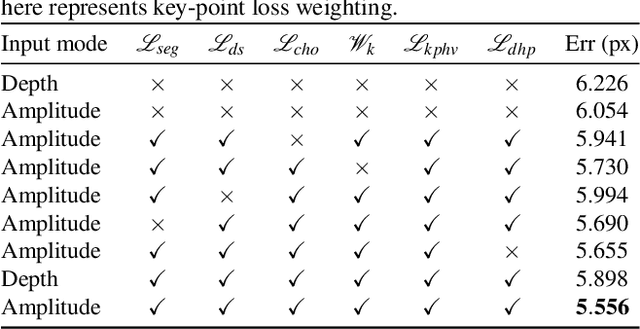

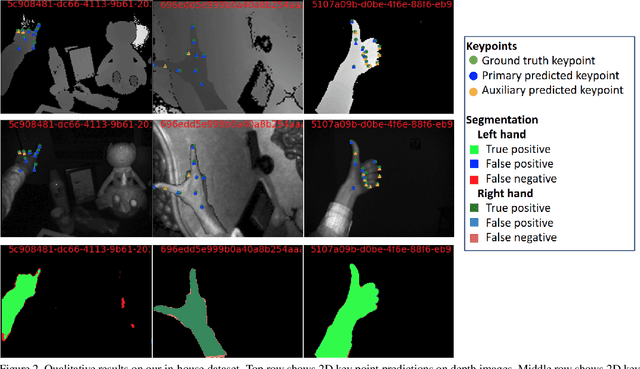
2D Key-point estimation is an important precursor to 3D pose estimation problems for human body and hands. In this work, we discuss the data, architecture, and training procedure necessary to deploy extremely efficient 2.5D hand pose estimation on embedded devices with highly constrained memory and compute envelope, such as AR/VR wearables. Our 2.5D hand pose estimation consists of 2D key-point estimation of joint positions on an egocentric image, captured by a depth sensor, and lifted to 2.5D using the corresponding depth values. Our contributions are two fold: (a) We discuss data labeling and augmentation strategies, the modules in the network architecture that collectively lead to $3\%$ the flop count and $2\%$ the number of parameters when compared to the state of the art MobileNetV2 architecture. (b) We propose an auxiliary multi-task training strategy needed to compensate for the small capacity of the network while achieving comparable performance to MobileNetV2. Our 32-bit trained model has a memory footprint of less than 300 Kilobytes, operates at more than 50 Hz with less than 35 MFLOPs.