 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCarLLaVA: Vision language models for camera-only closed-loop driving
Jun 14, 2024



In this technical report, we present CarLLaVA, a Vision Language Model (VLM) for autonomous driving, developed for the CARLA Autonomous Driving Challenge 2.0. CarLLaVA uses the vision encoder of the LLaVA VLM and the LLaMA architecture as backbone, achieving state-of-the-art closed-loop driving performance with only camera input and without the need for complex or expensive labels. Additionally, we show preliminary results on predicting language commentary alongside the driving output. CarLLaVA uses a semi-disentangled output representation of both path predictions and waypoints, getting the advantages of the path for better lateral control and the waypoints for better longitudinal control. We propose an efficient training recipe to train on large driving datasets without wasting compute on easy, trivial data. CarLLaVA ranks 1st place in the sensor track of the CARLA Autonomous Driving Challenge 2.0 outperforming the previous state of the art by 458% and the best concurrent submission by 32.6%.
LingoQA: Video Question Answering for Autonomous Driving
Dec 21, 2023Autonomous driving has long faced a challenge with public acceptance due to the lack of explainability in the decision-making process. Video question-answering (QA) in natural language provides the opportunity for bridging this gap. Nonetheless, evaluating the performance of Video QA models has proved particularly tough due to the absence of comprehensive benchmarks. To fill this gap, we introduce LingoQA, a benchmark specifically for autonomous driving Video QA. The LingoQA trainable metric demonstrates a 0.95 Spearman correlation coefficient with human evaluations. We introduce a Video QA dataset of central London consisting of 419k samples that we release with the paper. We establish a baseline vision-language model and run extensive ablation studies to understand its performance.
Driving with LLMs: Fusing Object-Level Vector Modality for Explainable Autonomous Driving
Oct 13, 2023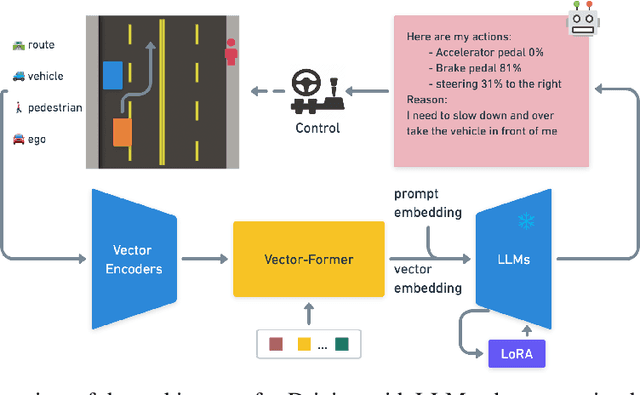
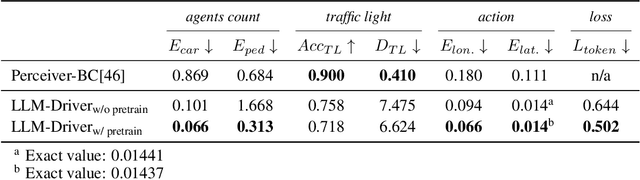
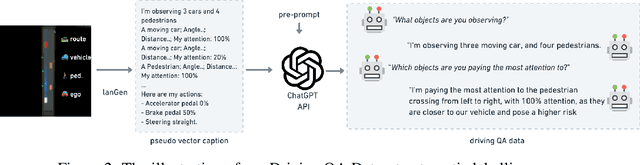

Large Language Models (LLMs) have shown promise in the autonomous driving sector, particularly in generalization and interpretability. We introduce a unique object-level multimodal LLM architecture that merges vectorized numeric modalities with a pre-trained LLM to improve context understanding in driving situations. We also present a new dataset of 160k QA pairs derived from 10k driving scenarios, paired with high quality control commands collected with RL agent and question answer pairs generated by teacher LLM (GPT-3.5). A distinct pretraining strategy is devised to align numeric vector modalities with static LLM representations using vector captioning language data. We also introduce an evaluation metric for Driving QA and demonstrate our LLM-driver's proficiency in interpreting driving scenarios, answering questions, and decision-making. Our findings highlight the potential of LLM-based driving action generation in comparison to traditional behavioral cloning. We make our benchmark, datasets, and model available for further exploration.