 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePlanT 2.0: Exposing Biases and Structural Flaws in Closed-Loop Driving
Nov 10, 2025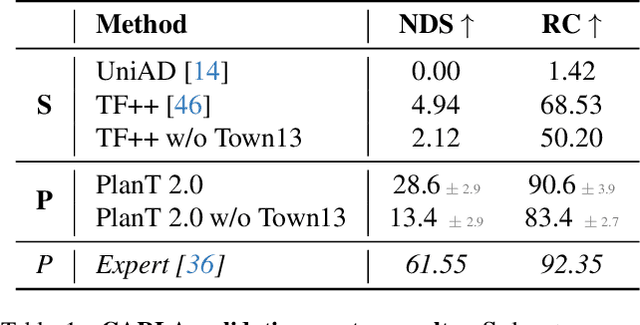



Most recent work in autonomous driving has prioritized benchmark performance and methodological innovation over in-depth analysis of model failures, biases, and shortcut learning. This has led to incremental improvements without a deep understanding of the current failures. While it is straightforward to look at situations where the model fails, it is hard to understand the underlying reason. This motivates us to conduct a systematic study, where inputs to the model are perturbed and the predictions observed. We introduce PlanT 2.0, a lightweight, object-centric planning transformer designed for autonomous driving research in CARLA. The object-level representation enables controlled analysis, as the input can be easily perturbed (e.g., by changing the location or adding or removing certain objects), in contrast to sensor-based models. To tackle the scenarios newly introduced by the challenging CARLA Leaderboard 2.0, we introduce multiple upgrades to PlanT, achieving state-of-the-art performance on Longest6 v2, Bench2Drive, and the CARLA validation routes. Our analysis exposes insightful failures, such as a lack of scene understanding caused by low obstacle diversity, rigid expert behaviors leading to exploitable shortcuts, and overfitting to a fixed set of expert trajectories. Based on these findings, we argue for a shift toward data-centric development, with a focus on richer, more robust, and less biased datasets. We open-source our code and model at https://github.com/autonomousvision/plant2.
MDPO: Overcoming the Training-Inference Divide of Masked Diffusion Language Models
Aug 18, 2025Diffusion language models, as a promising alternative to traditional autoregressive (AR) models, enable faster generation and richer conditioning on bidirectional context. However, they suffer from a key discrepancy between training and inference: during inference, MDLMs progressively reveal the structure of the generated sequence by producing fewer and fewer masked tokens, whereas this structure is ignored in training as tokens are masked at random. Although this discrepancy between training and inference can lead to suboptimal performance, it has been largely overlooked by previous works, leaving closing this gap between the two stages an open problem. To address this, we frame the problem of learning effective denoising trajectories as a sequential decision-making problem and use the resulting framework to apply reinforcement learning. We propose a novel Masked Diffusion Policy Optimization (MDPO) to exploit the Markov property diffusion possesses and explicitly train the model under the same progressive refining schedule used at inference. MDPO matches the performance of the previous state-of-the-art (SOTA) method with 60x fewer gradient updates, while achieving average improvements of 9.6% on MATH500 and 54.2% on Countdown over SOTA when trained within the same number of weight updates. Additionally, we improve the remasking strategy of MDLMs as a plug-in inference replacement to overcome the limitation that the model cannot refine tokens flexibly. This simple yet effective training-free strategy, what we refer to as RCR, consistently improves performance and yields additional gains when combined with MDPO. Our findings establish great potential for investigating the discrepancy between pre-training and inference of MDLMs. Code: https://github.com/autonomousvision/mdpo. Project Page: https://cli212.github.io/MDPO/.
SimLingo: Vision-Only Closed-Loop Autonomous Driving with Language-Action Alignment
Mar 12, 2025

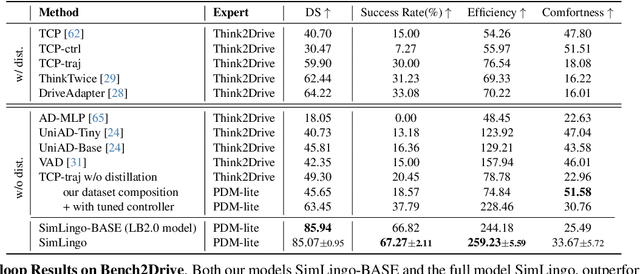

Integrating large language models (LLMs) into autonomous driving has attracted significant attention with the hope of improving generalization and explainability. However, existing methods often focus on either driving or vision-language understanding but achieving both high driving performance and extensive language understanding remains challenging. In addition, the dominant approach to tackle vision-language understanding is using visual question answering. However, for autonomous driving, this is only useful if it is aligned with the action space. Otherwise, the model's answers could be inconsistent with its behavior. Therefore, we propose a model that can handle three different tasks: (1) closed-loop driving, (2) vision-language understanding, and (3) language-action alignment. Our model SimLingo is based on a vision language model (VLM) and works using only camera, excluding expensive sensors like LiDAR. SimLingo obtains state-of-the-art performance on the widely used CARLA simulator on the Bench2Drive benchmark and is the winning entry at the CARLA challenge 2024. Additionally, we achieve strong results in a wide variety of language-related tasks while maintaining high driving performance.
CarLLaVA: Vision language models for camera-only closed-loop driving
Jun 14, 2024



In this technical report, we present CarLLaVA, a Vision Language Model (VLM) for autonomous driving, developed for the CARLA Autonomous Driving Challenge 2.0. CarLLaVA uses the vision encoder of the LLaVA VLM and the LLaMA architecture as backbone, achieving state-of-the-art closed-loop driving performance with only camera input and without the need for complex or expensive labels. Additionally, we show preliminary results on predicting language commentary alongside the driving output. CarLLaVA uses a semi-disentangled output representation of both path predictions and waypoints, getting the advantages of the path for better lateral control and the waypoints for better longitudinal control. We propose an efficient training recipe to train on large driving datasets without wasting compute on easy, trivial data. CarLLaVA ranks 1st place in the sensor track of the CARLA Autonomous Driving Challenge 2.0 outperforming the previous state of the art by 458% and the best concurrent submission by 32.6%.
Can Vehicle Motion Planning Generalize to Realistic Long-tail Scenarios?
Apr 11, 2024



Real-world autonomous driving systems must make safe decisions in the face of rare and diverse traffic scenarios. Current state-of-the-art planners are mostly evaluated on real-world datasets like nuScenes (open-loop) or nuPlan (closed-loop). In particular, nuPlan seems to be an expressive evaluation method since it is based on real-world data and closed-loop, yet it mostly covers basic driving scenarios. This makes it difficult to judge a planner's capabilities to generalize to rarely-seen situations. Therefore, we propose a novel closed-loop benchmark interPlan containing several edge cases and challenging driving scenarios. We assess existing state-of-the-art planners on our benchmark and show that neither rule-based nor learning-based planners can safely navigate the interPlan scenarios. A recently evolving direction is the usage of foundation models like large language models (LLM) to handle generalization. We evaluate an LLM-only planner and introduce a novel hybrid planner that combines an LLM-based behavior planner with a rule-based motion planner that achieves state-of-the-art performance on our benchmark.
DriveLM: Driving with Graph Visual Question Answering
Dec 21, 2023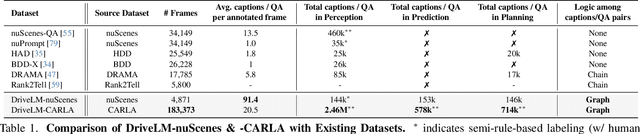
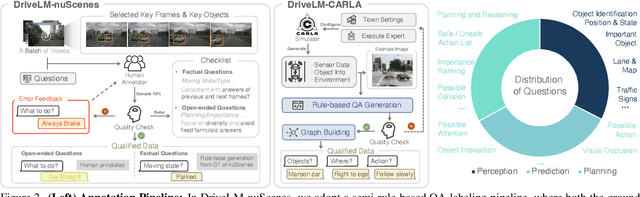
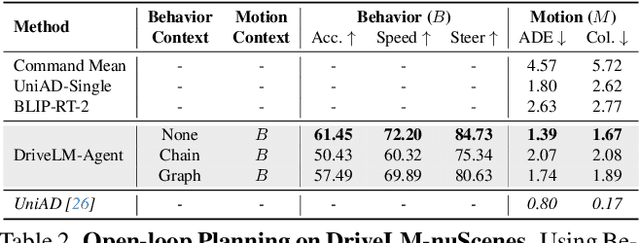
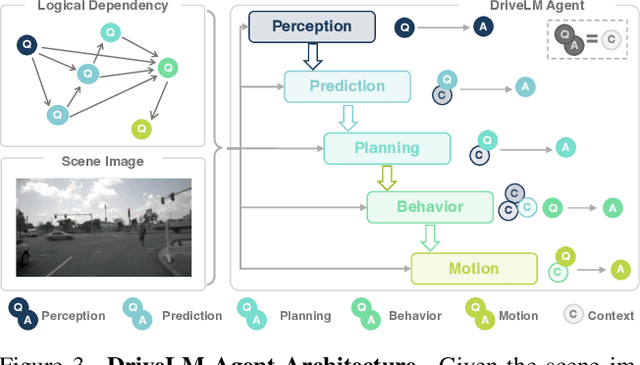
We study how vision-language models (VLMs) trained on web-scale data can be integrated into end-to-end driving systems to boost generalization and enable interactivity with human users. While recent approaches adapt VLMs to driving via single-round visual question answering (VQA), human drivers reason about decisions in multiple steps. Starting from the localization of key objects, humans estimate object interactions before taking actions. The key insight is that with our proposed task, Graph VQA, where we model graph-structured reasoning through perception, prediction and planning question-answer pairs, we obtain a suitable proxy task to mimic the human reasoning process. We instantiate datasets (DriveLM-Data) built upon nuScenes and CARLA, and propose a VLM-based baseline approach (DriveLM-Agent) for jointly performing Graph VQA and end-to-end driving. The experiments demonstrate that Graph VQA provides a simple, principled framework for reasoning about a driving scene, and DriveLM-Data provides a challenging benchmark for this task. Our DriveLM-Agent baseline performs end-to-end autonomous driving competitively in comparison to state-of-the-art driving-specific architectures. Notably, its benefits are pronounced when it is evaluated zero-shot on unseen objects or sensor configurations. We hope this work can be the starting point to shed new light on how to apply VLMs for autonomous driving. To facilitate future research, all code, data, and models are available to the public.
On Offline Evaluation of 3D Object Detection for Autonomous Driving
Aug 24, 2023


Prior work in 3D object detection evaluates models using offline metrics like average precision since closed-loop online evaluation on the downstream driving task is costly. However, it is unclear how indicative offline results are of driving performance. In this work, we perform the first empirical evaluation measuring how predictive different detection metrics are of driving performance when detectors are integrated into a full self-driving stack. We conduct extensive experiments on urban driving in the CARLA simulator using 16 object detection models. We find that the nuScenes Detection Score has a higher correlation to driving performance than the widely used average precision metric. In addition, our results call for caution on the exclusive reliance on the emerging class of `planner-centric' metrics.
PlanT: Explainable Planning Transformers via Object-Level Representations
Oct 25, 2022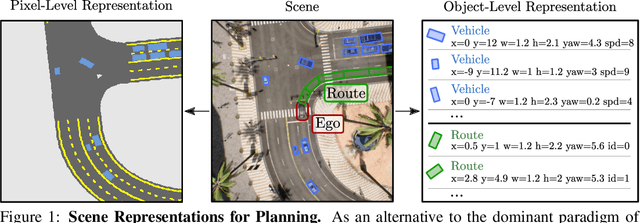

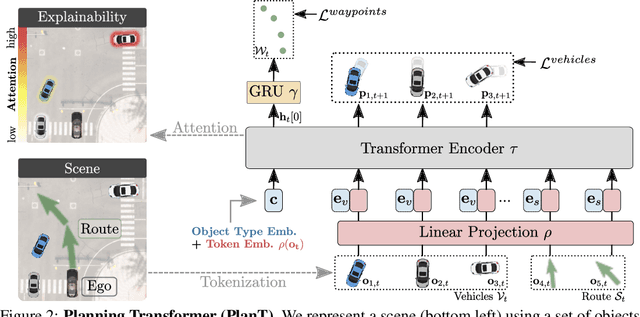
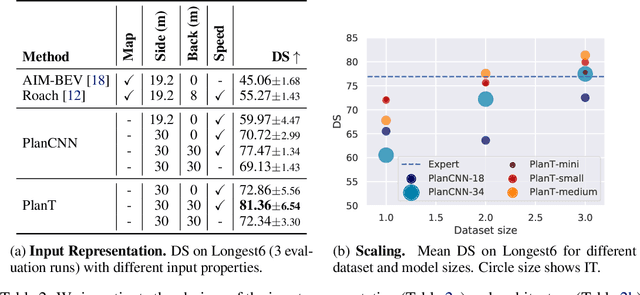
Planning an optimal route in a complex environment requires efficient reasoning about the surrounding scene. While human drivers prioritize important objects and ignore details not relevant to the decision, learning-based planners typically extract features from dense, high-dimensional grid representations containing all vehicle and road context information. In this paper, we propose PlanT, a novel approach for planning in the context of self-driving that uses a standard transformer architecture. PlanT is based on imitation learning with a compact object-level input representation. On the Longest6 benchmark for CARLA, PlanT outperforms all prior methods (matching the driving score of the expert) while being 5.3x faster than equivalent pixel-based planning baselines during inference. Combining PlanT with an off-the-shelf perception module provides a sensor-based driving system that is more than 10 points better in terms of driving score than the existing state of the art. Furthermore, we propose an evaluation protocol to quantify the ability of planners to identify relevant objects, providing insights regarding their decision-making. Our results indicate that PlanT can focus on the most relevant object in the scene, even when this object is geometrically distant.
TransFuser: Imitation with Transformer-Based Sensor Fusion for Autonomous Driving
May 31, 2022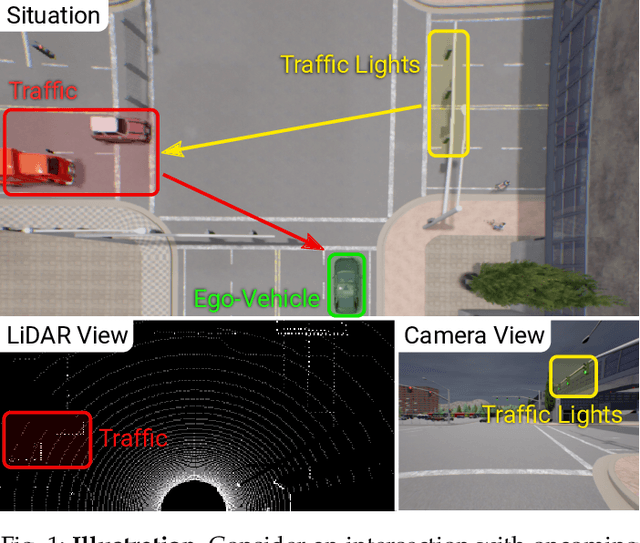
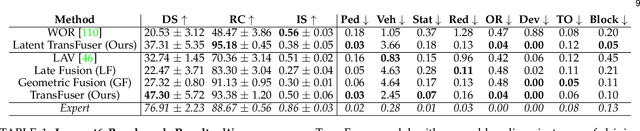
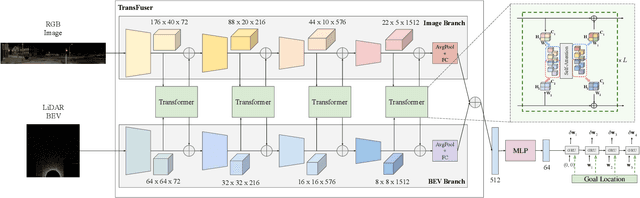
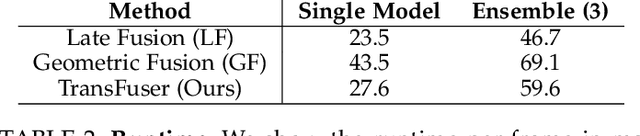
How should we integrate representations from complementary sensors for autonomous driving? Geometry-based fusion has shown promise for perception (e.g. object detection, motion forecasting). However, in the context of end-to-end driving, we find that imitation learning based on existing sensor fusion methods underperforms in complex driving scenarios with a high density of dynamic agents. Therefore, we propose TransFuser, a mechanism to integrate image and LiDAR representations using self-attention. Our approach uses transformer modules at multiple resolutions to fuse perspective view and bird's eye view feature maps. We experimentally validate its efficacy on a challenging new benchmark with long routes and dense traffic, as well as the official leaderboard of the CARLA urban driving simulator. At the time of submission, TransFuser outperforms all prior work on the CARLA leaderboard in terms of driving score by a large margin. Compared to geometry-based fusion, TransFuser reduces the average collisions per kilometer by 48%.
KING: Generating Safety-Critical Driving Scenarios for Robust Imitation via Kinematics Gradients
Apr 28, 2022

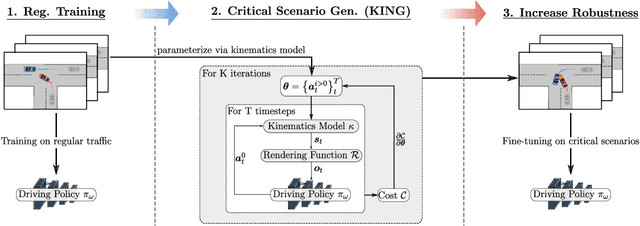
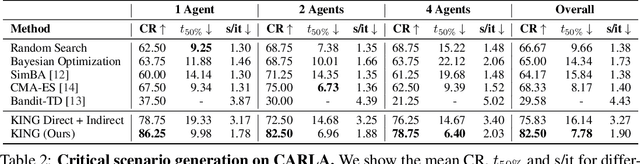
Simulators offer the possibility of safe, low-cost development of self-driving systems. However, current driving simulators exhibit na\"ive behavior models for background traffic. Hand-tuned scenarios are typically added during simulation to induce safety-critical situations. An alternative approach is to adversarially perturb the background traffic trajectories. In this paper, we study this approach to safety-critical driving scenario generation using the CARLA simulator. We use a kinematic bicycle model as a proxy to the simulator's true dynamics and observe that gradients through this proxy model are sufficient for optimizing the background traffic trajectories. Based on this finding, we propose KING, which generates safety-critical driving scenarios with a 20% higher success rate than black-box optimization. By solving the scenarios generated by KING using a privileged rule-based expert algorithm, we obtain training data for an imitation learning policy. After fine-tuning on this new data, we show that the policy becomes better at avoiding collisions. Importantly, our generated data leads to reduced collisions on both held-out scenarios generated via KING as well as traditional hand-crafted scenarios, demonstrating improved robustness.