 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContinual Learning Beyond Experience Rehearsal and Full Model Surrogates
May 28, 2025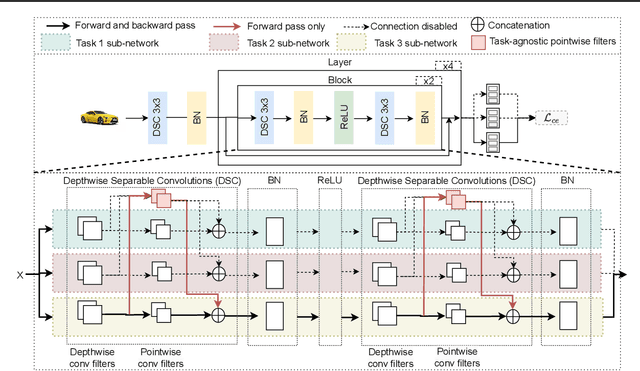
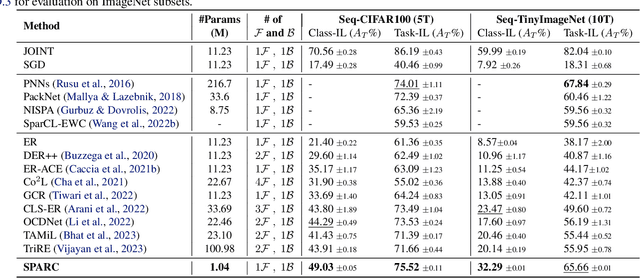
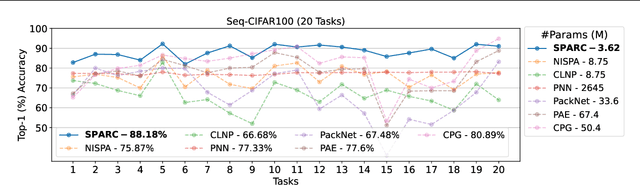
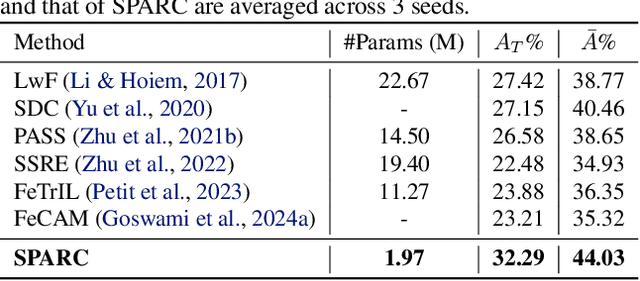
Continual learning (CL) has remained a significant challenge for deep neural networks as learning new tasks erases previously acquired knowledge, either partially or completely. Existing solutions often rely on experience rehearsal or full model surrogates to mitigate CF. While effective, these approaches introduce substantial memory and computational overhead, limiting their scalability and applicability in real-world scenarios. To address this, we propose SPARC, a scalable CL approach that eliminates the need for experience rehearsal and full-model surrogates. By effectively combining task-specific working memories and task-agnostic semantic memory for cross-task knowledge consolidation, SPARC results in a remarkable parameter efficiency, using only 6% of the parameters required by full-model surrogates. Despite its lightweight design, SPARC achieves superior performance on Seq-TinyImageNet and matches rehearsal-based methods on various CL benchmarks. Additionally, weight re-normalization in the classification layer mitigates task-specific biases, establishing SPARC as a practical and scalable solution for CL under stringent efficiency constraints.
Parameter Efficient Continual Learning with Dynamic Low-Rank Adaptation
May 17, 2025Catastrophic forgetting has remained a critical challenge for deep neural networks in Continual Learning (CL) as it undermines consolidated knowledge when learning new tasks. Parameter efficient fine tuning CL techniques are gaining traction for their effectiveness in addressing catastrophic forgetting with a lightweight training schedule while avoiding degradation of consolidated knowledge in pre-trained models. However, low rank adapters (LoRA) in these approaches are highly sensitive to rank selection which can lead to sub-optimal resource allocation and performance. To this end, we introduce PEARL, a rehearsal-free CL framework that entails dynamic rank allocation for LoRA components during CL training. Specifically, PEARL leverages reference task weights and adaptively determines the rank of task-specific LoRA components based on the current tasks' proximity to reference task weights in parameter space. To demonstrate the versatility of PEARL, we evaluate it across three vision architectures (ResNet, Separable Convolutional Network and Vision Transformer) and a multitude of CL scenarios, and show that PEARL outperforms all considered baselines by a large margin.
GAIA-2: A Controllable Multi-View Generative World Model for Autonomous Driving
Mar 26, 2025
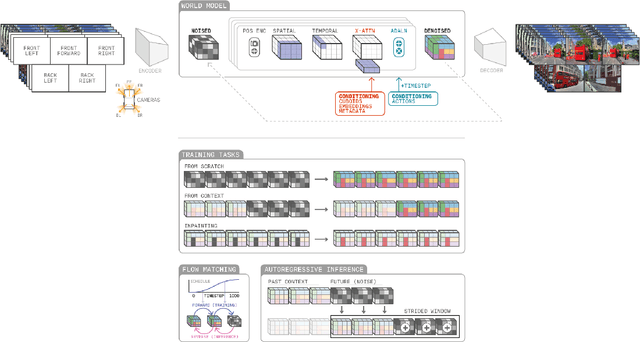


Generative models offer a scalable and flexible paradigm for simulating complex environments, yet current approaches fall short in addressing the domain-specific requirements of autonomous driving - such as multi-agent interactions, fine-grained control, and multi-camera consistency. We introduce GAIA-2, Generative AI for Autonomy, a latent diffusion world model that unifies these capabilities within a single generative framework. GAIA-2 supports controllable video generation conditioned on a rich set of structured inputs: ego-vehicle dynamics, agent configurations, environmental factors, and road semantics. It generates high-resolution, spatiotemporally consistent multi-camera videos across geographically diverse driving environments (UK, US, Germany). The model integrates both structured conditioning and external latent embeddings (e.g., from a proprietary driving model) to facilitate flexible and semantically grounded scene synthesis. Through this integration, GAIA-2 enables scalable simulation of both common and rare driving scenarios, advancing the use of generative world models as a core tool in the development of autonomous systems. Videos are available at https://wayve.ai/thinking/gaia-2.
SimLingo: Vision-Only Closed-Loop Autonomous Driving with Language-Action Alignment
Mar 12, 2025

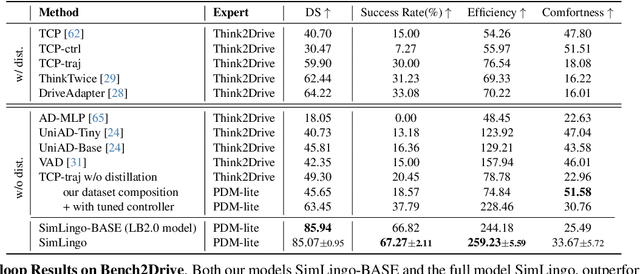

Integrating large language models (LLMs) into autonomous driving has attracted significant attention with the hope of improving generalization and explainability. However, existing methods often focus on either driving or vision-language understanding but achieving both high driving performance and extensive language understanding remains challenging. In addition, the dominant approach to tackle vision-language understanding is using visual question answering. However, for autonomous driving, this is only useful if it is aligned with the action space. Otherwise, the model's answers could be inconsistent with its behavior. Therefore, we propose a model that can handle three different tasks: (1) closed-loop driving, (2) vision-language understanding, and (3) language-action alignment. Our model SimLingo is based on a vision language model (VLM) and works using only camera, excluding expensive sensors like LiDAR. SimLingo obtains state-of-the-art performance on the widely used CARLA simulator on the Bench2Drive benchmark and is the winning entry at the CARLA challenge 2024. Additionally, we achieve strong results in a wide variety of language-related tasks while maintaining high driving performance.
Gradual Divergence for Seamless Adaptation: A Novel Domain Incremental Learning Method
Jun 23, 2024Domain incremental learning (DIL) poses a significant challenge in real-world scenarios, as models need to be sequentially trained on diverse domains over time, all the while avoiding catastrophic forgetting. Mitigating representation drift, which refers to the phenomenon of learned representations undergoing changes as the model adapts to new tasks, can help alleviate catastrophic forgetting. In this study, we propose a novel DIL method named DARE, featuring a three-stage training process: Divergence, Adaptation, and REfinement. This process gradually adapts the representations associated with new tasks into the feature space spanned by samples from previous tasks, simultaneously integrating task-specific decision boundaries. Additionally, we introduce a novel strategy for buffer sampling and demonstrate the effectiveness of our proposed method, combined with this sampling strategy, in reducing representation drift within the feature encoder. This contribution effectively alleviates catastrophic forgetting across multiple DIL benchmarks. Furthermore, our approach prevents sudden representation drift at task boundaries, resulting in a well-calibrated DIL model that maintains the performance on previous tasks.
CarLLaVA: Vision language models for camera-only closed-loop driving
Jun 14, 2024



In this technical report, we present CarLLaVA, a Vision Language Model (VLM) for autonomous driving, developed for the CARLA Autonomous Driving Challenge 2.0. CarLLaVA uses the vision encoder of the LLaVA VLM and the LLaMA architecture as backbone, achieving state-of-the-art closed-loop driving performance with only camera input and without the need for complex or expensive labels. Additionally, we show preliminary results on predicting language commentary alongside the driving output. CarLLaVA uses a semi-disentangled output representation of both path predictions and waypoints, getting the advantages of the path for better lateral control and the waypoints for better longitudinal control. We propose an efficient training recipe to train on large driving datasets without wasting compute on easy, trivial data. CarLLaVA ranks 1st place in the sensor track of the CARLA Autonomous Driving Challenge 2.0 outperforming the previous state of the art by 458% and the best concurrent submission by 32.6%.
Mitigating Interference in the Knowledge Continuum through Attention-Guided Incremental Learning
May 22, 2024Continual learning (CL) remains a significant challenge for deep neural networks, as it is prone to forgetting previously acquired knowledge. Several approaches have been proposed in the literature, such as experience rehearsal, regularization, and parameter isolation, to address this problem. Although almost zero forgetting can be achieved in task-incremental learning, class-incremental learning remains highly challenging due to the problem of inter-task class separation. Limited access to previous task data makes it difficult to discriminate between classes of current and previous tasks. To address this issue, we propose `Attention-Guided Incremental Learning' (AGILE), a novel rehearsal-based CL approach that incorporates compact task attention to effectively reduce interference between tasks. AGILE utilizes lightweight, learnable task projection vectors to transform the latent representations of a shared task attention module toward task distribution. Through extensive empirical evaluation, we show that AGILE significantly improves generalization performance by mitigating task interference and outperforming rehearsal-based approaches in several CL scenarios. Furthermore, AGILE can scale well to a large number of tasks with minimal overhead while remaining well-calibrated with reduced task-recency bias.
Beyond Unimodal Learning: The Importance of Integrating Multiple Modalities for Lifelong Learning
May 04, 2024While humans excel at continual learning (CL), deep neural networks (DNNs) exhibit catastrophic forgetting. A salient feature of the brain that allows effective CL is that it utilizes multiple modalities for learning and inference, which is underexplored in DNNs. Therefore, we study the role and interactions of multiple modalities in mitigating forgetting and introduce a benchmark for multimodal continual learning. Our findings demonstrate that leveraging multiple views and complementary information from multiple modalities enables the model to learn more accurate and robust representations. This makes the model less vulnerable to modality-specific regularities and considerably mitigates forgetting. Furthermore, we observe that individual modalities exhibit varying degrees of robustness to distribution shift. Finally, we propose a method for integrating and aligning the information from different modalities by utilizing the relational structural similarities between the data points in each modality. Our method sets a strong baseline that enables both single- and multimodal inference. Our study provides a promising case for further exploring the role of multiple modalities in enabling CL and provides a standard benchmark for future research.
IMEX-Reg: Implicit-Explicit Regularization in the Function Space for Continual Learning
Apr 28, 2024Continual learning (CL) remains one of the long-standing challenges for deep neural networks due to catastrophic forgetting of previously acquired knowledge. Although rehearsal-based approaches have been fairly successful in mitigating catastrophic forgetting, they suffer from overfitting on buffered samples and prior information loss, hindering generalization under low-buffer regimes. Inspired by how humans learn using strong inductive biases, we propose IMEX-Reg to improve the generalization performance of experience rehearsal in CL under low buffer regimes. Specifically, we employ a two-pronged implicit-explicit regularization approach using contrastive representation learning (CRL) and consistency regularization. To further leverage the global relationship between representations learned using CRL, we propose a regularization strategy to guide the classifier toward the activation correlations in the unit hypersphere of the CRL. Our results show that IMEX-Reg significantly improves generalization performance and outperforms rehearsal-based approaches in several CL scenarios. It is also robust to natural and adversarial corruptions with less task-recency bias. Additionally, we provide theoretical insights to support our design decisions further.
Can We Break Free from Strong Data Augmentations in Self-Supervised Learning?
Apr 15, 2024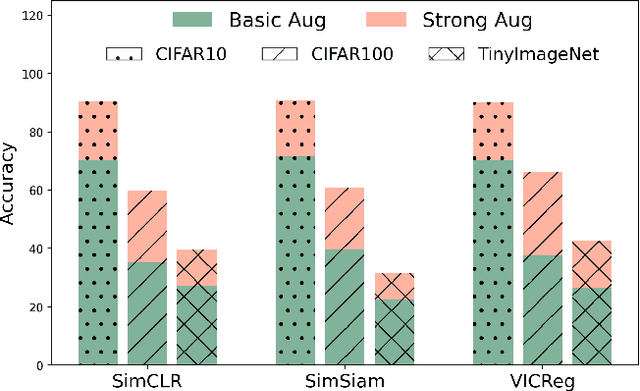

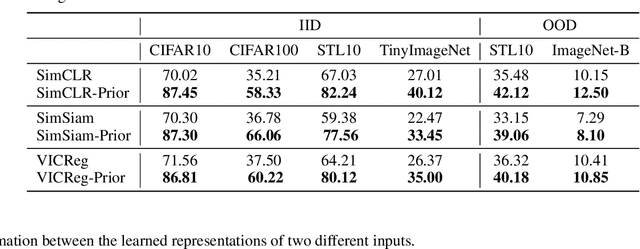
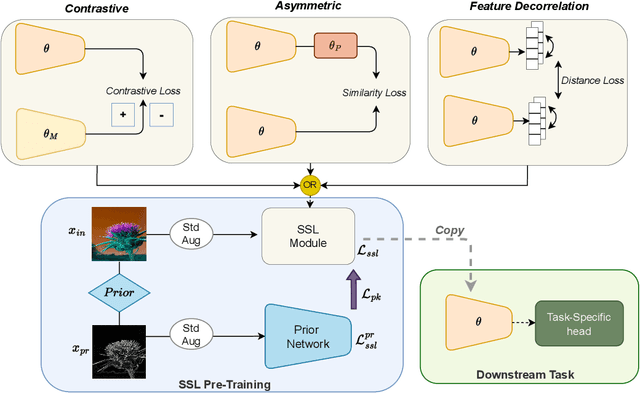
Self-supervised learning (SSL) has emerged as a promising solution for addressing the challenge of limited labeled data in deep neural networks (DNNs), offering scalability potential. However, the impact of design dependencies within the SSL framework remains insufficiently investigated. In this study, we comprehensively explore SSL behavior across a spectrum of augmentations, revealing their crucial role in shaping SSL model performance and learning mechanisms. Leveraging these insights, we propose a novel learning approach that integrates prior knowledge, with the aim of curtailing the need for extensive data augmentations and thereby amplifying the efficacy of learned representations. Notably, our findings underscore that SSL models imbued with prior knowledge exhibit reduced texture bias, diminished reliance on shortcuts and augmentations, and improved robustness against both natural and adversarial corruptions. These findings not only illuminate a new direction in SSL research, but also pave the way for enhancing DNN performance while concurrently alleviating the imperative for intensive data augmentation, thereby enhancing scalability and real-world problem-solving capabilities.