 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Unimodal Learning: The Importance of Integrating Multiple Modalities for Lifelong Learning
May 04, 2024
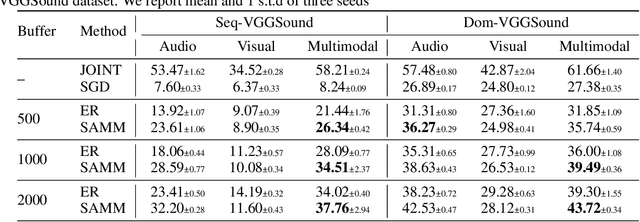

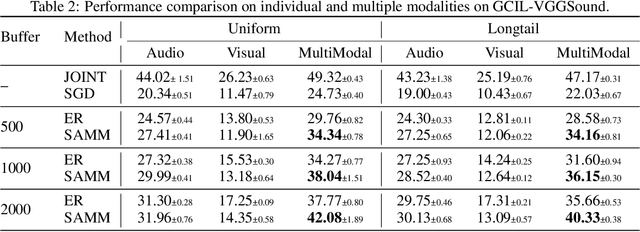
While humans excel at continual learning (CL), deep neural networks (DNNs) exhibit catastrophic forgetting. A salient feature of the brain that allows effective CL is that it utilizes multiple modalities for learning and inference, which is underexplored in DNNs. Therefore, we study the role and interactions of multiple modalities in mitigating forgetting and introduce a benchmark for multimodal continual learning. Our findings demonstrate that leveraging multiple views and complementary information from multiple modalities enables the model to learn more accurate and robust representations. This makes the model less vulnerable to modality-specific regularities and considerably mitigates forgetting. Furthermore, we observe that individual modalities exhibit varying degrees of robustness to distribution shift. Finally, we propose a method for integrating and aligning the information from different modalities by utilizing the relational structural similarities between the data points in each modality. Our method sets a strong baseline that enables both single- and multimodal inference. Our study provides a promising case for further exploring the role of multiple modalities in enabling CL and provides a standard benchmark for future research.
Towards Brain Inspired Design for Addressing the Shortcomings of ANNs
Jun 30, 2023As our understanding of the mechanisms of brain function is enhanced, the value of insights gained from neuroscience to the development of AI algorithms deserves further consideration. Here, we draw parallels with an existing tree-based ANN architecture and a recent neuroscience study[27] arguing that the error-based organization of neurons in the cerebellum that share a preference for a personalized view of the entire error space, may account for several desirable features of behavior and learning. We then analyze the learning behavior and characteristics of the model under varying scenarios to gauge the potential benefits of a similar mechanism in ANN. Our empirical results suggest that having separate populations of neurons with personalized error views can enable efficient learning under class imbalance and limited data, and reduce the susceptibility to unintended shortcut strategies, leading to improved generalization. This work highlights the potential of translating the learning machinery of the brain into the design of a new generation of ANNs and provides further credence to the argument that biologically inspired AI may hold the key to overcoming the shortcomings of ANNs.
A Study of Biologically Plausible Neural Network: The Role and Interactions of Brain-Inspired Mechanisms in Continual Learning
Apr 13, 2023
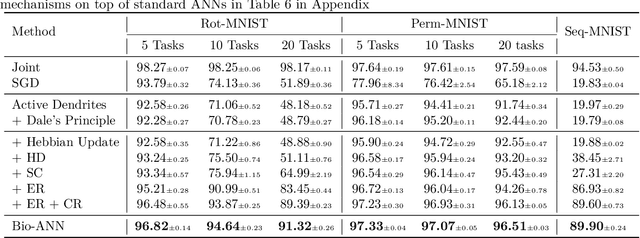


Humans excel at continually acquiring, consolidating, and retaining information from an ever-changing environment, whereas artificial neural networks (ANNs) exhibit catastrophic forgetting. There are considerable differences in the complexity of synapses, the processing of information, and the learning mechanisms in biological neural networks and their artificial counterparts, which may explain the mismatch in performance. We consider a biologically plausible framework that constitutes separate populations of exclusively excitatory and inhibitory neurons that adhere to Dale's principle, and the excitatory pyramidal neurons are augmented with dendritic-like structures for context-dependent processing of stimuli. We then conduct a comprehensive study on the role and interactions of different mechanisms inspired by the brain, including sparse non-overlapping representations, Hebbian learning, synaptic consolidation, and replay of past activations that accompanied the learning event. Our study suggests that the employing of multiple complementary mechanisms in a biologically plausible architecture, similar to the brain, may be effective in enabling continual learning in ANNs.
Error Sensitivity Modulation based Experience Replay: Mitigating Abrupt Representation Drift in Continual Learning
Feb 14, 2023



Humans excel at lifelong learning, as the brain has evolved to be robust to distribution shifts and noise in our ever-changing environment. Deep neural networks (DNNs), however, exhibit catastrophic forgetting and the learned representations drift drastically as they encounter a new task. This alludes to a different error-based learning mechanism in the brain. Unlike DNNs, where learning scales linearly with the magnitude of the error, the sensitivity to errors in the brain decreases as a function of their magnitude. To this end, we propose \textit{ESMER} which employs a principled mechanism to modulate error sensitivity in a dual-memory rehearsal-based system. Concretely, it maintains a memory of past errors and uses it to modify the learning dynamics so that the model learns more from small consistent errors compared to large sudden errors. We also propose \textit{Error-Sensitive Reservoir Sampling} to maintain episodic memory, which leverages the error history to pre-select low-loss samples as candidates for the buffer, which are better suited for retaining information. Empirical results show that ESMER effectively reduces forgetting and abrupt drift in representations at the task boundary by gradually adapting to the new task while consolidating knowledge. Remarkably, it also enables the model to learn under high levels of label noise, which is ubiquitous in real-world data streams.
SYNERgy between SYNaptic consolidation and Experience Replay for general continual learning
Jun 08, 2022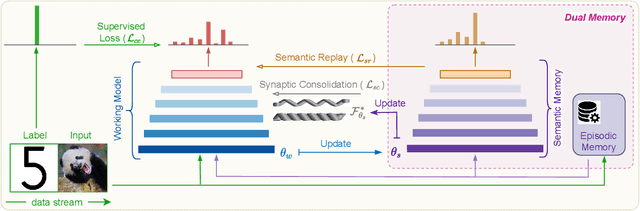
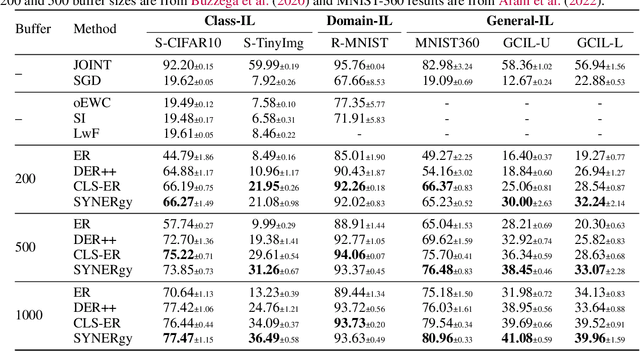
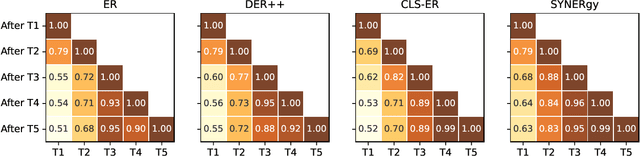
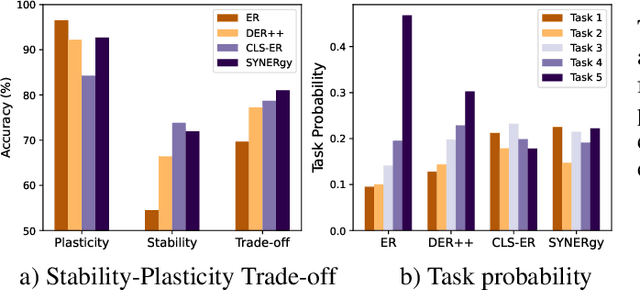
Continual learning (CL) in the brain is facilitated by a complex set of mechanisms. This includes the interplay of multiple memory systems for consolidating information as posited by the complementary learning systems (CLS) theory and synaptic consolidation for protecting the acquired knowledge from erasure. Thus, we propose a general CL method that creates a synergy between SYNaptic consolidation and dual memory Experience Replay (SYNERgy). Our method maintains a semantic memory that accumulates and consolidates information across the tasks and interacts with the episodic memory for effective replay. It further employs synaptic consolidation by tracking the importance of parameters during the training trajectory and anchoring them to the consolidated parameters in the semantic memory. To the best of our knowledge, our study is the first to employ dual memory experience replay in conjunction with synaptic consolidation that is suitable for general CL whereby the network does not utilize task boundaries or task labels during training or inference. Our evaluation on various challenging CL scenarios and characteristics analyses demonstrate the efficacy of incorporating both synaptic consolidation and CLS theory in enabling effective CL in DNNs.
Learning Fast, Learning Slow: A General Continual Learning Method based on Complementary Learning System
Jan 29, 2022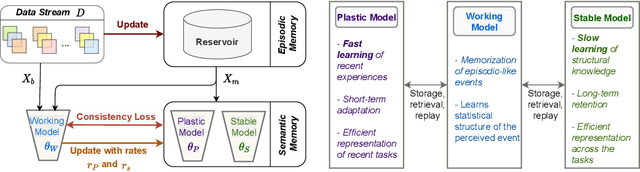
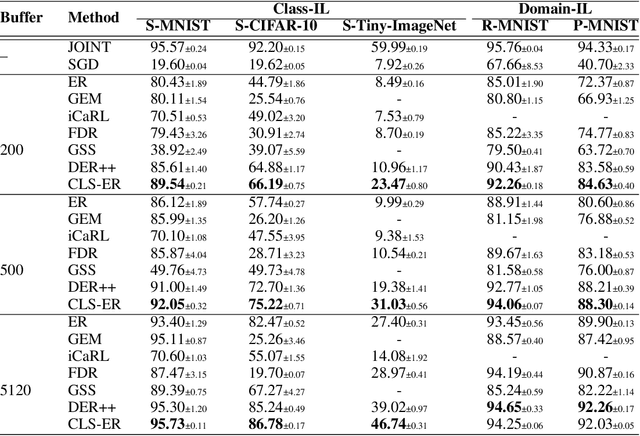
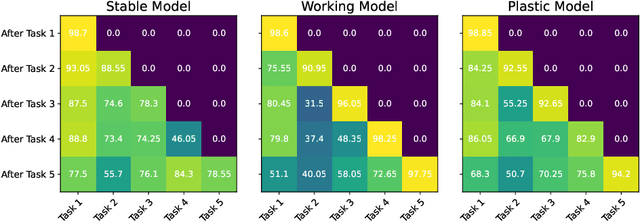

Humans excel at continually learning from an ever-changing environment whereas it remains a challenge for deep neural networks which exhibit catastrophic forgetting. The complementary learning system (CLS) theory suggests that the interplay between rapid instance-based learning and slow structured learning in the brain is crucial for accumulating and retaining knowledge. Here, we propose CLS-ER, a novel dual memory experience replay (ER) method which maintains short-term and long-term semantic memories that interact with the episodic memory. Our method employs an effective replay mechanism whereby new knowledge is acquired while aligning the decision boundaries with the semantic memories. CLS-ER does not utilize the task boundaries or make any assumption about the distribution of the data which makes it versatile and suited for "general continual learning". Our approach achieves state-of-the-art performance on standard benchmarks as well as more realistic general continual learning settings.
Noisy Concurrent Training for Efficient Learning under Label Noise
Sep 17, 2020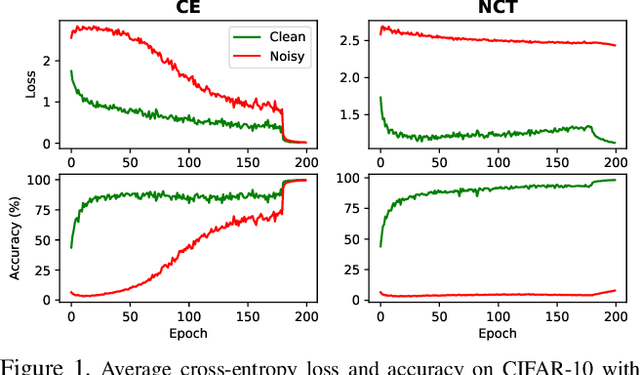

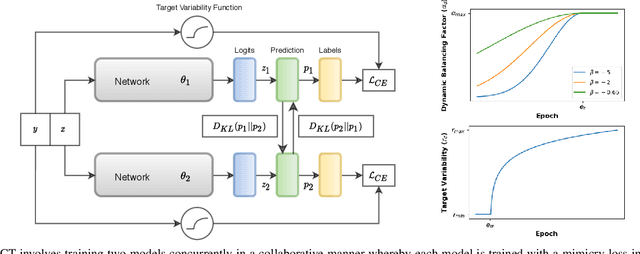
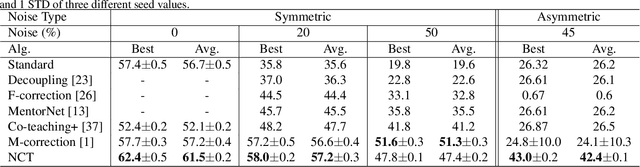
Deep neural networks (DNNs) fail to learn effectively under label noise and have been shown to memorize random labels which affect their generalization performance. We consider learning in isolation, using one-hot encoded labels as the sole source of supervision, and a lack of regularization to discourage memorization as the major shortcomings of the standard training procedure. Thus, we propose Noisy Concurrent Training (NCT) which leverages collaborative learning to use the consensus between two models as an additional source of supervision. Furthermore, inspired by trial-to-trial variability in the brain, we propose a counter-intuitive regularization technique, target variability, which entails randomly changing the labels of a percentage of training samples in each batch as a deterrent to memorization and over-generalization in DNNs. Target variability is applied independently to each model to keep them diverged and avoid the confirmation bias. As DNNs tend to prioritize learning simple patterns first before memorizing the noisy labels, we employ a dynamic learning scheme whereby as the training progresses, the two models increasingly rely more on their consensus. NCT also progressively increases the target variability to avoid memorization in later stages. We demonstrate the effectiveness of our approach on both synthetic and real-world noisy benchmark datasets.
Adversarial Concurrent Training: Optimizing Robustness and Accuracy Trade-off of Deep Neural Networks
Aug 18, 2020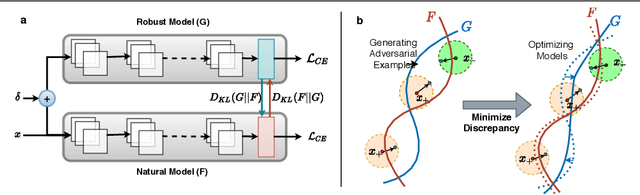


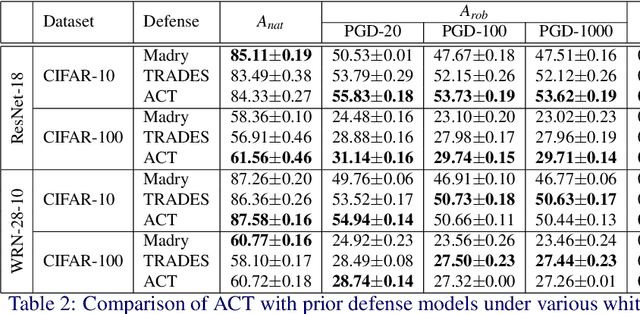
Adversarial training has been proven to be an effective technique for improving the adversarial robustness of models. However, there seems to be an inherent trade-off between optimizing the model for accuracy and robustness. To this end, we propose Adversarial Concurrent Training (ACT), which employs adversarial training in a collaborative learning framework whereby we train a robust model in conjunction with a natural model in a minimax game. ACT encourages the two models to align their feature space by using the task-specific decision boundaries and explore the input space more broadly. Furthermore, the natural model acts as a regularizer, enforcing priors on features that the robust model should learn. Our analyses on the behavior of the models show that ACT leads to a robust model with lower model complexity, higher information compression in the learned representations, and high posterior entropy solutions indicative of convergence to a flatter minima. We demonstrate the effectiveness of the proposed approach across different datasets and network architectures. On ImageNet, ACT achieves 68.20% standard accuracy and 44.29% robustness accuracy under a 100-iteration untargeted attack, improving upon the standard adversarial training method's 65.70% standard accuracy and 42.36% robustness.
Knowledge Distillation Beyond Model Compression
Jul 03, 2020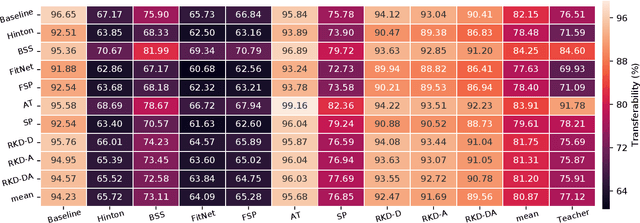
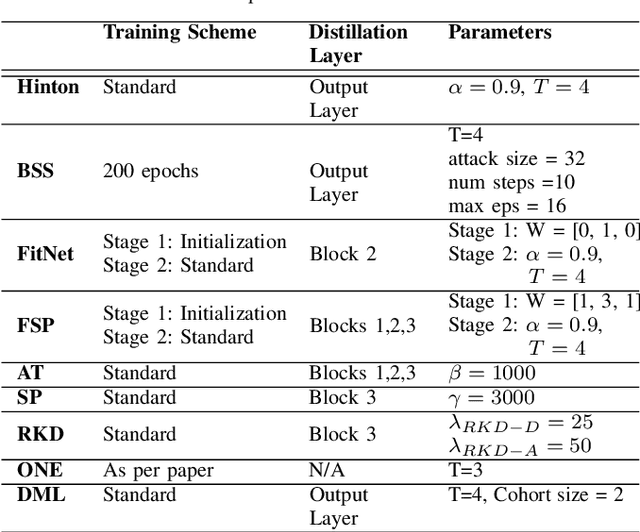
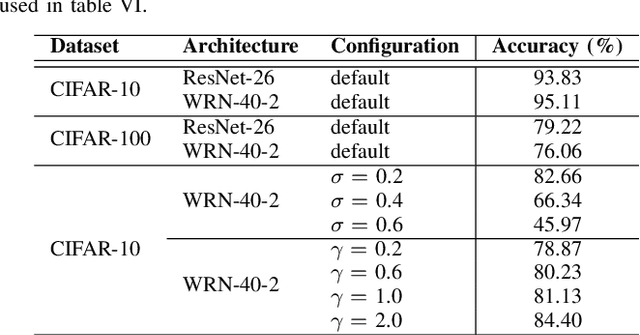
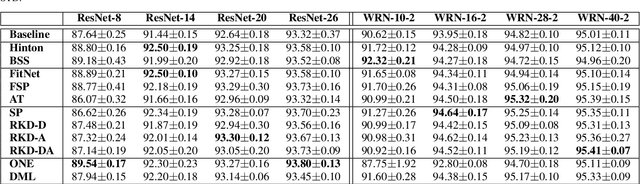
Knowledge distillation (KD) is commonly deemed as an effective model compression technique in which a compact model (student) is trained under the supervision of a larger pretrained model or an ensemble of models (teacher). Various techniques have been proposed since the original formulation, which mimic different aspects of the teacher such as the representation space, decision boundary, or intra-data relationship. Some methods replace the one-way knowledge distillation from a static teacher with collaborative learning between a cohort of students. Despite the recent advances, a clear understanding of where knowledge resides in a deep neural network and an optimal method for capturing knowledge from teacher and transferring it to student remains an open question. In this study, we provide an extensive study on nine different KD methods which covers a broad spectrum of approaches to capture and transfer knowledge. We demonstrate the versatility of the KD framework on different datasets and network architectures under varying capacity gaps between the teacher and student. The study provides intuition for the effects of mimicking different aspects of the teacher and derives insights from the performance of the different distillation approaches to guide the design of more effective KD methods. Furthermore, our study shows the effectiveness of the KD framework in learning efficiently under varying severity levels of label noise and class imbalance, consistently providing generalization gains over standard training. We emphasize that the efficacy of KD goes much beyond a model compression technique and it should be considered as a general-purpose training paradigm which offers more robustness to common challenges in the real-world datasets compared to the standard training procedure.
Improving Generalization and Robustness with Noisy Collaboration in Knowledge Distillation
Oct 11, 2019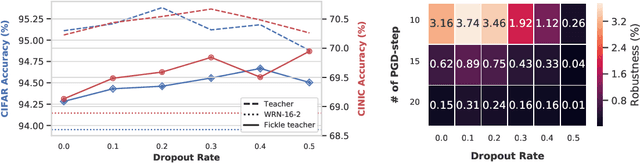
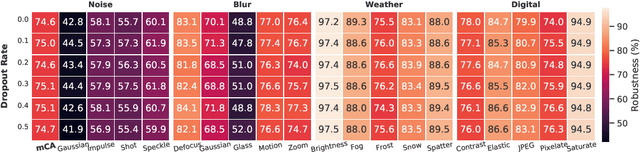
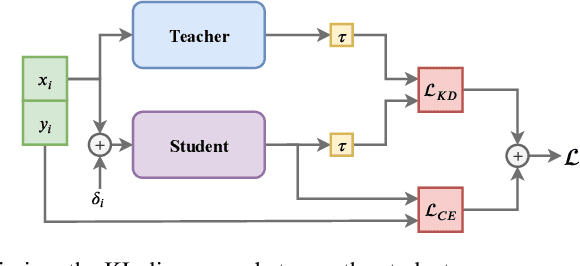
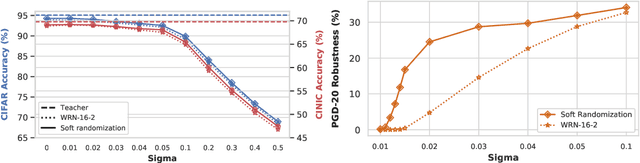
Inspired by trial-to-trial variability in the brain that can result from multiple noise sources, we introduce variability through noise at different levels in a knowledge distillation framework. We introduce "Fickle Teacher" which provides variable supervision signals to the student for the same input. We observe that the response variability from the teacher results in a significant generalization improvement in the student. We further propose "Soft-Randomization" as a novel technique for improving robustness to input variability in the student. This minimizes the dissimilarity between the student's distribution on noisy data with teacher's distribution on clean data. We show that soft-randomization, even with low noise intensity, improves the robustness significantly with minimal drop in generalization. Lastly, we propose a new technique, "Messy-collaboration", which introduces target variability, whereby student and/or teacher are trained with randomly corrupted labels. We find that supervision from a corrupted teacher improves the adversarial robustness of student significantly while preserving its generalization and natural robustness. Our extensive empirical results verify the effectiveness of adding constructive noise in the knowledge distillation framework for improving the generalization and robustness of the model.