 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowledge Distillation Beyond Model Compression
Paper and Code
Jul 03, 2020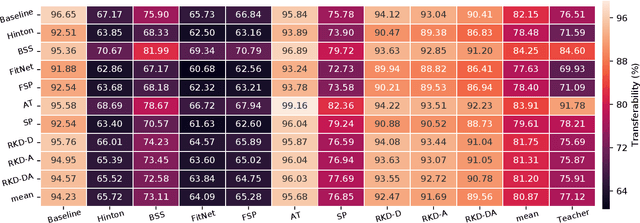
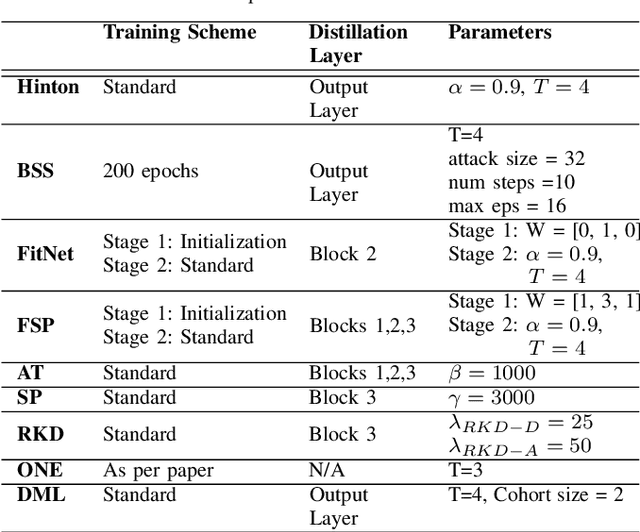
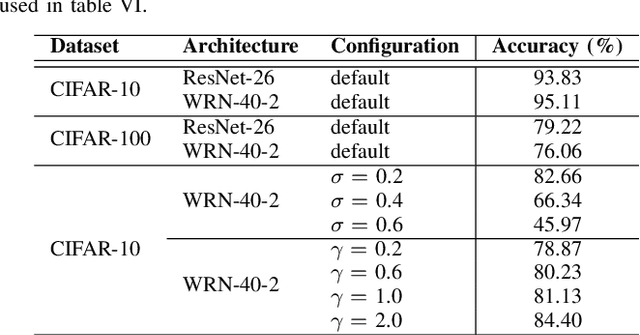
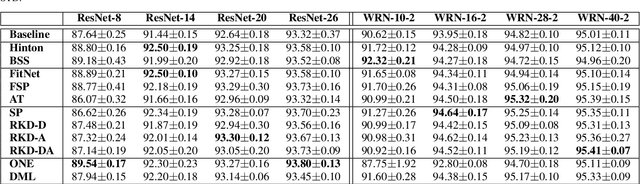
Knowledge distillation (KD) is commonly deemed as an effective model compression technique in which a compact model (student) is trained under the supervision of a larger pretrained model or an ensemble of models (teacher). Various techniques have been proposed since the original formulation, which mimic different aspects of the teacher such as the representation space, decision boundary, or intra-data relationship. Some methods replace the one-way knowledge distillation from a static teacher with collaborative learning between a cohort of students. Despite the recent advances, a clear understanding of where knowledge resides in a deep neural network and an optimal method for capturing knowledge from teacher and transferring it to student remains an open question. In this study, we provide an extensive study on nine different KD methods which covers a broad spectrum of approaches to capture and transfer knowledge. We demonstrate the versatility of the KD framework on different datasets and network architectures under varying capacity gaps between the teacher and student. The study provides intuition for the effects of mimicking different aspects of the teacher and derives insights from the performance of the different distillation approaches to guide the design of more effective KD methods. Furthermore, our study shows the effectiveness of the KD framework in learning efficiently under varying severity levels of label noise and class imbalance, consistently providing generalization gains over standard training. We emphasize that the efficacy of KD goes much beyond a model compression technique and it should be considered as a general-purpose training paradigm which offers more robustness to common challenges in the real-world datasets compared to the standard training procedure.