 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGAIA-2: A Controllable Multi-View Generative World Model for Autonomous Driving
Mar 26, 2025
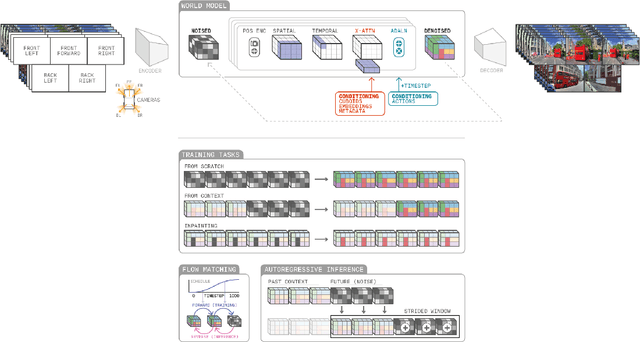


Generative models offer a scalable and flexible paradigm for simulating complex environments, yet current approaches fall short in addressing the domain-specific requirements of autonomous driving - such as multi-agent interactions, fine-grained control, and multi-camera consistency. We introduce GAIA-2, Generative AI for Autonomy, a latent diffusion world model that unifies these capabilities within a single generative framework. GAIA-2 supports controllable video generation conditioned on a rich set of structured inputs: ego-vehicle dynamics, agent configurations, environmental factors, and road semantics. It generates high-resolution, spatiotemporally consistent multi-camera videos across geographically diverse driving environments (UK, US, Germany). The model integrates both structured conditioning and external latent embeddings (e.g., from a proprietary driving model) to facilitate flexible and semantically grounded scene synthesis. Through this integration, GAIA-2 enables scalable simulation of both common and rare driving scenarios, advancing the use of generative world models as a core tool in the development of autonomous systems. Videos are available at https://wayve.ai/thinking/gaia-2.
Batch-Instructed Gradient for Prompt Evolution:Systematic Prompt Optimization for Enhanced Text-to-Image Synthesis
Jun 13, 2024Text-to-image models have shown remarkable progress in generating high-quality images from user-provided prompts. Despite this, the quality of these images varies due to the models' sensitivity to human language nuances. With advancements in large language models, there are new opportunities to enhance prompt design for image generation tasks. Existing research primarily focuses on optimizing prompts for direct interaction, while less attention is given to scenarios involving intermediary agents, like the Stable Diffusion model. This study proposes a Multi-Agent framework to optimize input prompts for text-to-image generation models. Central to this framework is a prompt generation mechanism that refines initial queries using dynamic instructions, which evolve through iterative performance feedback. High-quality prompts are then fed into a state-of-the-art text-to-image model. A professional prompts database serves as a benchmark to guide the instruction modifier towards generating high-caliber prompts. A scoring system evaluates the generated images, and an LLM generates new instructions based on calculated gradients. This iterative process is managed by the Upper Confidence Bound (UCB) algorithm and assessed using the Human Preference Score version 2 (HPS v2). Preliminary ablation studies highlight the effectiveness of various system components and suggest areas for future improvements.
LangProp: A code optimization framework using Language Models applied to driving
Jan 18, 2024



LangProp is a framework for iteratively optimizing code generated by large language models (LLMs) in a supervised/reinforcement learning setting. While LLMs can generate sensible solutions zero-shot, the solutions are often sub-optimal. Especially for code generation tasks, it is likely that the initial code will fail on certain edge cases. LangProp automatically evaluates the code performance on a dataset of input-output pairs, as well as catches any exceptions, and feeds the results back to the LLM in the training loop, so that the LLM can iteratively improve the code it generates. By adopting a metric- and data-driven training paradigm for this code optimization procedure, one could easily adapt findings from traditional machine learning techniques such as imitation learning, DAgger, and reinforcement learning. We demonstrate the first proof of concept of automated code optimization for autonomous driving in CARLA, showing that LangProp can generate interpretable and transparent driving policies that can be verified and improved in a metric- and data-driven way. Our code will be open-sourced and is available at https://github.com/shuishida/LangProp.
GAIA-1: A Generative World Model for Autonomous Driving
Sep 29, 2023Autonomous driving promises transformative improvements to transportation, but building systems capable of safely navigating the unstructured complexity of real-world scenarios remains challenging. A critical problem lies in effectively predicting the various potential outcomes that may emerge in response to the vehicle's actions as the world evolves. To address this challenge, we introduce GAIA-1 ('Generative AI for Autonomy'), a generative world model that leverages video, text, and action inputs to generate realistic driving scenarios while offering fine-grained control over ego-vehicle behavior and scene features. Our approach casts world modeling as an unsupervised sequence modeling problem by mapping the inputs to discrete tokens, and predicting the next token in the sequence. Emerging properties from our model include learning high-level structures and scene dynamics, contextual awareness, generalization, and understanding of geometry. The power of GAIA-1's learned representation that captures expectations of future events, combined with its ability to generate realistic samples, provides new possibilities for innovation in the field of autonomy, enabling enhanced and accelerated training of autonomous driving technology.
Neural World Models for Computer Vision
Jun 15, 2023



Humans navigate in their environment by learning a mental model of the world through passive observation and active interaction. Their world model allows them to anticipate what might happen next and act accordingly with respect to an underlying objective. Such world models hold strong promises for planning in complex environments like in autonomous driving. A human driver, or a self-driving system, perceives their surroundings with their eyes or their cameras. They infer an internal representation of the world which should: (i) have spatial memory (e.g. occlusions), (ii) fill partially observable or noisy inputs (e.g. when blinded by sunlight), and (iii) be able to reason about unobservable events probabilistically (e.g. predict different possible futures). They are embodied intelligent agents that can predict, plan, and act in the physical world through their world model. In this thesis we present a general framework to train a world model and a policy, parameterised by deep neural networks, from camera observations and expert demonstrations. We leverage important computer vision concepts such as geometry, semantics, and motion to scale world models to complex urban driving scenes. First, we propose a model that predicts important quantities in computer vision: depth, semantic segmentation, and optical flow. We then use 3D geometry as an inductive bias to operate in the bird's-eye view space. We present for the first time a model that can predict probabilistic future trajectories of dynamic agents in bird's-eye view from 360{\deg} surround monocular cameras only. Finally, we demonstrate the benefits of learning a world model in closed-loop driving. Our model can jointly predict static scene, dynamic scene, and ego-behaviour in an urban driving environment.
Model-Based Imitation Learning for Urban Driving
Oct 14, 2022
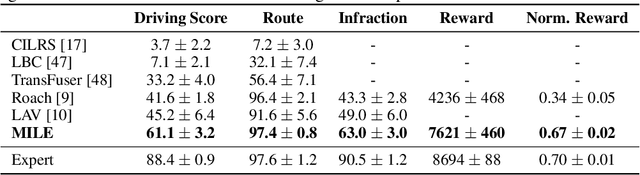
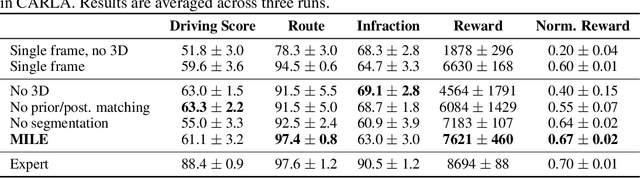
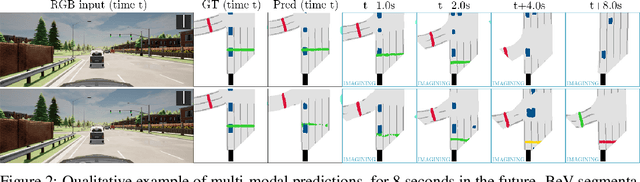
An accurate model of the environment and the dynamic agents acting in it offers great potential for improving motion planning. We present MILE: a Model-based Imitation LEarning approach to jointly learn a model of the world and a policy for autonomous driving. Our method leverages 3D geometry as an inductive bias and learns a highly compact latent space directly from high-resolution videos of expert demonstrations. Our model is trained on an offline corpus of urban driving data, without any online interaction with the environment. MILE improves upon prior state-of-the-art by 35% in driving score on the CARLA simulator when deployed in a completely new town and new weather conditions. Our model can predict diverse and plausible states and actions, that can be interpretably decoded to bird's-eye view semantic segmentation. Further, we demonstrate that it can execute complex driving manoeuvres from plans entirely predicted in imagination. Our approach is the first camera-only method that models static scene, dynamic scene, and ego-behaviour in an urban driving environment. The code and model weights are available at https://github.com/wayveai/mile.
SPIN: Simplifying Polar Invariance for Neural networks Application to vision-based irradiance forecasting
Nov 29, 2021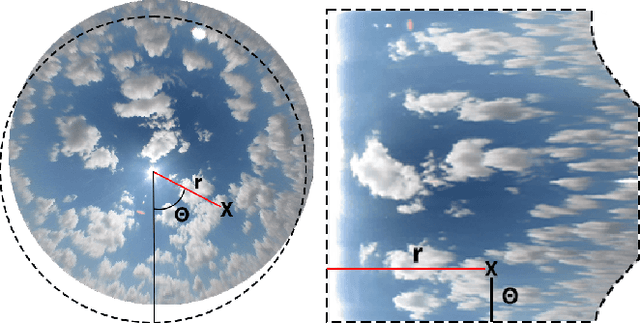
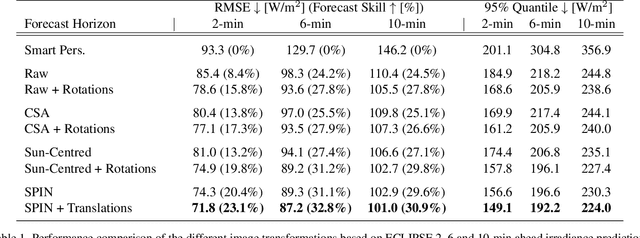

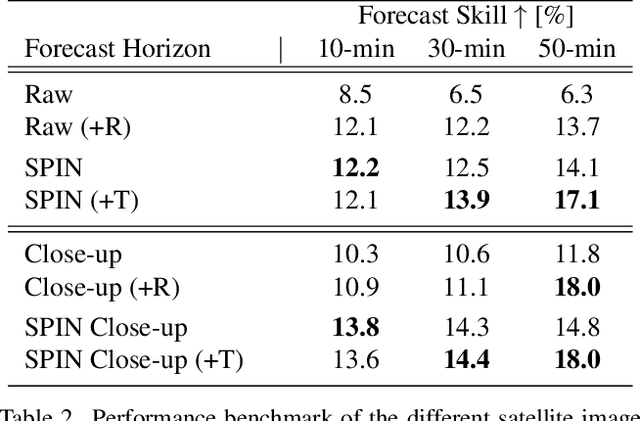
Translational invariance induced by pooling operations is an inherent property of convolutional neural networks, which facilitates numerous computer vision tasks such as classification. Yet to leverage rotational invariant tasks, convolutional architectures require specific rotational invariant layers or extensive data augmentation to learn from diverse rotated versions of a given spatial configuration. Unwrapping the image into its polar coordinates provides a more explicit representation to train a convolutional architecture as the rotational invariance becomes translational, hence the visually distinct but otherwise equivalent rotated versions of a given scene can be learnt from a single image. We show with two common vision-based solar irradiance forecasting challenges (i.e. using ground-taken sky images or satellite images), that this preprocessing step significantly improves prediction results by standardising the scene representation, while decreasing training time by a factor of 4 compared to augmenting data with rotations. In addition, this transformation magnifies the area surrounding the centre of the rotation, leading to more accurate short-term irradiance predictions.
ECLIPSE : Envisioning Cloud Induced Perturbations in Solar Energy
Apr 26, 2021
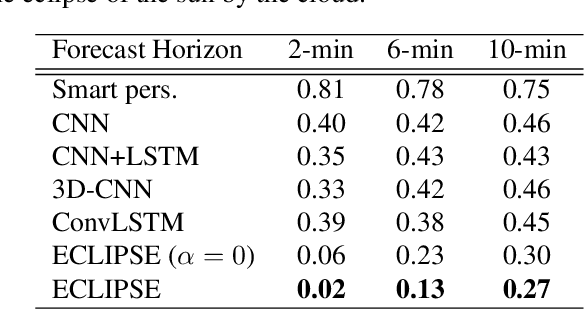
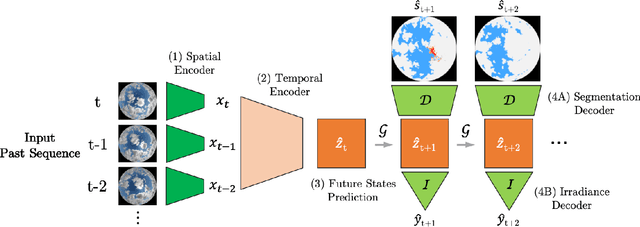
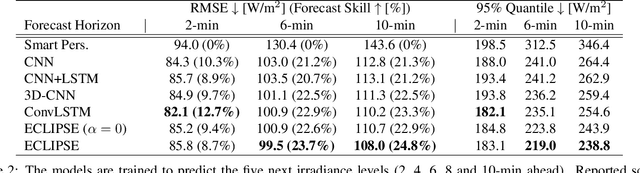
Efficient integration of solar energy into the electricity mix depends on a reliable anticipation of its intermittency. A promising approach to forecast the temporal variability of solar irradiance resulting from the cloud cover dynamics, is based on the analysis of sequences of ground-taken sky images. Despite encouraging results, a recurrent limitation of current Deep Learning approaches lies in the ubiquitous tendency of reacting to past observations rather than actively anticipating future events. This leads to a systematic temporal lag and little ability to predict sudden events. To address this challenge, we introduce ECLIPSE, a spatio-temporal neural network architecture that models cloud motion from sky images to predict both future segmented images and corresponding irradiance levels. We show that ECLIPSE anticipates critical events and considerably reduces temporal delay while generating visually realistic futures.
FIERY: Future Instance Prediction in Bird's-Eye View from Surround Monocular Cameras
Apr 21, 2021
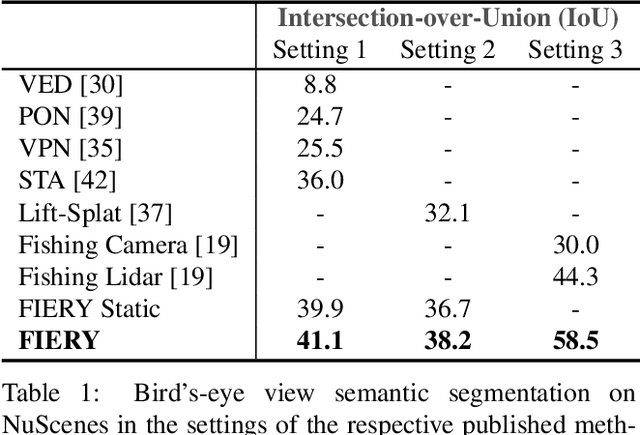
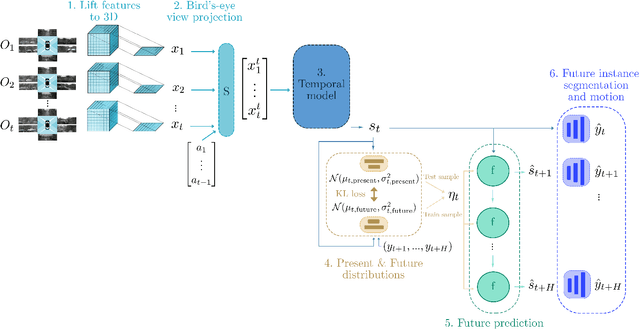
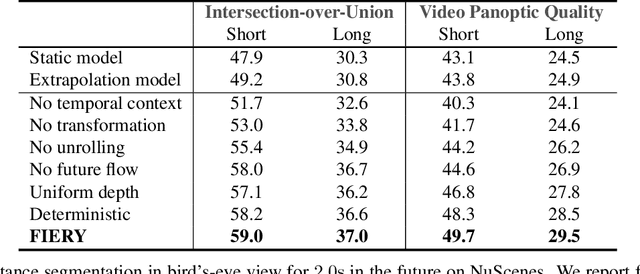
Driving requires interacting with road agents and predicting their future behaviour in order to navigate safely. We present FIERY: a probabilistic future prediction model in bird's-eye view from monocular cameras. Our model predicts future instance segmentation and motion of dynamic agents that can be transformed into non-parametric future trajectories. Our approach combines the perception, sensor fusion and prediction components of a traditional autonomous driving stack by estimating bird's-eye-view prediction directly from surround RGB monocular camera inputs. FIERY learns to model the inherent stochastic nature of the future directly from camera driving data in an end-to-end manner, without relying on HD maps, and predicts multimodal future trajectories. We show that our model outperforms previous prediction baselines on the NuScenes and Lyft datasets. Code is available at https://github.com/wayveai/fiery
Probabilistic Future Prediction for Video Scene Understanding
Mar 13, 2020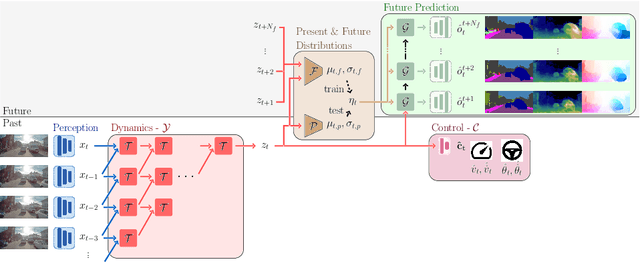
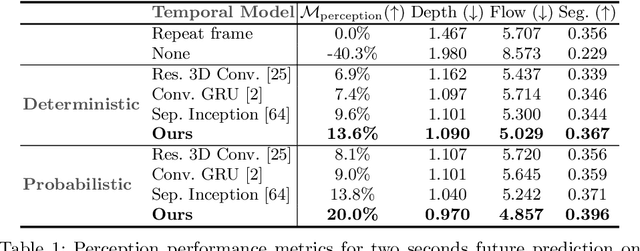

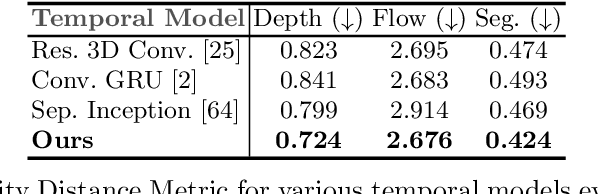
We present a novel deep learning architecture for probabilistic future prediction from video. We predict the future semantics, geometry and motion of complex real-world urban scenes and use this representation to control an autonomous vehicle. This work is the first to jointly predict ego-motion, static scene, and the motion of dynamic agents in a probabilistic manner, which allows sampling consistent, highly probable futures from a compact latent space. Our model learns a representation from RGB video with a spatio-temporal convolutional module. The learned representation can be explicitly decoded to future semantic segmentation, depth, and optical flow, in addition to being an input to a learnt driving policy. To model the stochasticity of the future, we introduce a conditional variational approach which minimises the divergence between the present distribution (what could happen given what we have seen) and the future distribution (what we observe actually happens). During inference, diverse futures are generated by sampling from the present distribution.