 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWayveScenes101: A Dataset and Benchmark for Novel View Synthesis in Autonomous Driving
Jul 11, 2024



We present WayveScenes101, a dataset designed to help the community advance the state of the art in novel view synthesis that focuses on challenging driving scenes containing many dynamic and deformable elements with changing geometry and texture. The dataset comprises 101 driving scenes across a wide range of environmental conditions and driving scenarios. The dataset is designed for benchmarking reconstructions on in-the-wild driving scenes, with many inherent challenges for scene reconstruction methods including image glare, rapid exposure changes, and highly dynamic scenes with significant occlusion. Along with the raw images, we include COLMAP-derived camera poses in standard data formats. We propose an evaluation protocol for evaluating models on held-out camera views that are off-axis from the training views, specifically testing the generalisation capabilities of methods. Finally, we provide detailed metadata for all scenes, including weather, time of day, and traffic conditions, to allow for a detailed model performance breakdown across scene characteristics. Dataset and code are available at https://github.com/wayveai/wayve_scenes.
Probabilistic Future Prediction for Video Scene Understanding
Mar 13, 2020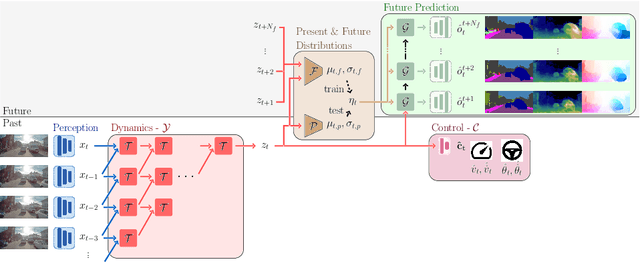
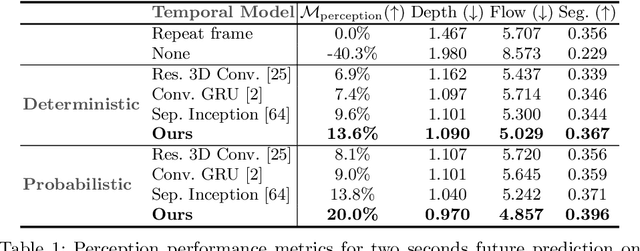

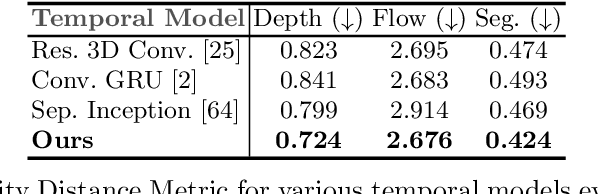
We present a novel deep learning architecture for probabilistic future prediction from video. We predict the future semantics, geometry and motion of complex real-world urban scenes and use this representation to control an autonomous vehicle. This work is the first to jointly predict ego-motion, static scene, and the motion of dynamic agents in a probabilistic manner, which allows sampling consistent, highly probable futures from a compact latent space. Our model learns a representation from RGB video with a spatio-temporal convolutional module. The learned representation can be explicitly decoded to future semantic segmentation, depth, and optical flow, in addition to being an input to a learnt driving policy. To model the stochasticity of the future, we introduce a conditional variational approach which minimises the divergence between the present distribution (what could happen given what we have seen) and the future distribution (what we observe actually happens). During inference, diverse futures are generated by sampling from the present distribution.
A Learnable ScatterNet: Locally Invariant Convolutional Layers
Mar 07, 2019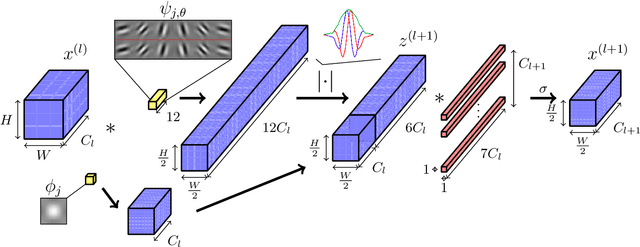
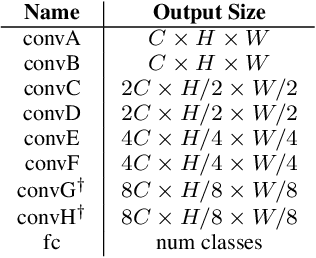
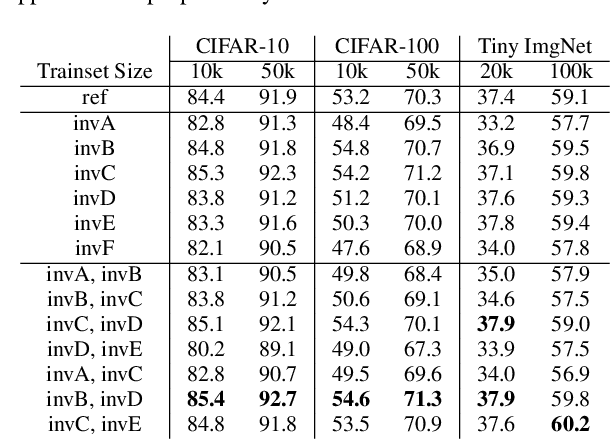
In this paper we explore tying together the ideas from Scattering Transforms and Convolutional Neural Networks (CNN) for Image Analysis by proposing a learnable ScatterNet. Previous attempts at tying them together in hybrid networks have tended to keep the two parts separate, with the ScatterNet forming a fixed front end and a CNN forming a learned backend. We instead look at adding learning between scattering orders, as well as adding learned layers before the ScatterNet. We do this by breaking down the scattering orders into single convolutional-like layers we call 'locally invariant' layers, and adding a learned mixing term to this layer. Our experiments show that these locally invariant layers can improve accuracy when added to either a CNN or a ScatterNet. We also discover some surprising results in that the ScatterNet may be best positioned after one or more layers of learning rather than at the front of a neural network.
A Framework for Implementing Machine Learning on Omics Data
Nov 26, 2018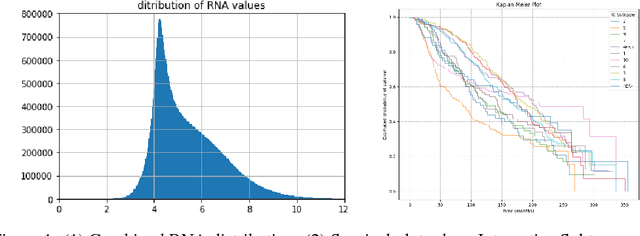
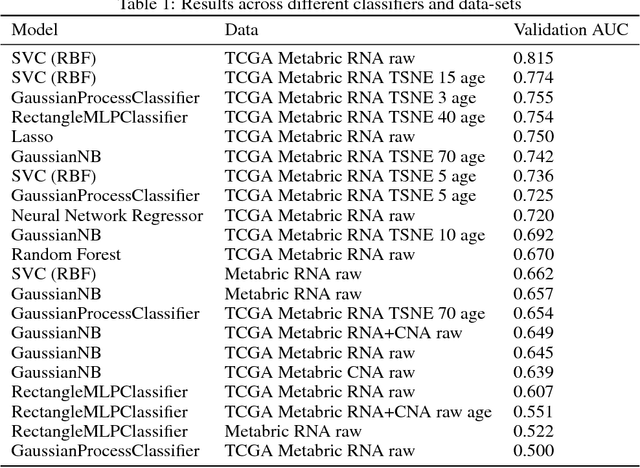
The potential benefits of applying machine learning methods to -omics data are becoming increasingly apparent, especially in clinical settings. However, the unique characteristics of these data are not always well suited to machine learning techniques. These data are often generated across different technologies in different labs, and frequently with high dimensionality. In this paper we present a framework for combining -omics data sets, and for handling high dimensional data, making -omics research more accessible to machine learning applications. We demonstrate the success of this framework through integration and analysis of multi-analyte data for a set of 3,533 breast cancers. We then use this data-set to predict breast cancer patient survival for individuals at risk of an impending event, with higher accuracy and lower variance than methods trained on individual data-sets. We hope that our pipelines for data-set generation and transformation will open up -omics data to machine learning researchers. We have made these freely available for noncommercial use at www.ccg.ai.
Deep Learning in the Wavelet Domain
Nov 14, 2018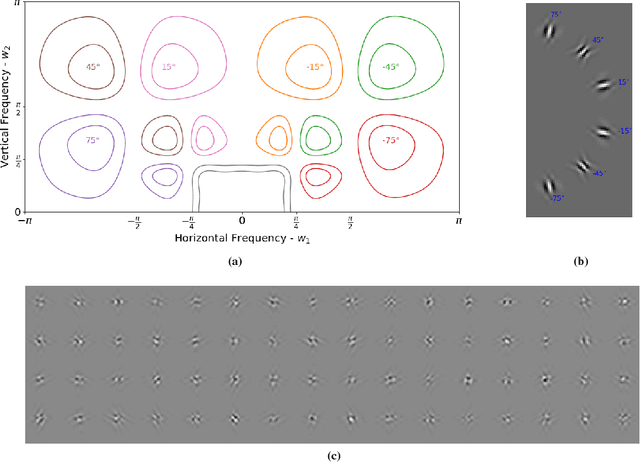
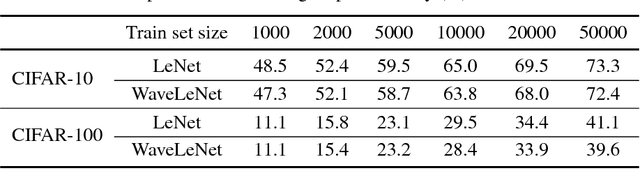
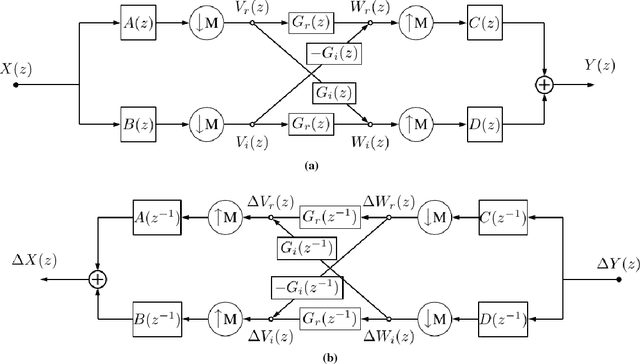
This paper examines the possibility of, and the possible advantages to learning the filters of convolutional neural networks (CNNs) for image analysis in the wavelet domain. We are stimulated by both Mallat's scattering transform and the idea of filtering in the Fourier domain. It is important to explore new spaces in which to learn, as these may provide inherent advantages that are not available in the pixel space. However, the scattering transform is limited by its inability to learn in between scattering orders, and any Fourier domain filtering is limited by the large number of filter parameters needed to get localized filters. Instead we consider filtering in the wavelet domain with learnable filters. The wavelet space allows us to have local, smooth filters with far fewer parameters, and learnability can give us flexibility. We present a novel layer which takes CNN activations into the wavelet space, learns parameters and returns to the pixel space. This allows it to be easily dropped in to any neural network without affecting the structure. As part of this work, we show how to pass gradients through a multirate system and give preliminary results.
Visualizing and Improving Scattering Networks
Sep 05, 2017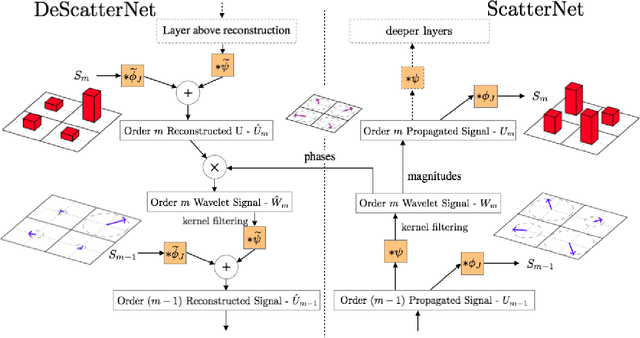

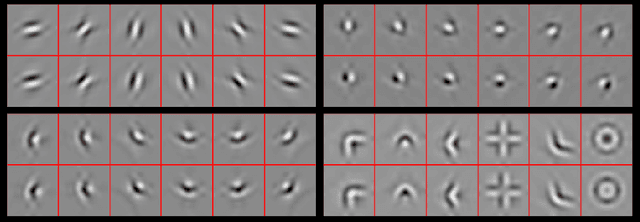
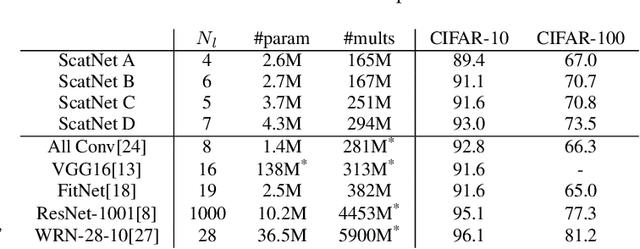
Scattering Transforms (or ScatterNets) introduced by Mallat are a promising start into creating a well-defined feature extractor to use for pattern recognition and image classification tasks. They are of particular interest due to their architectural similarity to Convolutional Neural Networks (CNNs), while requiring no parameter learning and still performing very well (particularly in constrained classification tasks). In this paper we visualize what the deeper layers of a ScatterNet are sensitive to using a 'DeScatterNet'. We show that the higher orders of ScatterNets are sensitive to complex, edge-like patterns (checker-boards and rippled edges). These complex patterns may be useful for texture classification, but are quite dissimilar from the patterns visualized in second and third layers of Convolutional Neural Networks (CNNs) - the current state of the art Image Classifiers. We propose that this may be the source of the current gaps in performance between ScatterNets and CNNs (83% vs 93% on CIFAR-10 for ScatterNet+SVM vs ResNet). We then use these visualization tools to propose possible enhancements to the ScatterNet design, which show they have the power to extract features more closely resembling CNNs, while still being well-defined and having the invariance properties fundamental to ScatterNets.