 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Learnable ScatterNet: Locally Invariant Convolutional Layers
Mar 07, 2019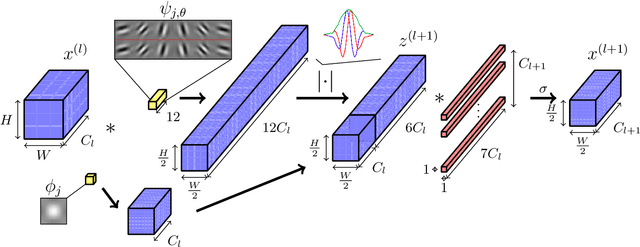
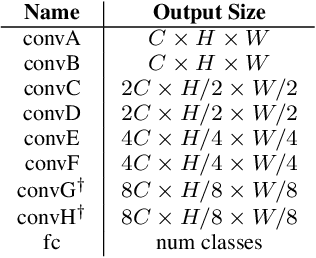
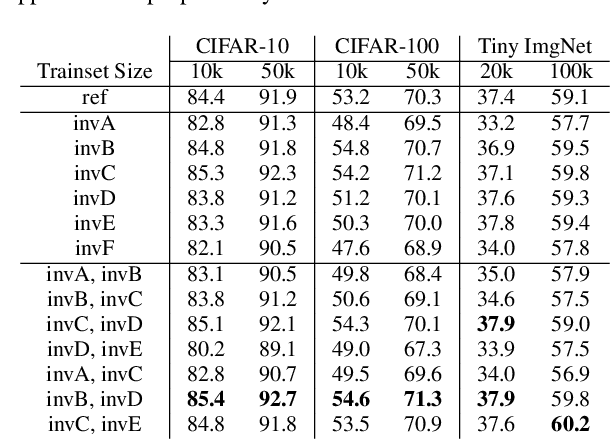
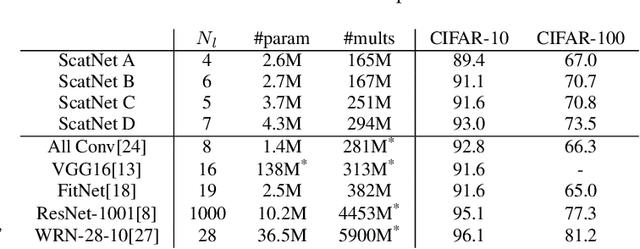
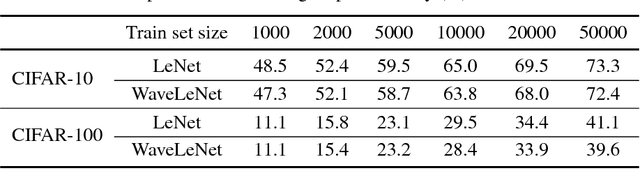
In this paper we explore tying together the ideas from Scattering Transforms and Convolutional Neural Networks (CNN) for Image Analysis by proposing a learnable ScatterNet. Previous attempts at tying them together in hybrid networks have tended to keep the two parts separate, with the ScatterNet forming a fixed front end and a CNN forming a learned backend. We instead look at adding learning between scattering orders, as well as adding learned layers before the ScatterNet. We do this by breaking down the scattering orders into single convolutional-like layers we call 'locally invariant' layers, and adding a learned mixing term to this layer. Our experiments show that these locally invariant layers can improve accuracy when added to either a CNN or a ScatterNet. We also discover some surprising results in that the ScatterNet may be best positioned after one or more layers of learning rather than at the front of a neural network.
Deep Learning in the Wavelet Domain
Nov 14, 2018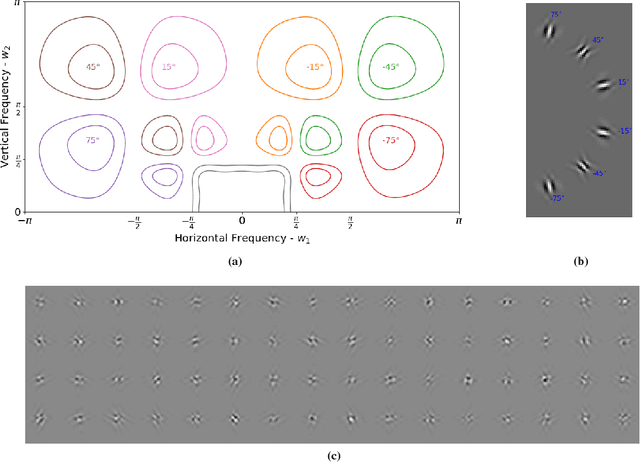
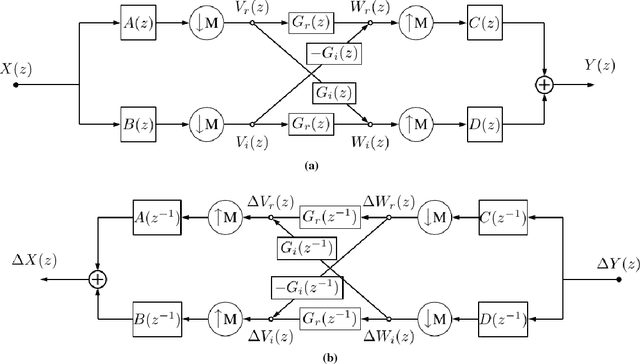
This paper examines the possibility of, and the possible advantages to learning the filters of convolutional neural networks (CNNs) for image analysis in the wavelet domain. We are stimulated by both Mallat's scattering transform and the idea of filtering in the Fourier domain. It is important to explore new spaces in which to learn, as these may provide inherent advantages that are not available in the pixel space. However, the scattering transform is limited by its inability to learn in between scattering orders, and any Fourier domain filtering is limited by the large number of filter parameters needed to get localized filters. Instead we consider filtering in the wavelet domain with learnable filters. The wavelet space allows us to have local, smooth filters with far fewer parameters, and learnability can give us flexibility. We present a novel layer which takes CNN activations into the wavelet space, learns parameters and returns to the pixel space. This allows it to be easily dropped in to any neural network without affecting the structure. As part of this work, we show how to pass gradients through a multirate system and give preliminary results.
Generative ScatterNet Hybrid Deep Learning (G-SHDL) Network with Structural Priors for Semantic Image Segmentation
Feb 13, 2018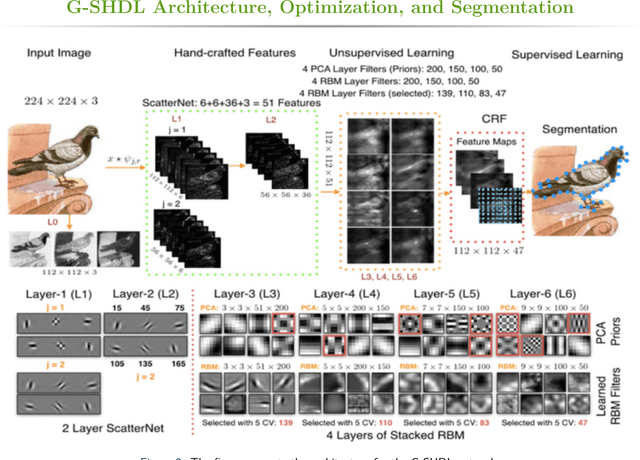
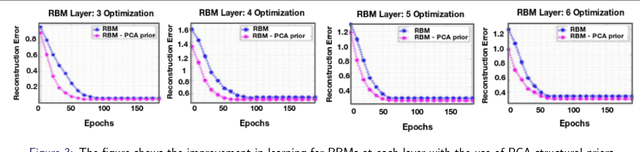
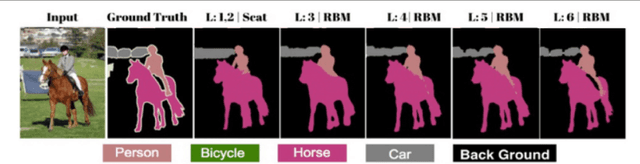
This paper proposes a generative ScatterNet hybrid deep learning (G-SHDL) network for semantic image segmentation. The proposed generative architecture is able to train rapidly from relatively small labeled datasets using the introduced structural priors. In addition, the number of filters in each layer of the architecture is optimized resulting in a computationally efficient architecture. The G-SHDL network produces state-of-the-art classification performance against unsupervised and semi-supervised learning on two image datasets. Advantages of the G-SHDL network over supervised methods are demonstrated with experiments performed on training datasets of reduced size.
Visualizing and Improving Scattering Networks
Sep 05, 2017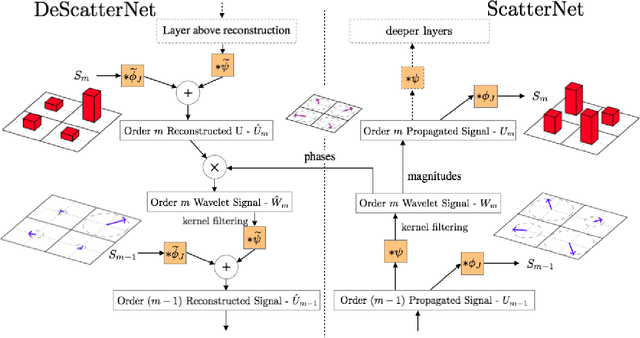

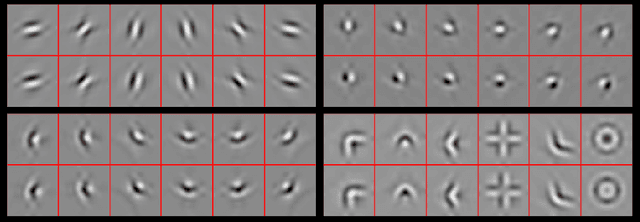
Scattering Transforms (or ScatterNets) introduced by Mallat are a promising start into creating a well-defined feature extractor to use for pattern recognition and image classification tasks. They are of particular interest due to their architectural similarity to Convolutional Neural Networks (CNNs), while requiring no parameter learning and still performing very well (particularly in constrained classification tasks). In this paper we visualize what the deeper layers of a ScatterNet are sensitive to using a 'DeScatterNet'. We show that the higher orders of ScatterNets are sensitive to complex, edge-like patterns (checker-boards and rippled edges). These complex patterns may be useful for texture classification, but are quite dissimilar from the patterns visualized in second and third layers of Convolutional Neural Networks (CNNs) - the current state of the art Image Classifiers. We propose that this may be the source of the current gaps in performance between ScatterNets and CNNs (83% vs 93% on CIFAR-10 for ScatterNet+SVM vs ResNet). We then use these visualization tools to propose possible enhancements to the ScatterNet design, which show they have the power to extract features more closely resembling CNNs, while still being well-defined and having the invariance properties fundamental to ScatterNets.
Efficient Convolutional Network Learning using Parametric Log based Dual-Tree Wavelet ScatterNet
Aug 30, 2017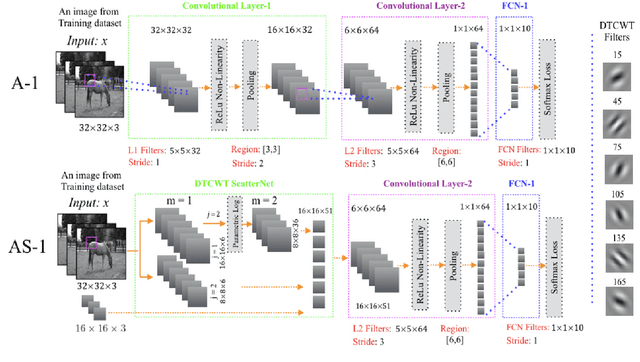
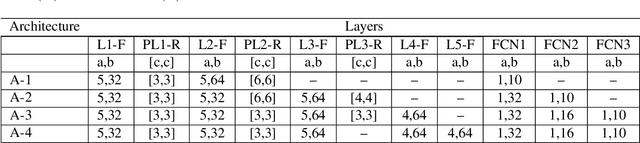
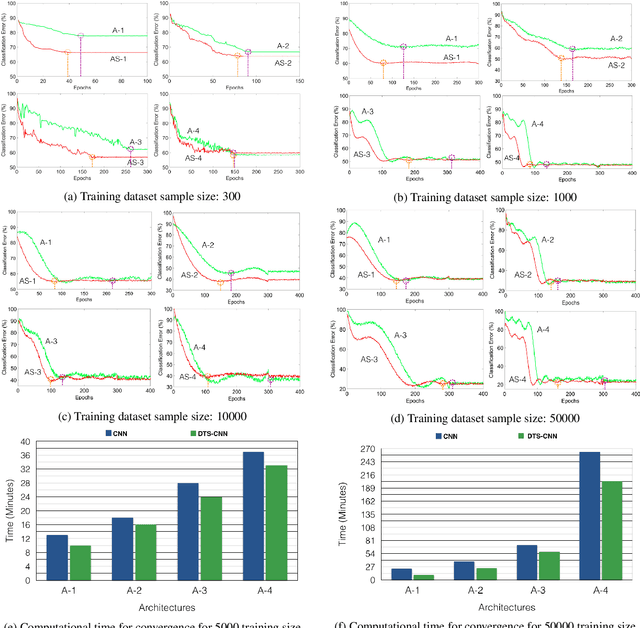
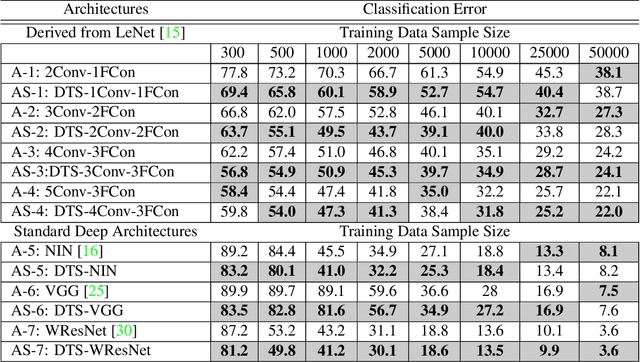
We propose a DTCWT ScatterNet Convolutional Neural Network (DTSCNN) formed by replacing the first few layers of a CNN network with a parametric log based DTCWT ScatterNet. The ScatterNet extracts edge based invariant representations that are used by the later layers of the CNN to learn high-level features. This improves the training of the network as the later layers can learn more complex patterns from the start of learning because the edge representations are already present. The efficient learning of the DTSCNN network is demonstrated on CIFAR-10 and Caltech-101 datasets. The generic nature of the ScatterNet front-end is shown by an equivalent performance to pre-trained CNN front-ends. A comparison with the state-of-the-art on CIFAR-10 and Caltech-101 datasets is also presented.
ScatterNet Hybrid Deep Learning (SHDL) Network For Object Classification
Aug 30, 2017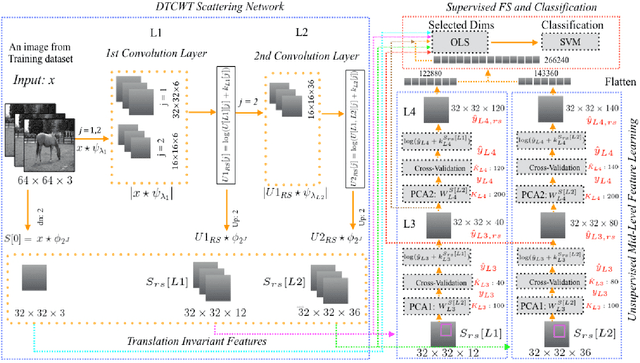
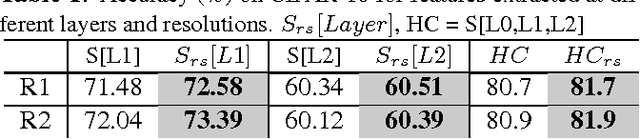
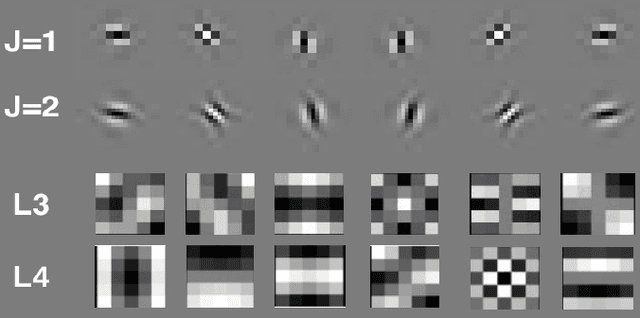
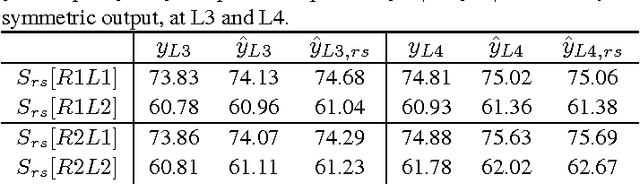
The paper proposes the ScatterNet Hybrid Deep Learning (SHDL) network that extracts invariant and discriminative image representations for object recognition. SHDL framework is constructed with a multi-layer ScatterNet front-end, an unsupervised learning middle, and a supervised learning back-end module. Each layer of the SHDL network is automatically designed as an explicit optimization problem leading to an optimal deep learning architecture with improved computational performance as compared to the more usual deep network architectures. SHDL network produces the state-of-the-art classification performance against unsupervised and semi-supervised learning (GANs) on two image datasets. Advantages of the SHDL network over supervised methods (NIN, VGG) are also demonstrated with experiments performed on training datasets of reduced size.