 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWayveScenes101: A Dataset and Benchmark for Novel View Synthesis in Autonomous Driving
Jul 11, 2024



We present WayveScenes101, a dataset designed to help the community advance the state of the art in novel view synthesis that focuses on challenging driving scenes containing many dynamic and deformable elements with changing geometry and texture. The dataset comprises 101 driving scenes across a wide range of environmental conditions and driving scenarios. The dataset is designed for benchmarking reconstructions on in-the-wild driving scenes, with many inherent challenges for scene reconstruction methods including image glare, rapid exposure changes, and highly dynamic scenes with significant occlusion. Along with the raw images, we include COLMAP-derived camera poses in standard data formats. We propose an evaluation protocol for evaluating models on held-out camera views that are off-axis from the training views, specifically testing the generalisation capabilities of methods. Finally, we provide detailed metadata for all scenes, including weather, time of day, and traffic conditions, to allow for a detailed model performance breakdown across scene characteristics. Dataset and code are available at https://github.com/wayveai/wayve_scenes.
AutoGraph: Predicting Lane Graphs from Traffic Observations
Jun 27, 2023



Lane graph estimation is a long-standing problem in the context of autonomous driving. Previous works aimed at solving this problem by relying on large-scale, hand-annotated lane graphs, introducing a data bottleneck for training models to solve this task. To overcome this limitation, we propose to use the motion patterns of traffic participants as lane graph annotations. In our AutoGraph approach, we employ a pre-trained object tracker to collect the tracklets of traffic participants such as vehicles and trucks. Based on the location of these tracklets, we predict the successor lane graph from an initial position using overhead RGB images only, not requiring any human supervision. In a subsequent stage, we show how the individual successor predictions can be aggregated into a consistent lane graph. We demonstrate the efficacy of our approach on the UrbanLaneGraph dataset and perform extensive quantitative and qualitative evaluations, indicating that AutoGraph is on par with models trained on hand-annotated graph data. Model and dataset will be made available at redacted-for-review.
Learning and Aggregating Lane Graphs for Urban Automated Driving
Feb 13, 2023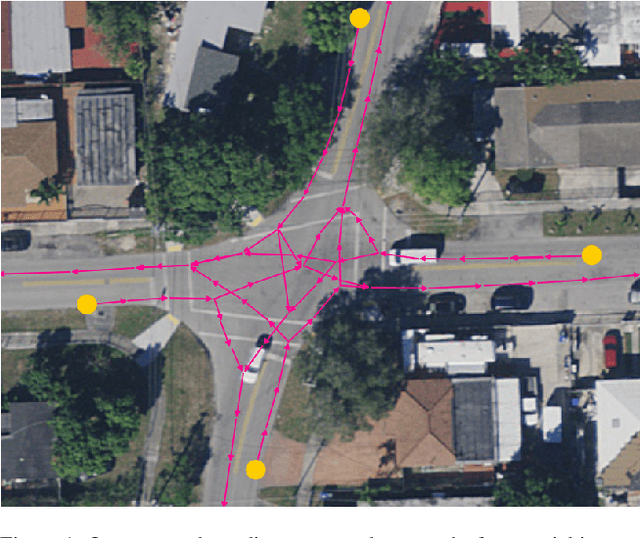
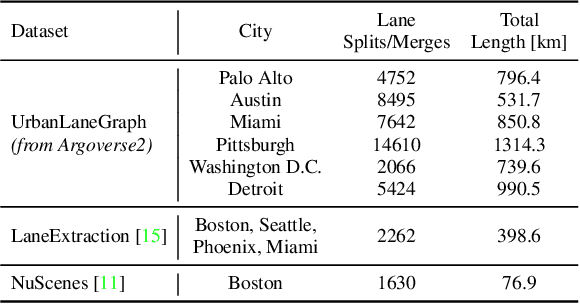


Lane graph estimation is an essential and highly challenging task in automated driving and HD map learning. Existing methods using either onboard or aerial imagery struggle with complex lane topologies, out-of-distribution scenarios, or significant occlusions in the image space. Moreover, merging overlapping lane graphs to obtain consistent large-scale graphs remains difficult. To overcome these challenges, we propose a novel bottom-up approach to lane graph estimation from aerial imagery that aggregates multiple overlapping graphs into a single consistent graph. Due to its modular design, our method allows us to address two complementary tasks: predicting ego-respective successor lane graphs from arbitrary vehicle positions using a graph neural network and aggregating these predictions into a consistent global lane graph. Extensive experiments on a large-scale lane graph dataset demonstrate that our approach yields highly accurate lane graphs, even in regions with severe occlusions. The presented approach to graph aggregation proves to eliminate inconsistent predictions while increasing the overall graph quality. We make our large-scale urban lane graph dataset and code publicly available at http://urbanlanegraph.cs.uni-freiburg.de.
TrackletMapper: Ground Surface Segmentation and Mapping from Traffic Participant Trajectories
Sep 16, 2022
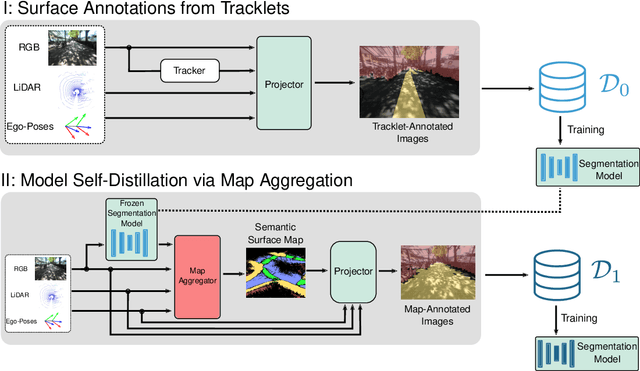
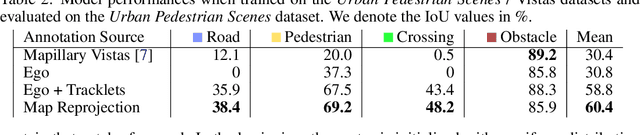

Robustly classifying ground infrastructure such as roads and street crossings is an essential task for mobile robots operating alongside pedestrians. While many semantic segmentation datasets are available for autonomous vehicles, models trained on such datasets exhibit a large domain gap when deployed on robots operating in pedestrian spaces. Manually annotating images recorded from pedestrian viewpoints is both expensive and time-consuming. To overcome this challenge, we propose TrackletMapper, a framework for annotating ground surface types such as sidewalks, roads, and street crossings from object tracklets without requiring human-annotated data. To this end, we project the robot ego-trajectory and the paths of other traffic participants into the ego-view camera images, creating sparse semantic annotations for multiple types of ground surfaces from which a ground segmentation model can be trained. We further show that the model can be self-distilled for additional performance benefits by aggregating a ground surface map and projecting it into the camera images, creating a denser set of training annotations compared to the sparse tracklet annotations. We qualitatively and quantitatively attest our findings on a novel large-scale dataset for mobile robots operating in pedestrian areas. Code and dataset will be made available at http://trackletmapper.cs.uni-freiburg.de.
Self-Supervised Moving Vehicle Detection from Audio-Visual Cues
Jan 30, 2022
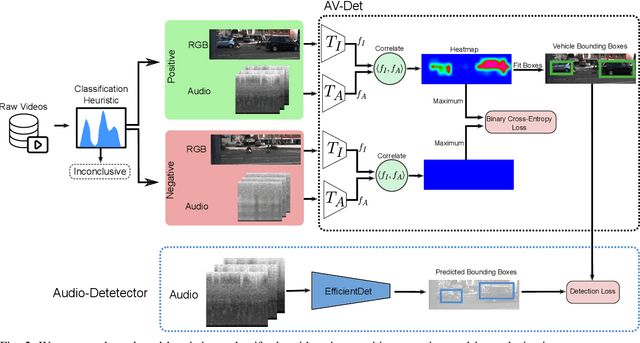

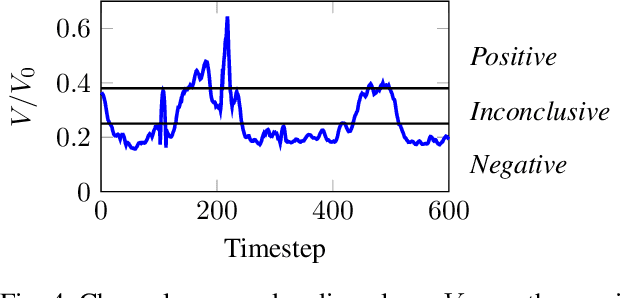
Robust detection of moving vehicles is a critical task for any autonomously operating outdoor robot or self-driving vehicle. Most modern approaches for solving this task rely on training image-based detectors using large-scale vehicle detection datasets such as nuScenes or the Waymo Open Dataset. Providing manual annotations is an expensive and laborious exercise that does not scale well in practice. To tackle this problem, we propose a self-supervised approach that leverages audio-visual cues to detect moving vehicles in videos. Our approach employs contrastive learning for localizing vehicles in images from corresponding pairs of images and recorded audio. In extensive experiments carried out with a real-world dataset, we demonstrate that our approach provides accurate detections of moving vehicles and does not require manual annotations. We furthermore show that our model can be used as a teacher to supervise an audio-only detection model. This student model is invariant to illumination changes and thus effectively bridges the domain gap inherent to models leveraging exclusively vision as the predominant modality.
Lane Graph Estimation for Scene Understanding in Urban Driving
May 01, 2021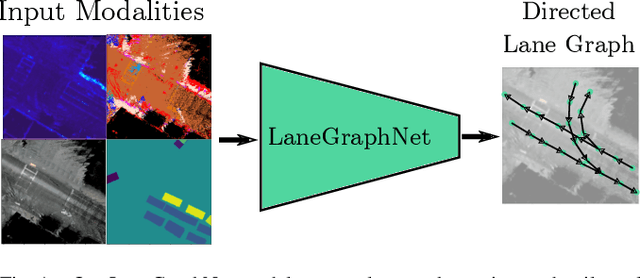
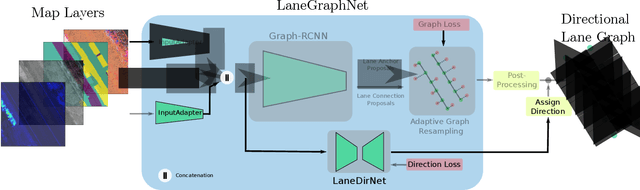


Lane-level scene annotations provide invaluable data in autonomous vehicles for trajectory planning in complex environments such as urban areas and cities. However, obtaining such data is time-consuming and expensive since lane annotations have to be annotated manually by humans and are as such hard to scale to large areas. In this work, we propose a novel approach for lane geometry estimation from bird's-eye-view images. We formulate the problem of lane shape and lane connections estimation as a graph estimation problem where lane anchor points are graph nodes and lane segments are graph edges. We train a graph estimation model on multimodal bird's-eye-view data processed from the popular NuScenes dataset and its map expansion pack. We furthermore estimate the direction of the lane connection for each lane segment with a separate model which results in a directed lane graph. We illustrate the performance of our LaneGraphNet model on the challenging NuScenes dataset and provide extensive qualitative and quantitative evaluation. Our model shows promising performance for most evaluated urban scenes and can serve as a step towards automated generation of HD lane annotations for autonomous driving.
HeatNet: Bridging the Day-Night Domain Gap in Semantic Segmentation with Thermal Images
Mar 10, 2020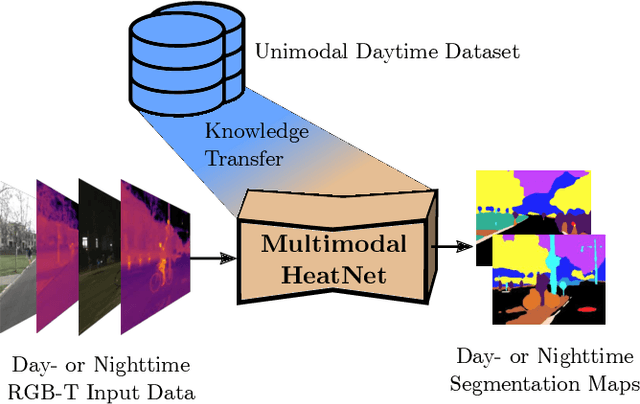
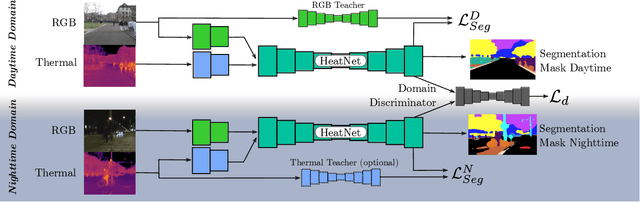


The majority of learning-based semantic segmentation methods are optimized for daytime scenarios and favorable lighting conditions. Real-world driving scenarios, however, entail adverse environmental conditions such as nighttime illumination or glare which remain a challenge for existing approaches. In this work, we propose a multimodal semantic segmentation model that can be applied during daytime and nighttime. To this end, besides RGB images, we leverage thermal images, making our network significantly more robust. We avoid the expensive annotation of nighttime images by leveraging an existing daytime RGB-dataset and propose a teacher-student training approach that transfers the dataset's knowledge to the nighttime domain. We further employ a domain adaptation method to align the learned feature spaces across the domains and propose a novel two-stage training scheme. Furthermore, due to a lack of thermal data for autonomous driving, we present a new dataset comprising over 20,000 time-synchronized and aligned RGB-thermal image pairs. In this context, we also present a novel target-less calibration method that allows for automatic robust extrinsic and intrinsic thermal camera calibration. Among others, we employ our new dataset to show state-of-the-art results for nighttime semantic segmentation.
Self-Supervised Visual Terrain Classification from Unsupervised Acoustic Feature Learning
Dec 06, 2019
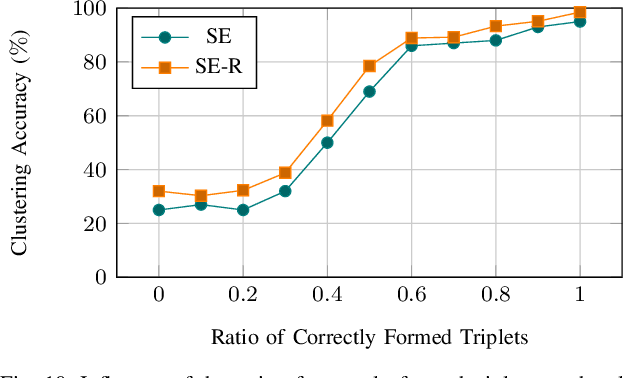

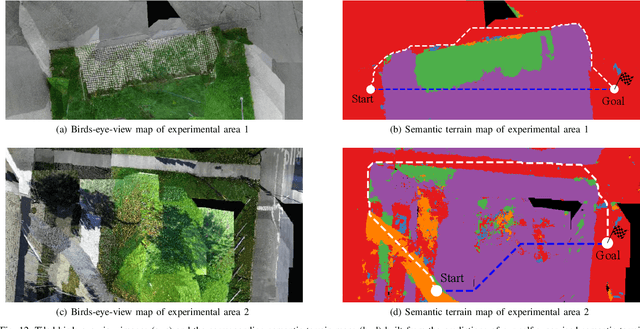
Mobile robots operating in unknown urban environments encounter a wide range of complex terrains to which they must adapt their planned trajectory for safe and efficient navigation. Most existing approaches utilize supervised learning to classify terrains from either an exteroceptive or a proprioceptive sensor modality. However, this requires a tremendous amount of manual labeling effort for each newly encountered terrain as well as for variations of terrains caused by changing environmental conditions. In this work, we propose a novel terrain classification framework leveraging an unsupervised proprioceptive classifier that learns from vehicle-terrain interaction sounds to self-supervise an exteroceptive classifier for pixel-wise semantic segmentation of images. To this end, we first learn a discriminative embedding space for vehicle-terrain interaction sounds from triplets of audio clips formed using visual features of the corresponding terrain patches and cluster the resulting embeddings. We subsequently use these clusters to label the visual terrain patches by projecting the traversed tracks of the robot into the camera images. Finally, we use the sparsely labeled images to train our semantic segmentation network in a weakly supervised manner. We present extensive quantitative and qualitative results that demonstrate that our proprioceptive terrain classifier exceeds the state-of-the-art among unsupervised methods and our self-supervised exteroceptive semantic segmentation model achieves a comparable performance to supervised learning with manually labeled data.