 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Deep Dynamics Models for Autonomous Vehicles with Multimodal Latent Mapping of Surfaces
Mar 21, 2023



The safe deployment of autonomous vehicles relies on their ability to effectively react to environmental changes. This can require maneuvering on varying surfaces which is still a difficult problem, especially for slippery terrains. To address this issue we propose a new approach that learns a surface-aware dynamics model by conditioning it on a latent variable vector storing surface information about the current location. A latent mapper is trained to update these latent variables during inference from multiple modalities on every traversal of the corresponding locations and stores them in a map. By training everything end-to-end with the loss of the dynamics model, we enforce the latent mapper to learn an update rule for the latent map that is useful for the subsequent dynamics model. We implement and evaluate our approach on a real miniature electric car. The results show that the latent map is updated to allow more accurate predictions of the dynamics model compared to a model without this information. We further show that by using this model, the driving performance can be improved on varying and challenging surfaces.
USegScene: Unsupervised Learning of Depth, Optical Flow and Ego-Motion with Semantic Guidance and Coupled Networks
Jul 15, 2022
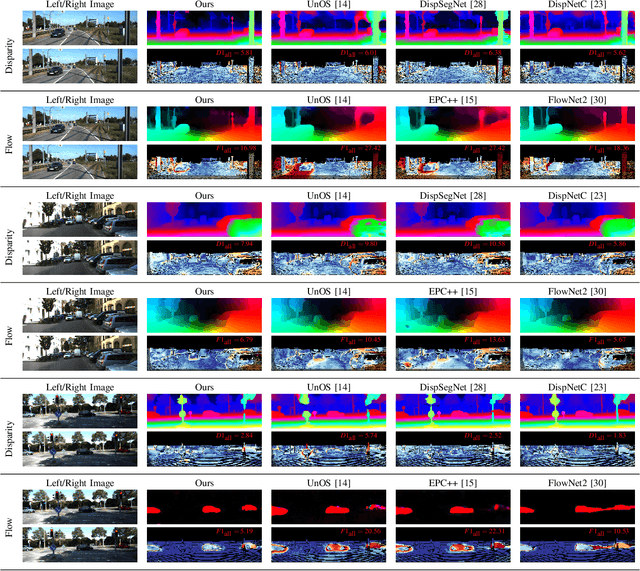
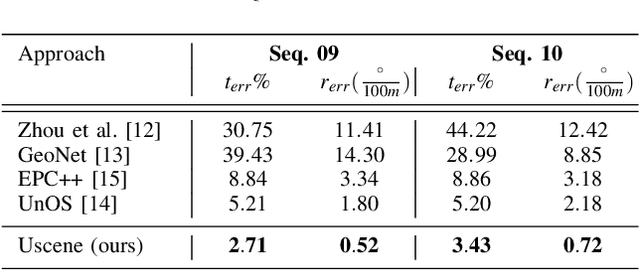
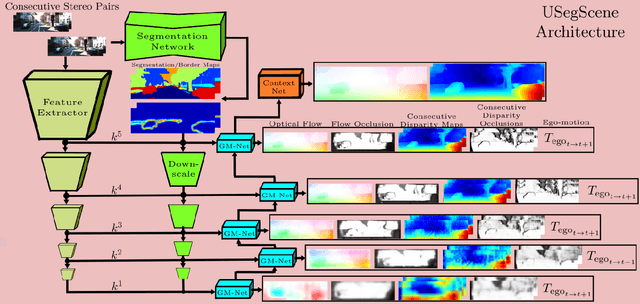
In this paper we propose USegScene, a framework for semantically guided unsupervised learning of depth, optical flow and ego-motion estimation for stereo camera images using convolutional neural networks. Our framework leverages semantic information for improved regularization of depth and optical flow maps, multimodal fusion and occlusion filling considering dynamic rigid object motions as independent SE(3) transformations. Furthermore, complementary to pure photo-metric matching, we propose matching of semantic features, pixel-wise classes and object instance borders between the consecutive images. In contrast to previous methods, we propose a network architecture that jointly predicts all outputs using shared encoders and allows passing information across the task-domains, e.g., the prediction of optical flow can benefit from the prediction of the depth. Furthermore, we explicitly learn the depth and optical flow occlusion maps inside the network, which are leveraged in order to improve the predictions in therespective regions. We present results on the popular KITTI dataset and show that our approach outperforms other methods by a large margin.
Lane Graph Estimation for Scene Understanding in Urban Driving
May 01, 2021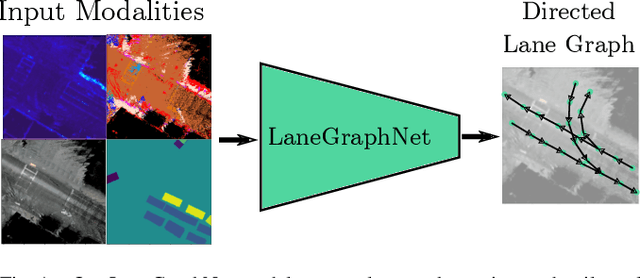
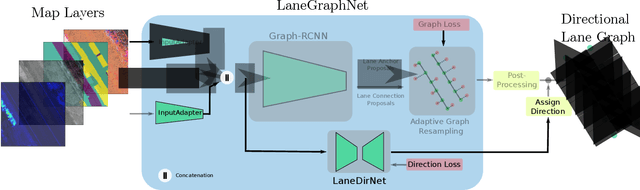


Lane-level scene annotations provide invaluable data in autonomous vehicles for trajectory planning in complex environments such as urban areas and cities. However, obtaining such data is time-consuming and expensive since lane annotations have to be annotated manually by humans and are as such hard to scale to large areas. In this work, we propose a novel approach for lane geometry estimation from bird's-eye-view images. We formulate the problem of lane shape and lane connections estimation as a graph estimation problem where lane anchor points are graph nodes and lane segments are graph edges. We train a graph estimation model on multimodal bird's-eye-view data processed from the popular NuScenes dataset and its map expansion pack. We furthermore estimate the direction of the lane connection for each lane segment with a separate model which results in a directed lane graph. We illustrate the performance of our LaneGraphNet model on the challenging NuScenes dataset and provide extensive qualitative and quantitative evaluation. Our model shows promising performance for most evaluated urban scenes and can serve as a step towards automated generation of HD lane annotations for autonomous driving.
HeatNet: Bridging the Day-Night Domain Gap in Semantic Segmentation with Thermal Images
Mar 10, 2020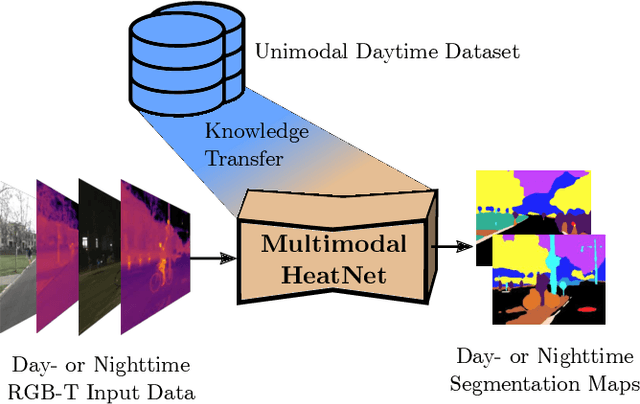
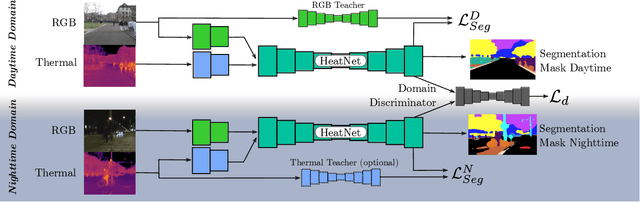


The majority of learning-based semantic segmentation methods are optimized for daytime scenarios and favorable lighting conditions. Real-world driving scenarios, however, entail adverse environmental conditions such as nighttime illumination or glare which remain a challenge for existing approaches. In this work, we propose a multimodal semantic segmentation model that can be applied during daytime and nighttime. To this end, besides RGB images, we leverage thermal images, making our network significantly more robust. We avoid the expensive annotation of nighttime images by leveraging an existing daytime RGB-dataset and propose a teacher-student training approach that transfers the dataset's knowledge to the nighttime domain. We further employ a domain adaptation method to align the learned feature spaces across the domains and propose a novel two-stage training scheme. Furthermore, due to a lack of thermal data for autonomous driving, we present a new dataset comprising over 20,000 time-synchronized and aligned RGB-thermal image pairs. In this context, we also present a novel target-less calibration method that allows for automatic robust extrinsic and intrinsic thermal camera calibration. Among others, we employ our new dataset to show state-of-the-art results for nighttime semantic segmentation.
Learning Object Placements For Relational Instructions by Hallucinating Scene Representations
Feb 21, 2020
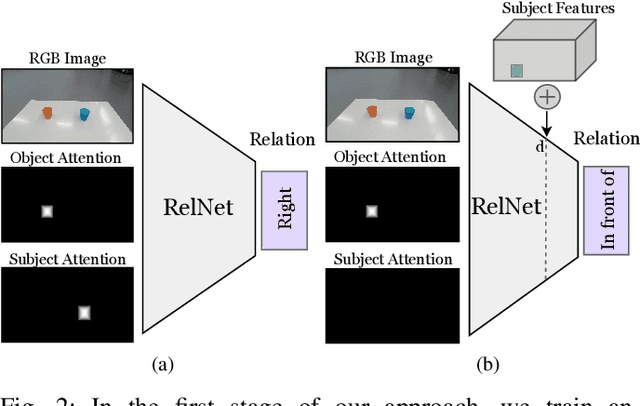
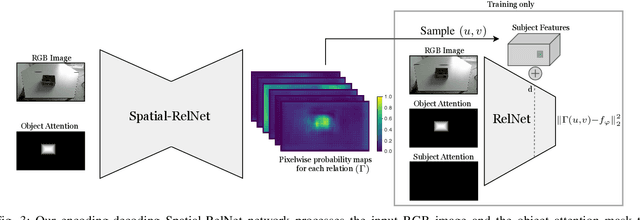

Robots coexisting with humans in their environment and performing services for them need the ability to interact with them. One particular requirement for such robots is that they are able to understand spatial relations and can place objects in accordance with the spatial relations expressed by their user. In this work, we present a convolutional neural network for estimating pixelwise object placement probabilities for a set of spatial relations from a single input image. During training, our network receives the learning signal by classifying hallucinated high-level scene representations as an auxiliary task. Unlike previous approaches, our method does not require ground truth data for the pixelwise relational probabilities or 3D models of the objects, which significantly expands the applicability in practical applications. Our results obtained using real-world data and human-robot experiments demonstrate the effectiveness of our method in reasoning about the best way to place objects to reproduce a spatial relation. Videos of our experiments can be found at https://youtu.be/zaZkHTWFMKM
Long-Term Urban Vehicle Localization Using Pole Landmarks Extracted from 3-D Lidar Scans
Oct 23, 2019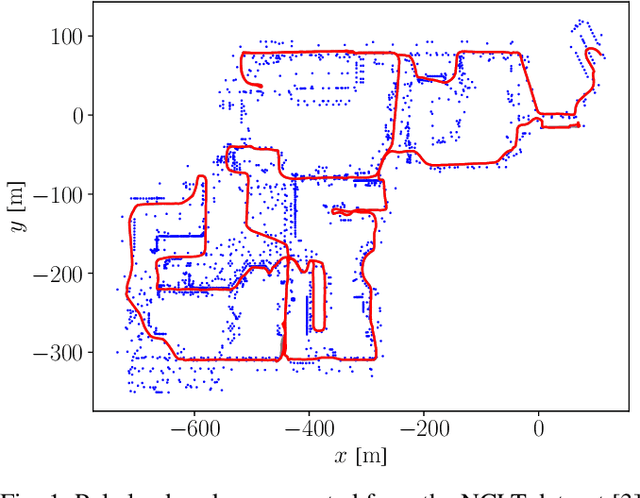
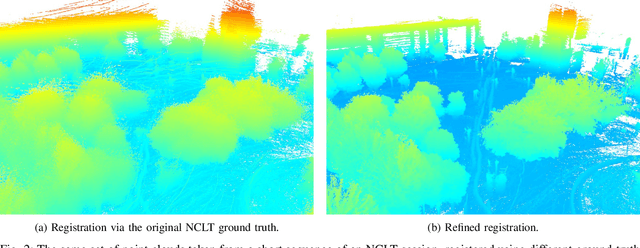
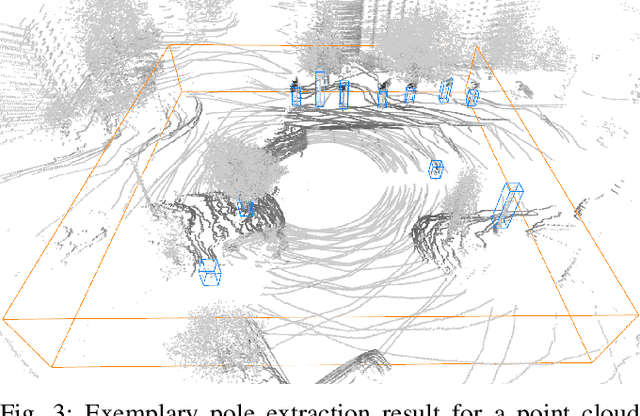
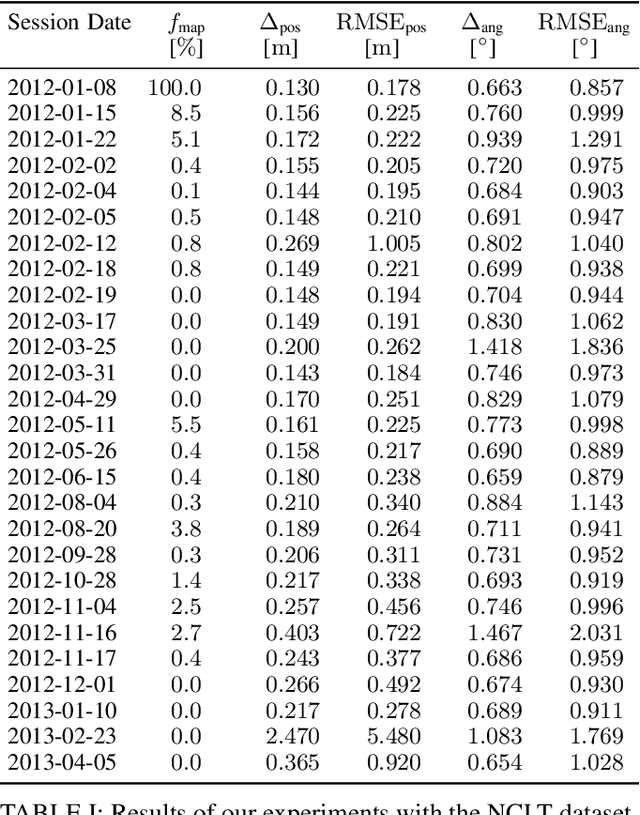
Due to their ubiquity and long-term stability, pole-like objects are well suited to serve as landmarks for vehicle localization in urban environments. In this work, we present a complete mapping and long-term localization system based on pole landmarks extracted from 3-D lidar data. Our approach features a novel pole detector, a mapping module, and an online localization module, each of which are described in detail, and for which we provide an open-source implementation at www.github.com/acschaefer/polex. In extensive experiments, we demonstrate that our method improves on the state of the art with respect to long-term reliability and accuracy: First, we prove reliability by tasking the system with localizing a mobile robot over the course of 15~months in an urban area based on an initial map, confronting it with constantly varying routes, differing weather conditions, seasonal changes, and construction sites. Second, we show that the proposed approach clearly outperforms a recently published method in terms of accuracy.
* 9 pages
A Maximum Likelihood Approach to Extract Finite Planes from 3-D Laser Scans
Oct 23, 2019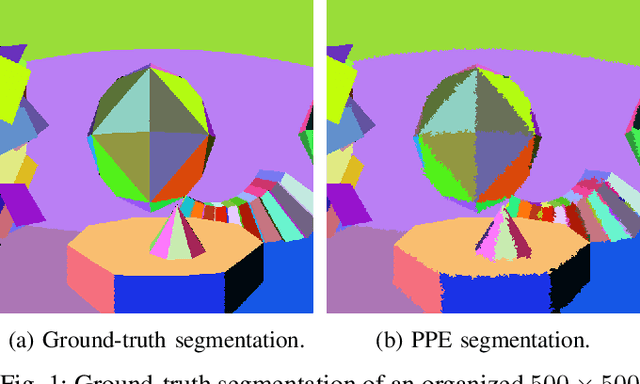

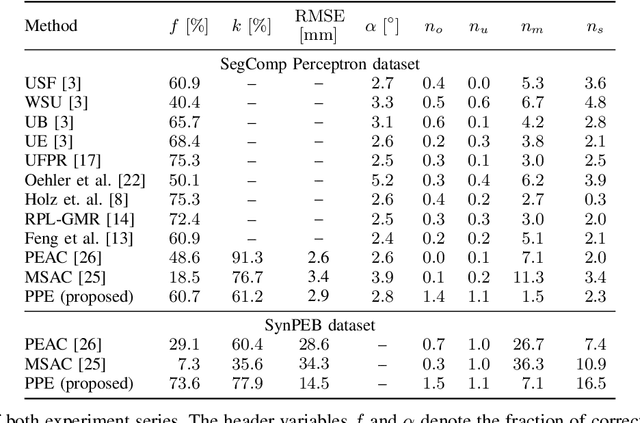
Whether it is object detection, model reconstruction, laser odometry, or point cloud registration: Plane extraction is a vital component of many robotic systems. In this paper, we propose a strictly probabilistic method to detect finite planes in organized 3-D laser range scans. An agglomerative hierarchical clustering technique, our algorithm builds planes from bottom up, always extending a plane by the point that decreases the measurement likelihood of the scan the least. In contrast to most related methods, which rely on heuristics like orthogonal point-to-plane distance, we leverage the ray path information to compute the measurement likelihood. We evaluate our approach not only on the popular SegComp benchmark, but also provide a challenging synthetic dataset that overcomes SegComp's deficiencies. Both our implementation and the suggested dataset are available at www.github.com/acschaefer/ppe.
From Plants to Landmarks: Time-invariant Plant Localization that uses Deep Pose Regression in Agricultural Fields
Sep 14, 2017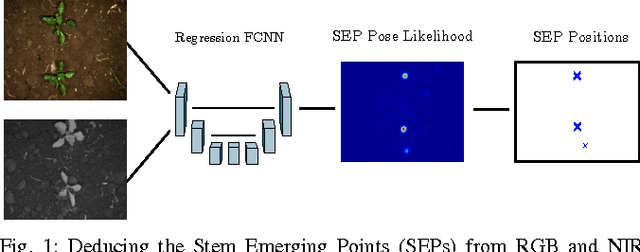



Agricultural robots are expected to increase yields in a sustainable way and automate precision tasks, such as weeding and plant monitoring. At the same time, they move in a continuously changing, semi-structured field environment, in which features can hardly be found and reproduced at a later time. Challenges for Lidar and visual detection systems stem from the fact that plants can be very small, overlapping and have a steadily changing appearance. Therefore, a popular way to localize vehicles with high accuracy is based on ex- pensive global navigation satellite systems and not on natural landmarks. The contribution of this work is a novel image- based plant localization technique that uses the time-invariant stem emerging point as a reference. Our approach is based on a fully convolutional neural network that learns landmark localization from RGB and NIR image input in an end-to-end manner. The network performs pose regression to generate a plant location likelihood map. Our approach allows us to cope with visual variances of plants both for different species and different growth stages. We achieve high localization accuracies as shown in detailed evaluations of a sugar beet cultivation phase. In experiments with our BoniRob we demonstrate that detections can be robustly reproduced with centimeter accuracy.