 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-supervised Transfer Learning for Instance Segmentation through Physical Interaction
May 19, 2020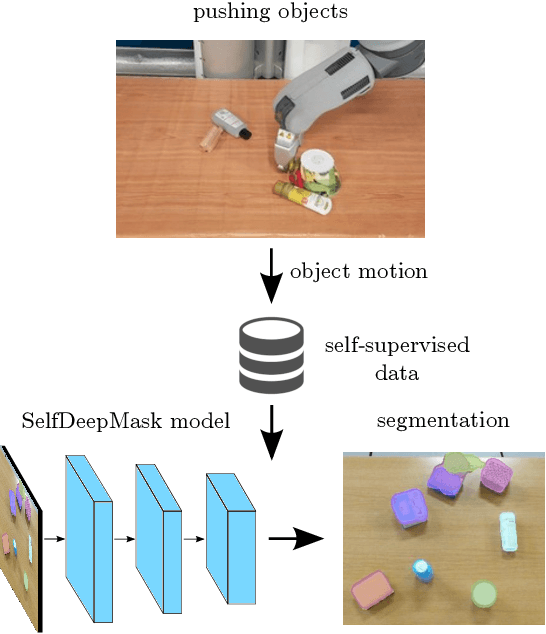


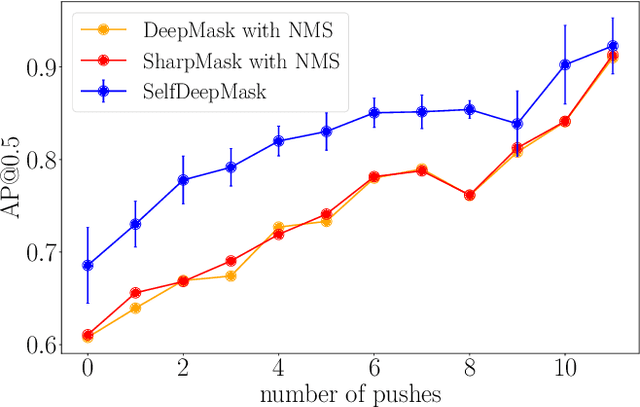
Instance segmentation of unknown objects from images is regarded as relevant for several robot skills including grasping, tracking and object sorting. Recent results in computer vision have shown that large hand-labeled datasets enable high segmentation performance. To overcome the time-consuming process of manually labeling data for new environments, we present a transfer learning approach for robots that learn to segment objects by interacting with their environment in a self-supervised manner. Our robot pushes unknown objects on a table and uses information from optical flow to create training labels in the form of object masks. To achieve this, we fine-tune an existing DeepMask network for instance segmentation on the self-labeled training data acquired by the robot. We evaluate our trained network (SelfDeepMask) on a set of real images showing challenging and cluttered scenes with novel objects. Here, SelfDeepMask outperforms the DeepMask network trained on the COCO dataset by 9.5% in average precision. Furthermore, we combine our approach with recent approaches for training with noisy labels in order to better cope with induced label noise.
Adaptive Curriculum Generation from Demonstrations for Sim-to-Real Visuomotor Control
Oct 31, 2019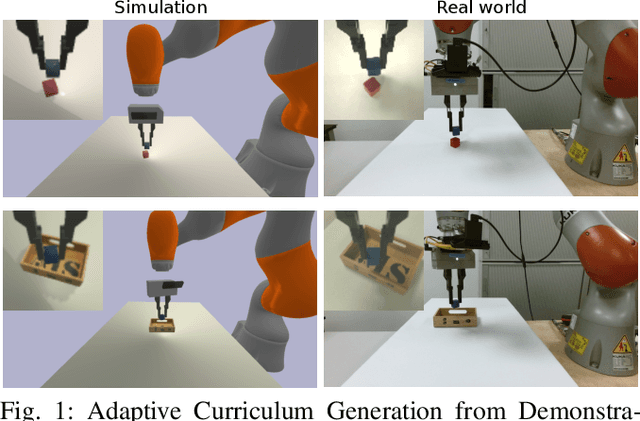
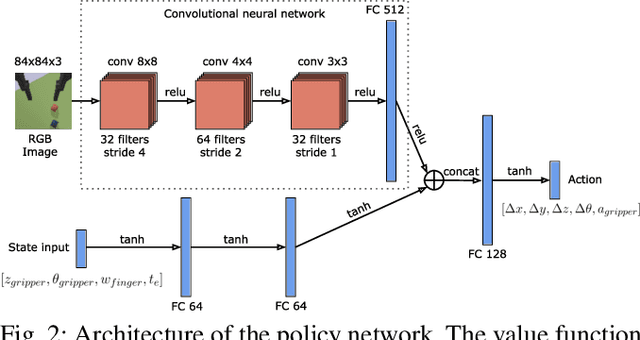
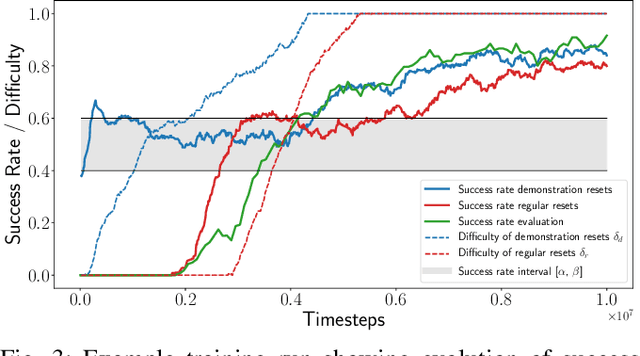
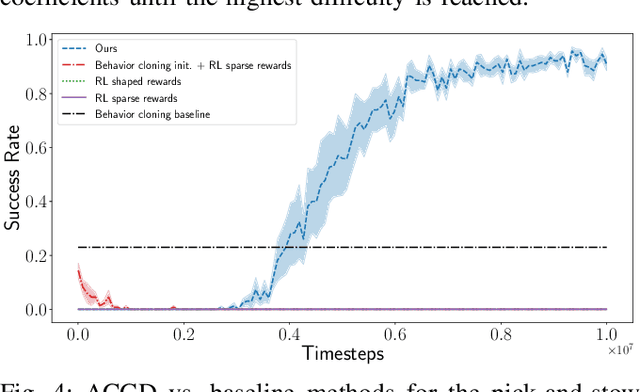
We propose Adaptive Curriculum Generation from Demonstrations (ACGD) for reinforcement learning in the presence of sparse rewards. Rather than designing shaped reward functions, ACGD adaptively sets the appropriate task difficulty for the learner by controlling where to sample from the demonstration trajectories and which set of simulation parameters to use. We show that training vision-based control policies in simulation while gradually increasing the difficulty of the task via ACGD improves the policy transfer to the real world. The degree of domain randomization is also gradually increased through the task difficulty. We demonstrate zero-shot transfer for two real-world manipulation tasks: pick-and-stow and block stacking. A video showing the results can be found at https://lmb.informatik.uni-freiburg.de/projects/curriculum/
Optimization Beyond the Convolution: Generalizing Spatial Relations with End-to-End Metric Learning
Mar 24, 2018
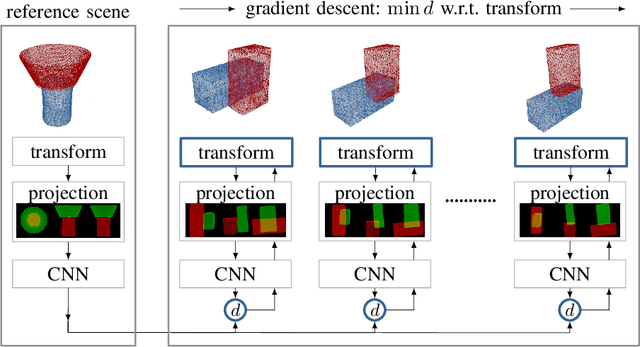
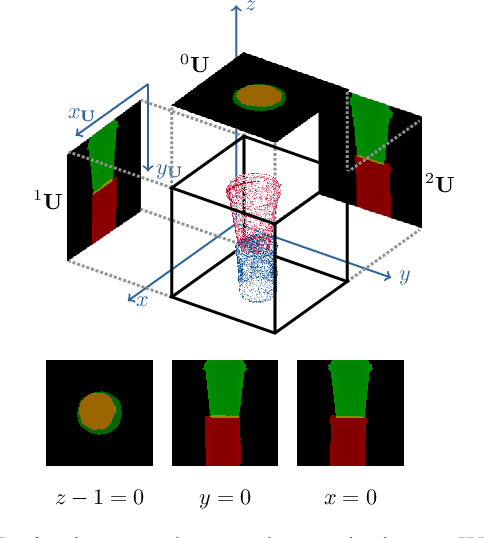
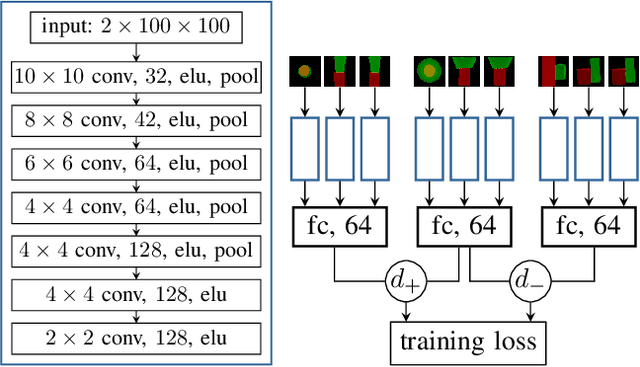
To operate intelligently in domestic environments, robots require the ability to understand arbitrary spatial relations between objects and to generalize them to objects of varying sizes and shapes. In this work, we present a novel end-to-end approach to generalize spatial relations based on distance metric learning. We train a neural network to transform 3D point clouds of objects to a metric space that captures the similarity of the depicted spatial relations, using only geometric models of the objects. Our approach employs gradient-based optimization to compute object poses in order to imitate an arbitrary target relation by reducing the distance to it under the learned metric. Our results based on simulated and real-world experiments show that the proposed method enables robots to generalize spatial relations to unknown objects over a continuous spectrum.
Learning to Singulate Objects using a Push Proposal Network
Feb 05, 2018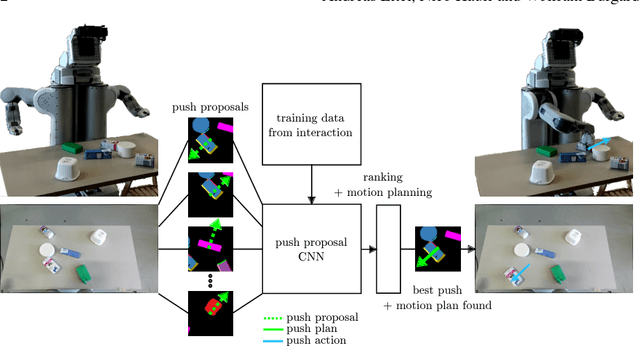



Learning to act in unstructured environments, such as cluttered piles of objects, poses a substantial challenge for manipulation robots. We present a novel neural network-based approach that separates unknown objects in clutter by selecting favourable push actions. Our network is trained from data collected through autonomous interaction of a PR2 robot with randomly organized tabletop scenes. The model is designed to propose meaningful push actions based on over-segmented RGB-D images. We evaluate our approach by singulating up to 8 unknown objects in clutter. We demonstrate that our method enables the robot to perform the task with a high success rate and a low number of required push actions. Our results based on real-world experiments show that our network is able to generalize to novel objects of various sizes and shapes, as well as to arbitrary object configurations. Videos of our experiments can be viewed at http://robotpush.cs.uni-freiburg.de
From Plants to Landmarks: Time-invariant Plant Localization that uses Deep Pose Regression in Agricultural Fields
Sep 14, 2017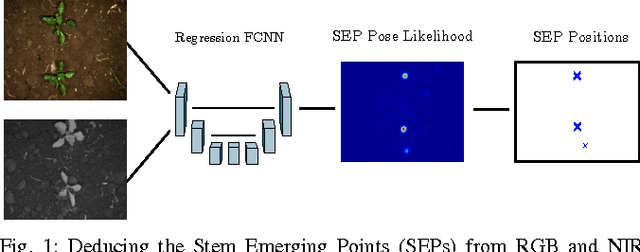



Agricultural robots are expected to increase yields in a sustainable way and automate precision tasks, such as weeding and plant monitoring. At the same time, they move in a continuously changing, semi-structured field environment, in which features can hardly be found and reproduced at a later time. Challenges for Lidar and visual detection systems stem from the fact that plants can be very small, overlapping and have a steadily changing appearance. Therefore, a popular way to localize vehicles with high accuracy is based on ex- pensive global navigation satellite systems and not on natural landmarks. The contribution of this work is a novel image- based plant localization technique that uses the time-invariant stem emerging point as a reference. Our approach is based on a fully convolutional neural network that learns landmark localization from RGB and NIR image input in an end-to-end manner. The network performs pose regression to generate a plant location likelihood map. Our approach allows us to cope with visual variances of plants both for different species and different growth stages. We achieve high localization accuracies as shown in detailed evaluations of a sugar beet cultivation phase. In experiments with our BoniRob we demonstrate that detections can be robustly reproduced with centimeter accuracy.
Deep Detection of People and their Mobility Aids for a Hospital Robot
Aug 02, 2017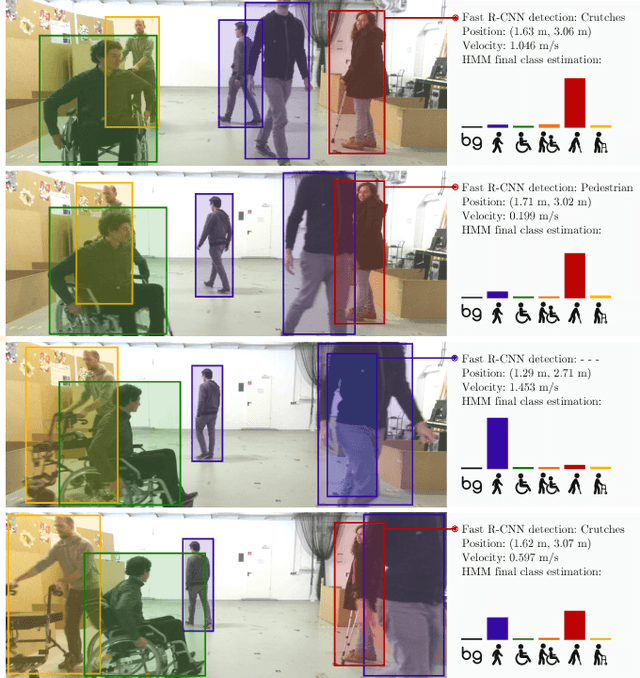
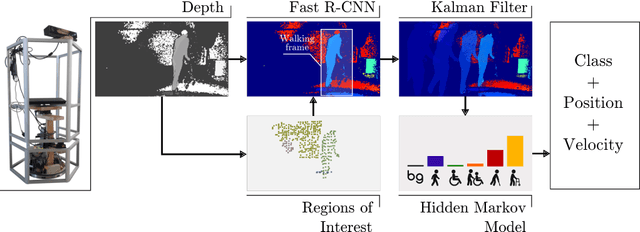

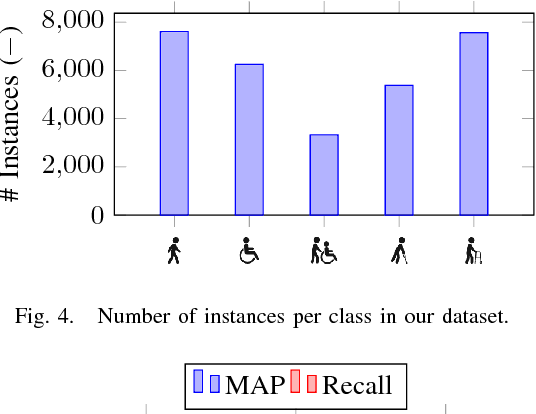
Robots operating in populated environments encounter many different types of people, some of whom might have an advanced need for cautious interaction, because of physical impairments or their advanced age. Robots therefore need to recognize such advanced demands to provide appropriate assistance, guidance or other forms of support. In this paper, we propose a depth-based perception pipeline that estimates the position and velocity of people in the environment and categorizes them according to the mobility aids they use: pedestrian, person in wheelchair, person in a wheelchair with a person pushing them, person with crutches and person using a walker. We present a fast region proposal method that feeds a Region-based Convolutional Network (Fast R-CNN). With this, we speed up the object detection process by a factor of seven compared to a dense sliding window approach. We furthermore propose a probabilistic position, velocity and class estimator to smooth the CNN's detections and account for occlusions and misclassifications. In addition, we introduce a new hospital dataset with over 17,000 annotated RGB-D images. Extensive experiments confirm that our pipeline successfully keeps track of people and their mobility aids, even in challenging situations with multiple people from different categories and frequent occlusions. Videos of our experiments and the dataset are available at http://www2.informatik.uni-freiburg.de/~kollmitz/MobilityAids
Choosing Smartly: Adaptive Multimodal Fusion for Object Detection in Changing Environments
Jul 18, 2017
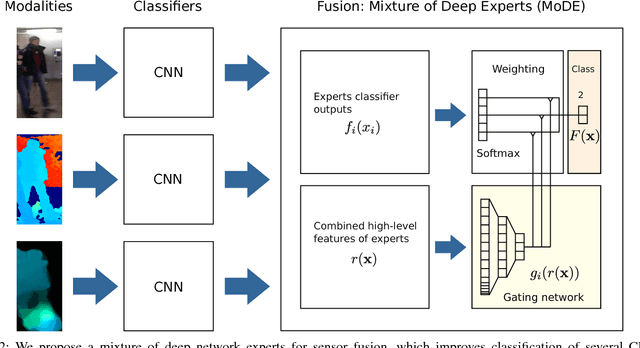
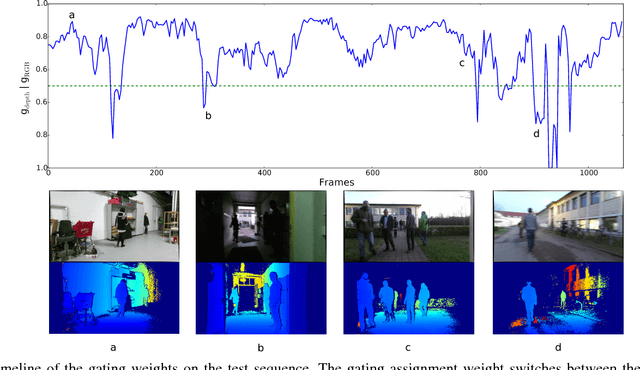
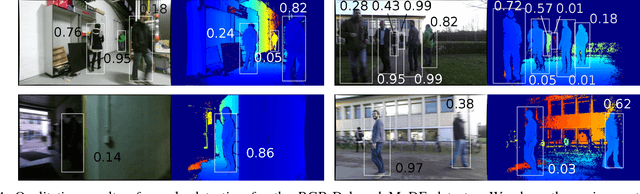
Object detection is an essential task for autonomous robots operating in dynamic and changing environments. A robot should be able to detect objects in the presence of sensor noise that can be induced by changing lighting conditions for cameras and false depth readings for range sensors, especially RGB-D cameras. To tackle these challenges, we propose a novel adaptive fusion approach for object detection that learns weighting the predictions of different sensor modalities in an online manner. Our approach is based on a mixture of convolutional neural network (CNN) experts and incorporates multiple modalities including appearance, depth and motion. We test our method in extensive robot experiments, in which we detect people in a combined indoor and outdoor scenario from RGB-D data, and we demonstrate that our method can adapt to harsh lighting changes and severe camera motion blur. Furthermore, we present a new RGB-D dataset for people detection in mixed in- and outdoor environments, recorded with a mobile robot.
The Freiburg Groceries Dataset
Nov 17, 2016
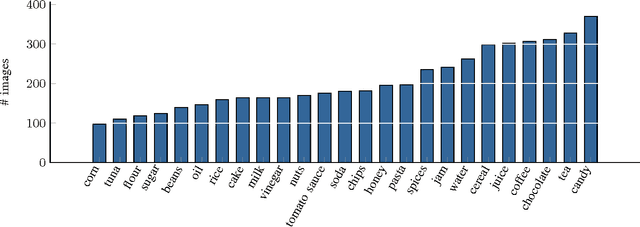


With the increasing performance of machine learning techniques in the last few years, the computer vision and robotics communities have created a large number of datasets for benchmarking object recognition tasks. These datasets cover a large spectrum of natural images and object categories, making them not only useful as a testbed for comparing machine learning approaches, but also a great resource for bootstrapping different domain-specific perception and robotic systems. One such domain is domestic environments, where an autonomous robot has to recognize a large variety of everyday objects such as groceries. This is a challenging task due to the large variety of objects and products, and where there is great need for real-world training data that goes beyond product images available online. In this paper, we address this issue and present a dataset consisting of 5,000 images covering 25 different classes of groceries, with at least 97 images per class. We collected all images from real-world settings at different stores and apartments. In contrast to existing groceries datasets, our dataset includes a large variety of perspectives, lighting conditions, and degrees of clutter. Overall, our images contain thousands of different object instances. It is our hope that machine learning and robotics researchers find this dataset of use for training, testing, and bootstrapping their approaches. As a baseline classifier to facilitate comparison, we re-trained the CaffeNet architecture (an adaptation of the well-known AlexNet) on our dataset and achieved a mean accuracy of 78.9%. We release this trained model along with the code and data splits we used in our experiments.
Multimodal Deep Learning for Robust RGB-D Object Recognition
Aug 18, 2015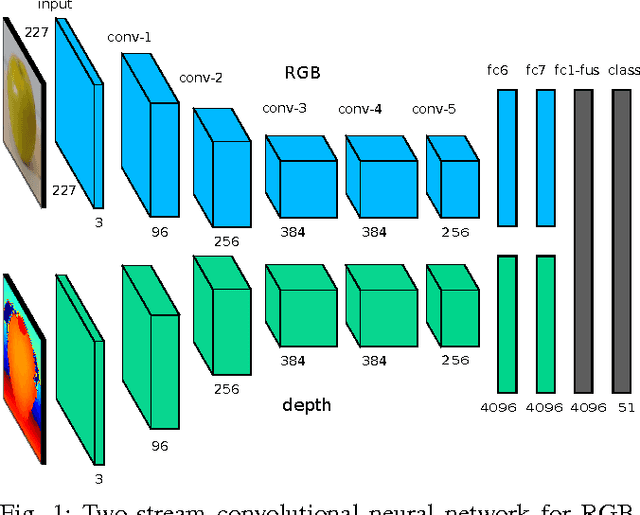



Robust object recognition is a crucial ingredient of many, if not all, real-world robotics applications. This paper leverages recent progress on Convolutional Neural Networks (CNNs) and proposes a novel RGB-D architecture for object recognition. Our architecture is composed of two separate CNN processing streams - one for each modality - which are consecutively combined with a late fusion network. We focus on learning with imperfect sensor data, a typical problem in real-world robotics tasks. For accurate learning, we introduce a multi-stage training methodology and two crucial ingredients for handling depth data with CNNs. The first, an effective encoding of depth information for CNNs that enables learning without the need for large depth datasets. The second, a data augmentation scheme for robust learning with depth images by corrupting them with realistic noise patterns. We present state-of-the-art results on the RGB-D object dataset and show recognition in challenging RGB-D real-world noisy settings.